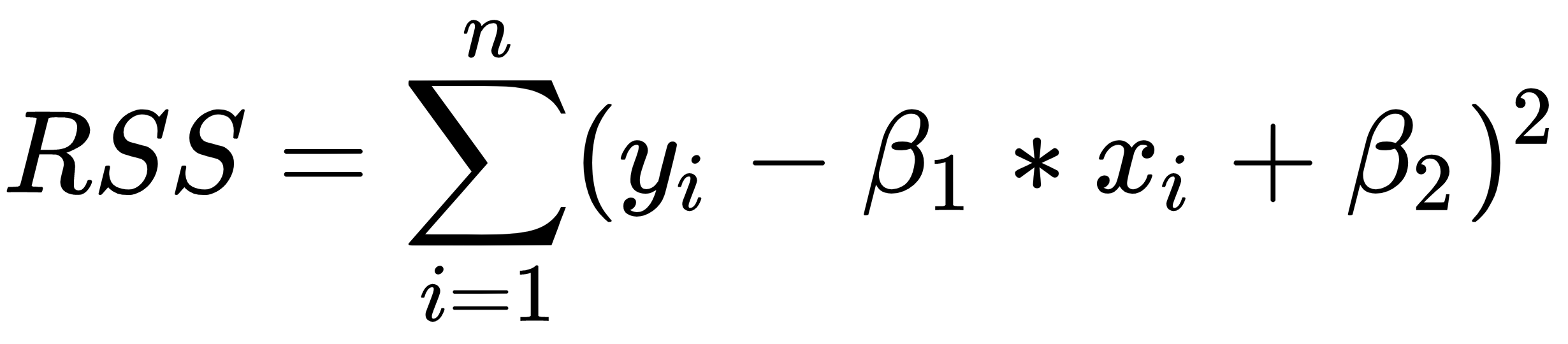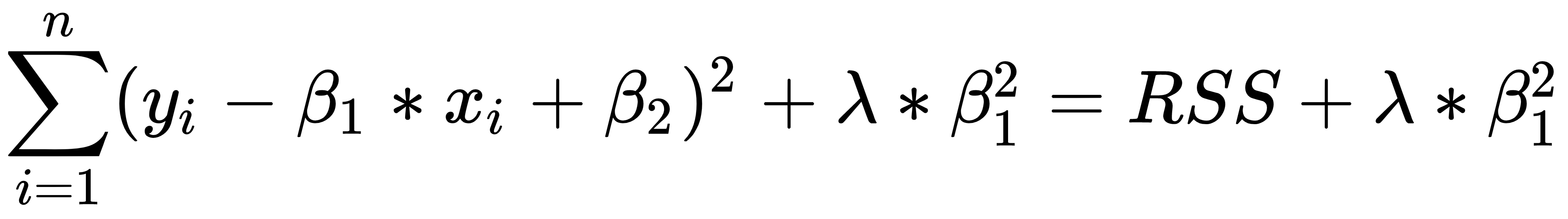One of the main problems of linear regression is that it's sensitive to outliers. During data collection in the real world, it's quite common to wrongly measure output. Linear regression uses ordinary least squares, which tries to minimize the squares of errors. The outliers tend to cause problems because they contribute a lot to the overall error. This tends to disrupt the entire model.
Let's try to deepen our understanding of the concept of outliers: outliers are values that, compared to others, are particularly extreme (values that are clearly distant from the other observations). Outliers are an issue because they might distort data analysis results; more specifically, descriptive statistics and correlations. We need to find these in the data cleaning phase, however, we can also get started on them in the next stage of data analysis. Outliers can be univariate when they have an extreme value for a single variable, or multivariate when they have a unique combination of values for a number of variables. Let's consider the following diagram:
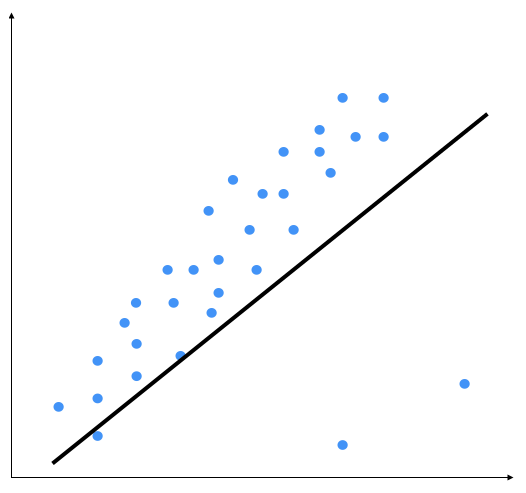
The two points on the bottom right are clearly outliers, but this model is trying to fit all the points. Hence, the overall model tends to be inaccurate. Outliers are the extreme values of a distribution that are characterized by being extremely high or extremely low compared to the rest of the distribution, and thus representing isolated cases with respect to the rest of the distribution. By visual inspection, we can see that the following output is a better model:
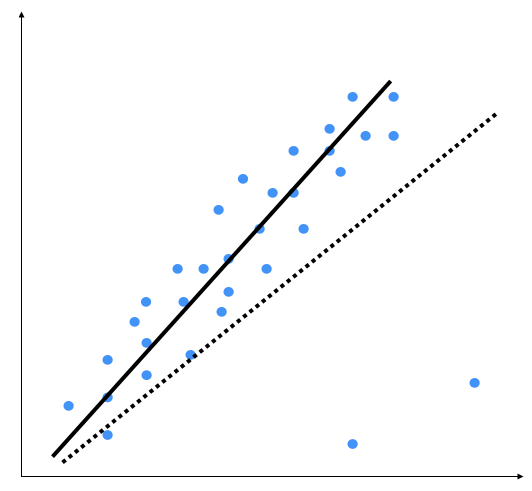
Ordinary least squares considers every single data point when it's building the model. Hence, the actual model ends up looking like the dotted line shown in the preceding graph. We can clearly see that this model is suboptimal.
The regularization method involves modifying the performance function, normally selected as the sum of the squares of regression errors on the training set. When a large number of variables are available, the least square estimates of a linear model often have a low bias but a high variance with respect to models with fewer variables. Under these conditions, there is an overfitting problem. To improve precision prediction by allowing greater bias but a small variance, we can use variable selection methods and dimensionality reduction, but these methods may be unattractive for computational burdens in the first case or provide a difficult interpretation in the other case.
Another way to address the problem of overfitting is to modify the estimation method by neglecting the requirement of an unbiased parameter estimator and instead considering the possibility of using a biased estimator, which may have smaller variance. There are several biased estimators, most of which are based on regularization: Ridge, Lasso, and ElasticNet are the most popular methods.