






















































Regularization
In this section, we will review a few best practices for improving the training phase. In particular, regularization and batch normalization will be discussed.
Adopting regularization to avoid overfitting
Intuitively, a good machine learning model should achieve a low error rate on training data. Mathematically this is equivalent to minimizing the loss function on the training data given the model:
min: {loss(Training Data | Model)}
However, this might not be enough. A model can become excessively complex in order to capture all the relations inherently expressed by the training data. This increase of complexity might have two negative consequences. First, a complex model might require a significant amount of time to be executed. Second, a complex model might achieve very good performance on training data, but perform quite badly on validation data. This is because the model is able to contrive relationships between many parameters in the specific training context, but these relationships in fact do not exist within a more generalized context. Causing a model to lose its ability to generalize in this manner is termed "overfitting." Again, learning is more about generalization than memorization:

Figure 31: Loss function and overfitting
As a rule of thumb, if during the training we see that the loss increases on validation, after an initial decrease, then we have a problem of model complexity, which overfits to the training data.
In order to solve the overfitting problem, we need a way to capture the complexity of a model, that is, how complex a model can be. What could the solution be? Well, a model is nothing more than a vector of weights. Each weight affects the output, except for those which are zero, or very close to it. Therefore, the complexity of a model can be conveniently represented as the number of non-zero weights. In other words, if we have two models M1 and M2 achieving pretty much the same performance in terms of loss function, then we should choose the simplest model, the one which has the minimum number of non-zero weights.
We can use a hyperparameter 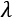 >=0 for controlling the importance of having a simple model, as in this formula:
>=0 for controlling the importance of having a simple model, as in this formula:
min: {loss(Training Data|Model)} + * complexity(Model)
There are three different types of regularization used in machine learning:
- L1 regularization (also known as LASSO): The complexity of the model is expressed as the sum of the absolute values of the weights.
- L2 regularization (also known as Ridge): The complexity of the model is expressed as the sum of the squares of the weights
- Elastic regularization: The complexity of the model is captured by a combination of the preceding two techniques
Note that playing with regularization can be a good way to increase the performance of a network, particularly when there is an evident situation of overfitting. This set of experiments is left as an exercise for the interested reader.
Also note that TensorFlow supports L1, L2, and ElasticNet regularization. Adding regularization is easy:
from tf.keras.regularizers import l2, activity_l2
model.add(Dense(64, input_dim=64, W_regularizer=l2(0.01),
activity_regularizer=activity_l2(0.01)))
A complete list of regularizers can be found at https://www.tensorflow.org/api_docs/python/tf/keras/regularizers.
Understanding BatchNormalization
BatchNormalization is another form of regularization and one of the most effective improvements proposed during the last few years. BatchNormalization enables us to accelerate training, in some cases by halving the training epochs, and it offers some regularization. Let's see what the intuition is behind it.
During training, weights in early layers naturally change and therefore the inputs of later layers can significantly change. In other words, each layer must continuously re-adjust its weights to the different distribution for every batch. This may slow down the model's training greatly. The key idea is to make layer inputs more similar in distribution, batch after batch and epoch after epoch.
Another issue is that the sigmoid activation function works very well close to zero, but tends to "get stuck" when values get sufficiently far away from zero. If, occasionally, neuron outputs fluctuate far away from the sigmoid zero, then said neuron becomes unable to update its own weights.
The other key idea is therefore to transform the layer outputs into a Gaussian distribution unit close to zero. In this way, layers will have significantly less variation from batch to batch. Mathematically, the formula is very simple. The activation input x is centered around zero by subtracting the batch mean 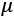 from it. Then, the result is divided by
from it. Then, the result is divided by 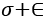 , the sum of batch variance
, the sum of batch variance 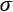 and a small number
and a small number 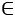 , to prevent division by zero. Then, we use a linear transformation
, to prevent division by zero. Then, we use a linear transformation 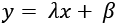 to make sure that the normalizing effect is applied during training.
to make sure that the normalizing effect is applied during training.
In this way, and 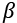 are parameters that get optimized during the training phase in a similar way to any other layer. BatchNormalization has been proven as a very effective way to increase both the speed of training and accuracy, because it helps to prevent activations becoming either too small and vanishing or too big and exploding.
are parameters that get optimized during the training phase in a similar way to any other layer. BatchNormalization has been proven as a very effective way to increase both the speed of training and accuracy, because it helps to prevent activations becoming either too small and vanishing or too big and exploding.



