






















































Let's assume we have the following scenario: we have a list of customers to call in order to sell them our product. Each phone call costs money in call center personal salaries, so we want to reduce these costs as much as possible. We have certain information about each customer that could help us determine whether they are likely to buy. After every call, we can update our model. The main goal is to call only the most promising customers and to improve our insights into which customers are more likely to pay for our product.
In this recipe, we will approach this with active learning, a strategy where we actively decide what to explore (and learn) next. Our model will help decide whom to call. Because we will update our model after each query (phone call), we will use online learning models.
Getting ready
We'll prepare for our recipe by downloading our dataset and installing a few libraries.
Again, we will get the data from OpenML:
!pip install -q openml
import openml
dataset = openml.datasets.get_dataset(1461)
X, y, categorical_indicator, _ = dataset.get_data(
dataset_format='DataFrame',
target=dataset.default_target_attribute
)
categorical_features = X.columns[categorical_indicator]
numeric_features = X.columns[
[not(i) for i in categorical_indicator]
]
This dataset is called bank-marketing, and you can see a description on OpenML at https://www.openml.org/d/1461.
For each row, describing a single person, we have different features, numerical and categorical, that tell us about demographics and customer history.
To model the likelihood of customers signing up for our product, we will use the scikit-multiflow package that specializes in online models. We will also use the category_encoders package again:
!pip install scikit-multiflow category_encoders
With these two libraries in place, we can start the recipe.
How to do it...
We need to implement an exploration strategy and a model that is being continuously updated. We are using the online version of the random forest, the Hoeffding Tree, as our model. We are estimating the uncertainties at every step, and based on that we will return a candidate to call next.
As always, we will need to define a few preprocessing steps:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import FunctionTransformer
import category_encoders as ce
ordinal_encoder = ce.OrdinalEncoder(
cols=None, # all features that it encounters
handle_missing='return_nan',
handle_unknown='ignore'
).fit(X)
preprocessor = ColumnTransformer(
transformers=[
('cat', ordinal_encoder, categorical_features),
('num', FunctionTransformer(validate=False), numeric_features)
])
preprocessor = preprocessor.fit(X)
Then we come to our active learning approach itself. This is inspired by modAL.models.ActiveLearner:
import numpy as np
from skmultiflow.trees.hoeffding_tree import HoeffdingTreeClassifier
from sklearn.metrics import roc_auc_score
import random
class ActivePipeline:
def __init__(self, model, preprocessor, class_weights):
self.model = model
self.preprocessor = preprocessor
self.class_weights = class_weights
@staticmethod
def values(X):
if isinstance(X, (np.ndarray, np.int64)):
return X
else:
return X.values
def preprocess(self, X):
X_ = pd.DataFrame(
data=self.values(X),
columns=[
'V1', 'V2', 'V3', 'V4',
'V5', 'V6', 'V7', 'V8',
'V9', 'V10', 'V11', 'V12',
'V13', 'V14', 'V15', 'V16'
])
return self.preprocessor.transform(X_)
def fit(self, X, ys):
weights = [self.class_weights[y] for y in ys]
self.model.fit(self.preprocess(X), self.values(ys))
def update(self, X, ys):
if isinstance(ys, (int, float)):
weight = self.class_weights[y]
else:
weight = [self.class_weights[y] for y in ys]
self.model.partial_fit(
self.preprocess(X),
self.values(ys),
weight
)
def predict(self, X):
return self.model.predict(
self.preprocess(X)
)
def predict_proba(self, X):
return self.model.predict_proba(
self.preprocess(X)
)
@staticmethod
def entropy(preds):
return -np.sum(
np.log((preds + 1e-15) * preds)
/ np.log(np.prod(preds.size))
)
def max_margin_uncertainty(self, X, method: str='entropy',
exploitation: float=0.9, favor_class: int=1, k: int=1
):
'''similar to modAL.uncertainty.margin_uncertainty
'''
probs = self.predict_proba(X)
if method=='margin':
uncertainties = np.abs(probs[:,2] - probs[:, 1]) / 2.0
elif method=='entropy':
uncertainties = np.apply_along_axis(self.entropy, 1, probs[:, (1,2)])
else: raise(ValueError('method not implemented!'))
if favor_class is None:
weights = uncertainties
else: weights = (1.0 - exploitation) * uncertainties + exploitation * probs[:, favor_class]
if self.sampling:
ind = random.choices(
range(len(uncertainties)), weights, k=k
)
else:
ind = np.argsort(weights, axis=0)[::-1][:k]
return ind, np.mean(uncertainties[ind])
def score(self, X, y, scale=True):
probs = self.predict_proba(X, probability=2)
if scale:
probs = np.clip(probs - np.mean(probs) + 0.5, 0, 1)
return roc_auc_score(y, probs)
Again, we create a scikit-learn-compatible class. It basically holds a machine learning model and a data preprocessor. We implement fit() and predict(), but also score() to get a model performance. We also implement an update() method that calls partial_fit() of the machine learning model. Calling partial_fit() instead of fit() considerably speeds up the computations, because we don't have to start from scratch every time we get new data.
Here's how to create the active learning pipeline:
active_pipeline = ActivePipeline(
HoeffdingTreeClassifier(),
preprocessor,
class_weights.to_dict()
)
active_pipeline.model.classes = [0, 1, 2]
We can run different simulations on our dataset with this setup. For example, we can compare a lot of experimentation (0.5 exploitation) against only exploitation (1.0), or no learning at all after the first batch. We basically go through a loop:
- Via active_pipeline.max_margin_uncertainty(), we present data to the active pipeline, and get a number of data points that integrate uncertainty and target predictions according to our preferences of the integration method.
- Once we get the actual results for these data points, we can update our model: active_pipeline.update().
You can see an example of this in the notebook on GitHub.
We can see that curious wins out after the first few examples. Exploitation is actually the least successful scheme. By not updating the model, performance deteriorates over time:
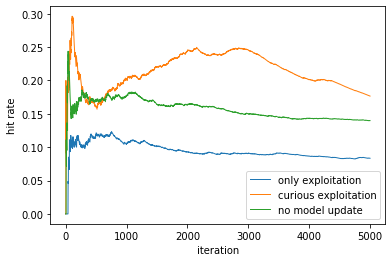
This is an ideal scenario for active learning or reinforcement learning, because, not unlike in reinforcement learning, uncertainty can be an additional criterion, apart from positive expectation, from a customer. Over time, this entropy reduction-seeking behavior reduces as the model's understanding of customers improves.
How it works...
It's worth delving a bit more into a few of the concepts and strategies employed in this recipe.
Active learning
Active learning means that we can actively query for more information; in other words, exploration is part of our strategy. This can be useful in scenarios where we have to actively decide what to learn, and where what we learn influences not only how much our model learns and how well, but also how much return on an investment we can get.
Hoeffding Tree
The Hoeffding Tree (also known as the Very Fast Decision Tree, VFDT for short) was introduced in 2001 by Geoff Hulten and others (Mining time-changing data streams). It is an incrementally growing decision tree for streamed data. Tree nodes are expanded based on the Hoeffding bound (or additive Chernoff bound). It was theoretically shown that, given sufficient training data, a model learned by the Hoeffding tree converges very closely to the one built by a non-incremental learner.
The Hoeffding bound is defined as follows:
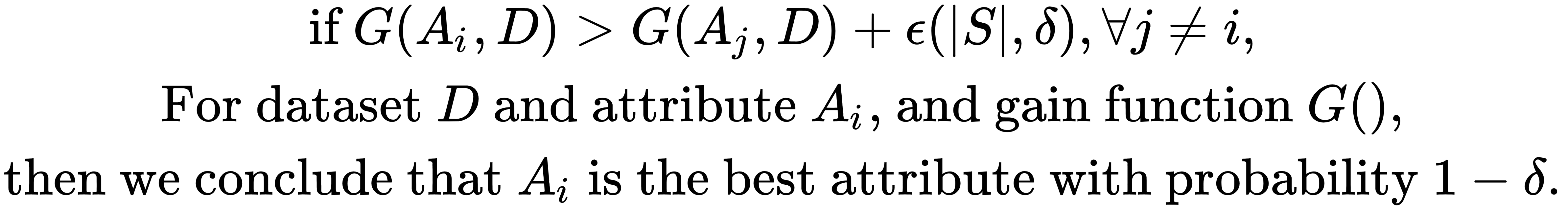
It's important to note that the Hoeffding Tree doesn't deal with data distributions that change over time.
Class weighting
Since we are dealing with an imbalanced dataset, let's use class weights. This basically means that we are upsampling the minority (signing up) class and downsampling the majority class (not signing up).
The formula for the class weights is as follows:
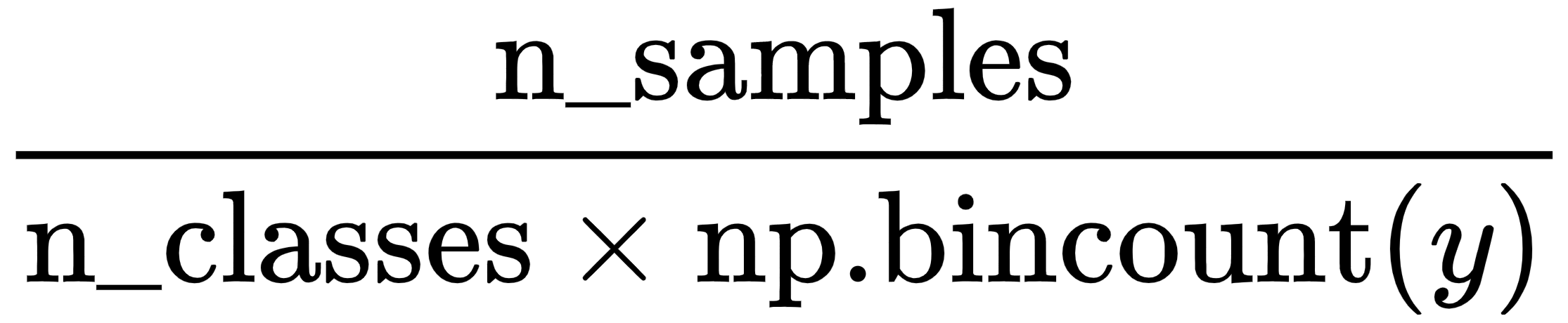
Similarly, in Python, we can write the following:
class_weights = len(X) / (y.astype(int).value_counts() * 2)
We can then use these class weights for sampling.
We'll close the recipe with a few more pointers.
See also
Only a few models in scikit-learn allow incremental or online learning. Refer to the list at https://scikit-learn.org/stable/modules/computing.html.
A few linear models include the partial_fit() method. The scikit-multiflow library specializes in incremental and online/streaming models: https://scikit-multiflow.github.io/
You can find more resources and ideas regarding active learning from a recent review that concentrates on biomedical image processing (Samuel Budd and others, A Survey on Active Learning and Human-in-the-Loop Deep Learning for Medical Image Analysis, 2019; https://arxiv.org/abs/1910.02923).
Our approach is inspired by the modalAI Python active learning package, which you can find at https://modal-python.readthedocs.io/. We recommend you check it out if you are interested in active learning approaches. A few more Python packages are available, as follows:
- Alipy: Active Learning in Python: http://parnec.nuaa.edu.cn/huangsj/alipy/
- Active Learning: A Google repo about active learning: https://github.com/google/active-learning
One of the main decisions in active learning is the trade-off between exploration and exploitation. You can find out more about this in a paper called Exploration versus exploitation in active learning: a Bayesian approach: http://www.vincentlemaire-labs.fr/publis/ijcnn_2_2010_camera_ready.pdf





