






















































Training models with scikit-learn
scikit-learn is one of the most widely used Python libraries for data science. It implements dozens of classic ML models, but also numerous tools to help you while training them, such as preprocessing methods and cross-validation. Nowadays, you’ll probably hear about more modern approaches, such as PyTorch, but scikit-learn is still a solid tool for a lot of use cases.
The first thing you must do to get started is to install it in your Python environment:
(venv) $ pip install scikit-learn
We can now start our scikit-learn journey!
Training models and predicting
In scikit-learn, ML models and algorithms are called estimators. Each is a Python class that implements the same methods. In particular, we have fit, which is used to train a model, and predict, which is used to run the trained model on new data.
To try this, we’ll load a sample dataset. scikit-learn comes with a few toy datasets that are very useful for performing experiments. You can find out more about them in the official documentation: https://scikit-learn.org/stable/datasets.html.
Here, we’ll use the digits dataset, a collection of pixel matrices representing handwritten digits. As you may have guessed, the goal of this dataset is to train a model to automatically recognize handwritten digits. The following example shows how to load this dataset:
chapter11_load_digits.py
from sklearn.datasets import load_digitsdigits = load_digits() data = digits.data targets = digits.target print(data[0].reshape((8, 8))) # First handwritten digit 8 x 8 matrix print(targets[0]) # Label of first handwritten digit
Notice that the toy dataset’s functions are imported from the datasets package of scikit-learn. The load_digits function returns an object that contains the data and some metadata.
The most interesting parts of this object are data, which contains the handwritten digit pixels matrices, and targets, which contains the corresponding label for those digits. Both are NumPy arrays.
To get a grasp of what this looks like, we will take the first digit in the data and reshape it into an 8 x 8 matrix; this is the size of the source images. Each value represents a pixel on a grayscale, from 0 to 16.
Then, we print the label of this first digit, which is 0. If you run this code, you’ll get the following output:
[[ 0. 0. 5. 13. 9. 1. 0. 0.] [ 0. 0. 13. 15. 10. 15. 5. 0.] [ 0. 3. 15. 2. 0. 11. 8. 0.] [ 0. 4. 12. 0. 0. 8. 8. 0.] [ 0. 5. 8. 0. 0. 9. 8. 0.] [ 0. 4. 11. 0. 1. 12. 7. 0.] [ 0. 2. 14. 5. 10. 12. 0. 0.] [ 0. 0. 6. 13. 10. 0. 0. 0.]] 0
Somehow, we can guess the shape of the zero from the matrix.
Now, let’s try to build a model that recognizes handwritten digits. To start simple, we’ll use a Gaussian Naive Bayes model, a classic and easy-to-use algorithm that can quickly yield good results. The following example shows the entire process:
chapter11_fit_predict.py
from sklearn.datasets import load_digitsfrom sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB digits = load_digits() data = digits.data targets = digits.target # Split into training and testing sets training_data, testing_data, training_targets, testing_targets = train_test_split( data, targets, random_state=0 ) # Train the model model = GaussianNB() model.fit(training_data, training_targets) # Run prediction with the testing set predicted_targets = model.predict(testing_data) # Compute the accuracy accuracy = accuracy_score(testing_targets, predicted_targets) print(accuracy)
Now that we’ve loaded the dataset, you can see that we take care of splitting it into a training and a testing set. As we mentioned in the Model validation section, this is essential for computing meaningful accuracy scores to check how our model performs.
To do this, we can rely on the train_test_split function, which is provided in the model_selection package. It selects random instances from our dataset to form the two sets. By default, it keeps 25% of the data to create a testing set, but this can be customized. The random_state argument allows us to set the random seed to make the example reproducible. You can find out more about this function in the official documentation: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html#sklearn-model-selection-train-test-split.
Then, we must instantiate the GaussianNB class. This class is one of the numerous ML estimators that’s implemented in scikit-learn. Each has its own set of parameters, to finely tune the behavior of the algorithm. However, scikit-learn is designed to provide sensible defaults for all the estimators, so it’s usually good to start with the defaults before tinkering with them.
After that, we must call the fit method to train our model. It expects an argument and two arrays: the first one is the actual data, with all its features, while the second one is the corresponding labels. And that’s it! You’ve trained your first ML model!
Now, let’s see how it behaves: we’ll call predict on our model with the testing set so that it automatically classifies the digits of the testing set. The result of this is a new array with the predicted labels.
All we have to do now is compare it with the actual labels of our testing set. Once again, scikit-learn helps by providing the accuracy_score function in the metrics package. The first argument is the true labels, while the second is the predicted labels.
If you run this code, you’ll get an accuracy score of around 83%. That isn’t too bad for a first approach! As you have seen, training and running prediction on an ML model is straightforward with scikit-learn.
In practice, we often need to perform preprocessing steps on the data before feeding it to an estimator. Rather than doing this sequentially by hand, scikit-learn proposes a convenient feature that can automate this process: pipelines.
Chaining preprocessors and estimators with pipelines
Quite often, you’ll need to preprocess your data so that it can be used by the estimator you wish to use. Typically, you’ll want to transform an image into an array of pixel values or, as we’ll see in the following example, transform raw text into numerical values so that we can apply some math to them.
Rather than writing those steps by hand, scikit-learn proposes a feature that can automatically chain preprocessors and estimators: pipelines. Once created, they expose the very same interface as any other estimator, allowing you to run training and prediction in one operation.
To show you what this looks like, we’ll look at an example of another classic dataset, the 20 newsgroups text dataset. It consists of 18,000 newsgroup articles categorized into 20 topics. The goal of this dataset is to build a model that will automatically categorize an article in one of those topics.
The following example shows how we can load this data thanks to the fetch_20newsgroups function:
chapter11_pipelines.py
import pandas as pdfrom sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics import accuracy_score, confusion_matrix from sklearn.naive_bayes import MultinomialNB from sklearn.pipeline import make_pipeline # Load some categories of newsgroups dataset categories = [ "soc.religion.christian", "talk.religion.misc", "comp.sys.mac.hardware", "sci.crypt", ] newsgroups_training = fetch_20newsgroups( subset="train", categories=categories, random_state=0 ) newsgroups_testing = fetch_20newsgroups( subset="test", categories=categories, random_state=0 )
Since the dataset is rather large, we’ll only load a subset of the categories. Also, notice that it’s already been split into training and testing sets, so we only have to load them with the corresponding argument. You can find out more about the functionality of this dataset in the official documentation: https://scikit-learn.org/stable/datasets/real_world.html#the-20-newsgroups-text-dataset.
Before moving on, it’s important to understand what the underlying data is. Actually, this is the raw text of an article. You can check this by printing one of the samples in the data:
>>> newsgroups_training.data[0]"From: sandvik@newton.apple.com (Kent Sandvik)\nSubject: Re: Ignorance is BLISS, was Is it good that Jesus died?\nOrganization: Cookamunga Tourist Bureau\nLines: 17\n\nIn article <f1682Ap@quack.kfu.com>, pharvey@quack.kfu.com (Paul Harvey)\nwrote:\n> In article <sandvik-170493104859@sandvik-kent.apple.com> \n> sandvik@newton.apple.com (Kent Sandvik) writes:\n> >Ignorance is not bliss!\n \n> Ignorance is STRENGTH!\n> Help spread the TRUTH of IGNORANCE!\n\nHuh, if ignorance is strength, then I won't distribute this piece\nof information if I want to follow your advice (contradiction above).\n\n\nCheers,\nKent\n---\nsandvik@newton.apple.com. ALink: KSAND -- Private activities on the net.\n"
So, we need to extract some features from this text before feeding it to an estimator. A common approach for this when working with textual data is to use the Term Frequency-Inverse Document Frequency (TF-IDF). Without going into too much detail, this technique will count the occurrences of each word in all the documents (term frequency), weighted by the importance of this word in every document (inverse document frequency). The idea is to give more weight to rarer words, which should convey more sense than frequent words such as “the.” You can find out more about this in the scikit-learn documentation: https://scikit-learn.org/dev/modules/feature_extraction.html#tfidf-term-weighting.
This operation consists of splitting each word in the text samples and counting them. Usually, we apply a lot of techniques to refine this, such as removing stop words (common words such as “and” or “is” that don’t bring much information). Fortunately, scikit-learn provides an all-in-one tool for this: TfidfVectorizer.
This preprocessor can take an array of text, tokenize each word, and compute the TF-IDF for each of them. A lot of options are available for finely tuning its behavior, but the defaults are a good start for English text. The following example shows how to use it with an estimator in a pipeline:
chapter11_pipelines.py
# Make the pipelinemodel = make_pipeline( TfidfVectorizer(), MultinomialNB(), )
The make_pipeline function accepts any number of preprocessors and an estimator in its argument. Here, we’re using the Multinomial Naive Bayes classifier, which is suitable for features representing frequency.
Then, we can simply train our model and run prediction to check its accuracy, as we did previously. You can see this in the following example:
chapter11_pipelines.py
# Train the modelmodel.fit(newsgroups_training.data, newsgroups_training.target) # Run prediction with the testing set predicted_targets = model.predict(newsgroups_testing.data) # Compute the accuracy accuracy = accuracy_score(newsgroups_testing.target, predicted_targets) print(accuracy) # Show the confusion matrix confusion = confusion_matrix(newsgroups_testing.target, predicted_targets) confusion_df = pd.DataFrame( confusion, index=pd.Index(newsgroups_testing.target_names, name="True"), columns=pd.Index(newsgroups_testing.target_names, name="Predicted"), ) print(confusion_df)
Notice that we also printed a confusion matrix, which is a very convenient representation of the global results. Scikit-learn has a dedicated function for this called confusion_matrix. Then, we wrap the result in a pandas DataFrame so that we can set the axis labels to improve readability. If you run this example, you’ll get an output similar to what’s shown in the following screenshot. Depending on your machine and system, it could take a couple of minutes to run:
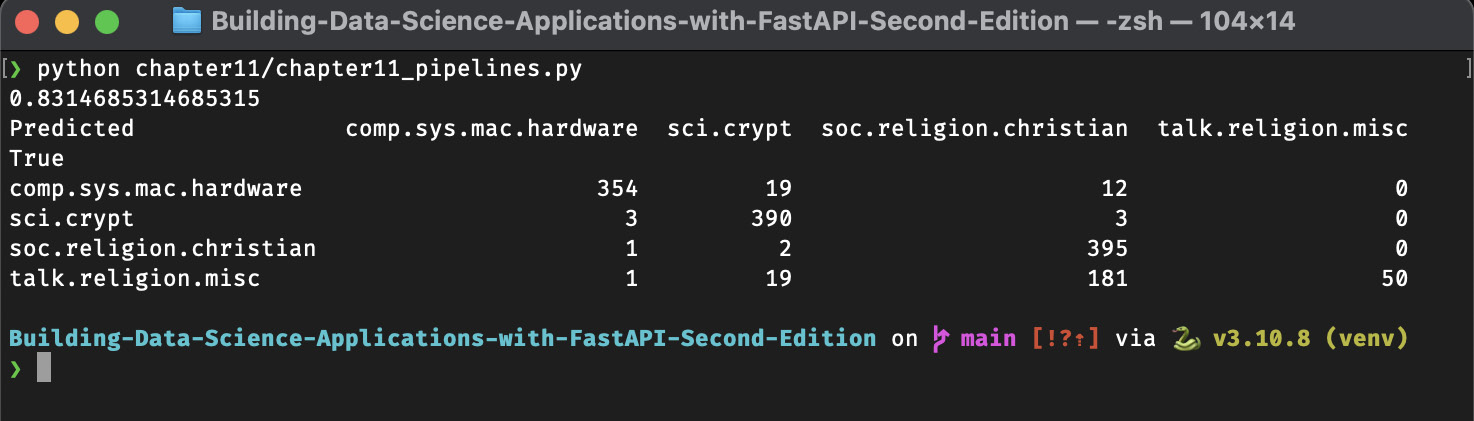
Figure 11.3 – Confusion matrix on the 20 newsgroups dataset
Here, you can see that our results weren’t too bad for our first try. Notice that there is one big area of confusion between the soc.religion.christian and talk.religion.misc categories, which is not very surprising, given their similarity.
As you’ve seen, building a pipeline with a preprocessor is very straightforward. The nice thing about this is that it automatically applies it to the training data, but also when you’re predicting the results.
Before moving on, let’s look at one more important feature of scikit-learn: cross-validation.
Validating the model with cross-validation
In the Model validation section, we introduced the cross-validation technique, which allows us to use data in training or testing sets. As you may have guessed, this technique is so common that it’s implemented natively in scikit-learn!
Let’s take another look at the handwritten digit example and apply cross-validation:
chapter11_cross_validation.py
from sklearn.datasets import load_digitsfrom sklearn.model_selection import cross_val_score from sklearn.naive_bayes import GaussianNB digits = load_digits() data = digits.data targets = digits.target # Create the model model = GaussianNB() # Run cross-validation score = cross_val_score(model, data, targets) print(score) print(score.mean())
This time, we don’t have to split the data ourselves: the cross_val_score function performs the folds automatically. In argument, it expects the estimator, data, which contains the handwritten digits’ pixels matrices, and targets, which contains the corresponding label for those digits. By default, it performs five folds.
The result of this operation is an array that provides the accuracy score of the five folds. To get a global overview of this result, we can take, for example, the mean. If you run this example, you’ll get the following output:
python chapter11/chapter11_cross_validation.py[0.78055556 0.78333333 0.79387187 0.8718663 0.80501393] 0.8069281956050759
As you can see, our mean accuracy is around 80%, which is a bit lower than the 83% we obtained with single training and testing sets. That’s the main benefit of cross-validation: we obtain a more statistically accurate metric regarding the performance of our model.
With that, you have learned the basics of working with scikit-learn. It’s obviously a very quick introduction to this vast framework, but it’ll give you the keys to train and evaluate your first ML models.


