






















































Evolution of data systems
We have been collecting data for decades. The flat file storages of the 60s led to the data warehouses of the 80s to Massively Parallel Processing (MPP) and NoSQL databases, and eventually to data lakes. New paradigms continue to be coined but it would be fair to say that most enterprise organizations have settled on some variation of a data lake:

Figure 1.8 – Evolution of big data systems
Cloud adoption continues to grow with even highly regulated industries such as healthcare and Fintech embracing the cloud for cost-effective alternatives to keep pace with innovation; otherwise, they risk being left behind. People who have used security as the reason for not going to the cloud should be reminded that all the massive data breaches that have been splashing the media in recent years have all been from on-premises setups. Cloud architectures have more scrutiny and are in some ways more governed and secure.
Rise of cloud data platforms
The data challenges remain the same. However, over time, the three major shifts in architecture offerings have been due to the introduction of the following:
- Data warehouses
- Hadoop heralding the start of data lakes
- Cloud data platforms refining the data lake offerings
The use cases that we've been trying to solve for all three generations can be placed into three categories, as follows:
- SQL-based BI Reporting
- Exploratory data analytics (EDA)
- ML
Data warehouses were good at handling modest volume structured data and excelled at BI Reporting use cases, but they had limited support for semi-structured data and practically no support for unstructured data. Their workloads could only support batch processing. Once ingested, the data was in a proprietary format, and they were expensive. So, older data would be dropped in favor of accommodating new data. Also, because they were running at capacity, interactive queries had to wait for ingestion workloads to finish to avoid putting strain on the system. There were no ML capabilities built into these systems.
Hadoop came with the promise of handling large volumes of data and could support all types of data, along with streaming capabilities. In theory, all the use cases were feasible. In practice, they weren't. Schema on read meant that the ingestion path was greatly simplified, and people dumped their data, but the consumption paths were more difficult. Managing the Hadoop cluster was complex, so it was a challenge to upgrade versions of software. Hive was SQL-like and was the most popular of all the Hadoop stack offerings. However, access performance was slow. So, part of the curated data was pushed into data warehouses due to their structure. This meant that data personas were left to stitch two systems that had their fair share of fragility and increased end-to-end latency.
Cloud data platforms were the next entrants who simplified the infrastructure manageability and governance aspects and delivered on the original promise of Hadoop. Extra attention was spent to prevent data lakes from turning into data swamps. The elasticity and scalability of the cloud helped contain costs and made it a worthwhile investment. Simplification efforts led to more adoption by data personas.
The following diagram summarizes the end-to-end flow of big data, along with its requirements in terms of volume, variety, and velocity. The process varies on each platform as the underlying technologies are different. The solutions have evolved from warehouses to Hadoop to cloud data platforms to help serve the three main types of use cases across different industry verticals:
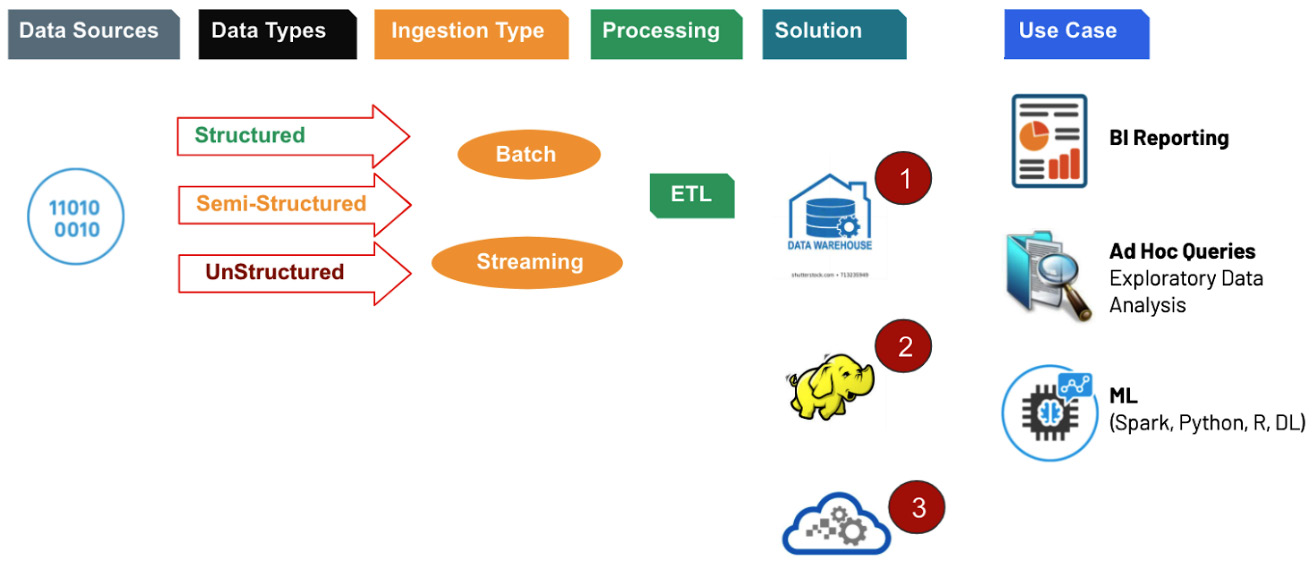
Figure 1.9 – The rise of modern cloud data platforms
SQL and NoSQL systems
SQL databases were the forerunners before NoSQL databases arose, which were created with different semantics. There are several categories of NoSQL stores, and they can roughly be classified as follows:
- Key-Value Stores: For example, AWS S3, and Azure Blob Storage
- Big Table Stores: For example, DynamoDB, HBase, and Cassandra
- Document Stores: For example, CouchDB and MongoDB
- Full Text Stores: For example, Solr and Elastic (both based on Lucene)
- Graph Data Stores: For example, Neo4j
- In-memory Data Stores: For example, Redis and MemSQL
While relational systems honor ACID properties, NoSQL systems were designed primarily for scale and flexibility and honored BASE properties, where data consistency and integrity are not the highest concerns.
ACID properties are honored in a transaction, as follows:
- Atomicity: Either the transaction succeeds or it fails.
- Consistency: The logic must be correct every time.
- Isolation: In a multi-tenant setup with numerous operations, proper demarcation is used to avoid collisions.
- Durability: Once set, the data remains unchanged.
Use cases that contain highly structured data with predictable inputs and outputs, such as a financial system with a money transfer process where consistency is the main requirement.
BASE properties are honored, as follows:
- Basically Available: The system is guaranteed to be available in the event of a failure.
- Soft State: The state could change because of multi-node inconsistencies.
- Eventual Consistency: All the nodes will eventually reconcile on the last state but there may be a period of inconsistency.
This applies to less structured scenarios involving changing schemas, such as a Twitter application scanning words to determine user sentiment. High availability despite failures is the main requirement.
OLTP and OLAP systems
It is useful to classify operational data versus analytical data. Data producers typically push data into Operational Data Stores (ODS). Previously, this data was sent to data warehouses for analytics. In recent times, the trend is changing to push the data into a data lake. Different consumers tap into the data at various stages of processing. Some may require a portion of the data from the data lake to be pushed to a data warehouse or a separate serving layer (which can be NoSQL or in-memory).
Online Transaction Processing (OLTP) systems are transaction-oriented, with continuous updates supporting business operations. Online Analytical Processing (OLAP) systems, on the other hand, are designed for decision support systems that are processing several ad hoc and complex queries to analyze the transactions and produce insights:
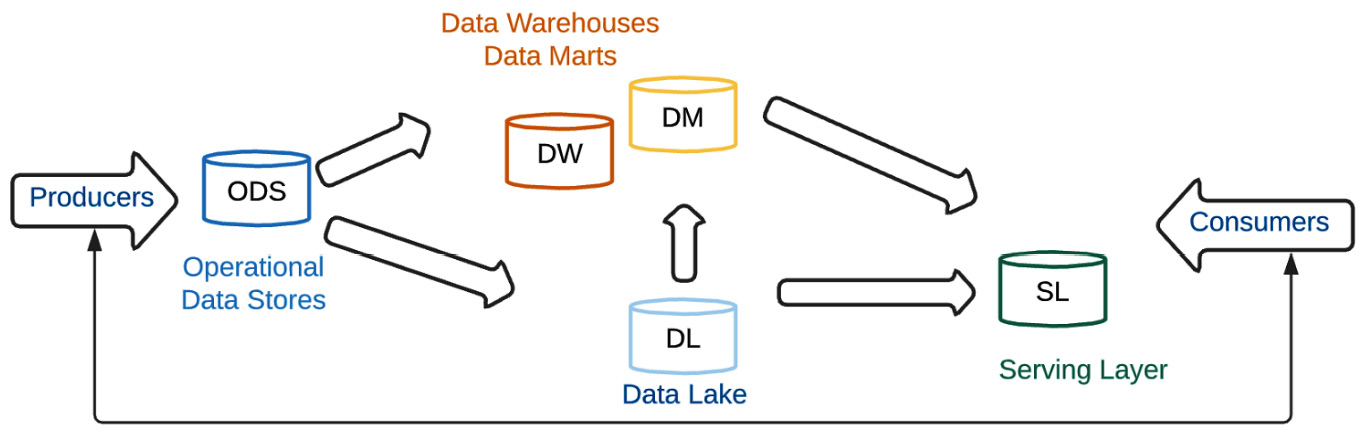
Figure 1.10 – OLTP and OLAP systems
Data platform service models
Depending on the skill set of the data team, the timelines, the capabilities, and the flexibilities being sought, a decision needs to be made regarding the right service model. The following table summarizes the model offerings and the questions you should ask to decide on the best fit:

Figure 1.11 – Service model offerings
The following table further expands on the main value proposition of each service offering, highlighting the key benefits and guidelines on when to adopt them:
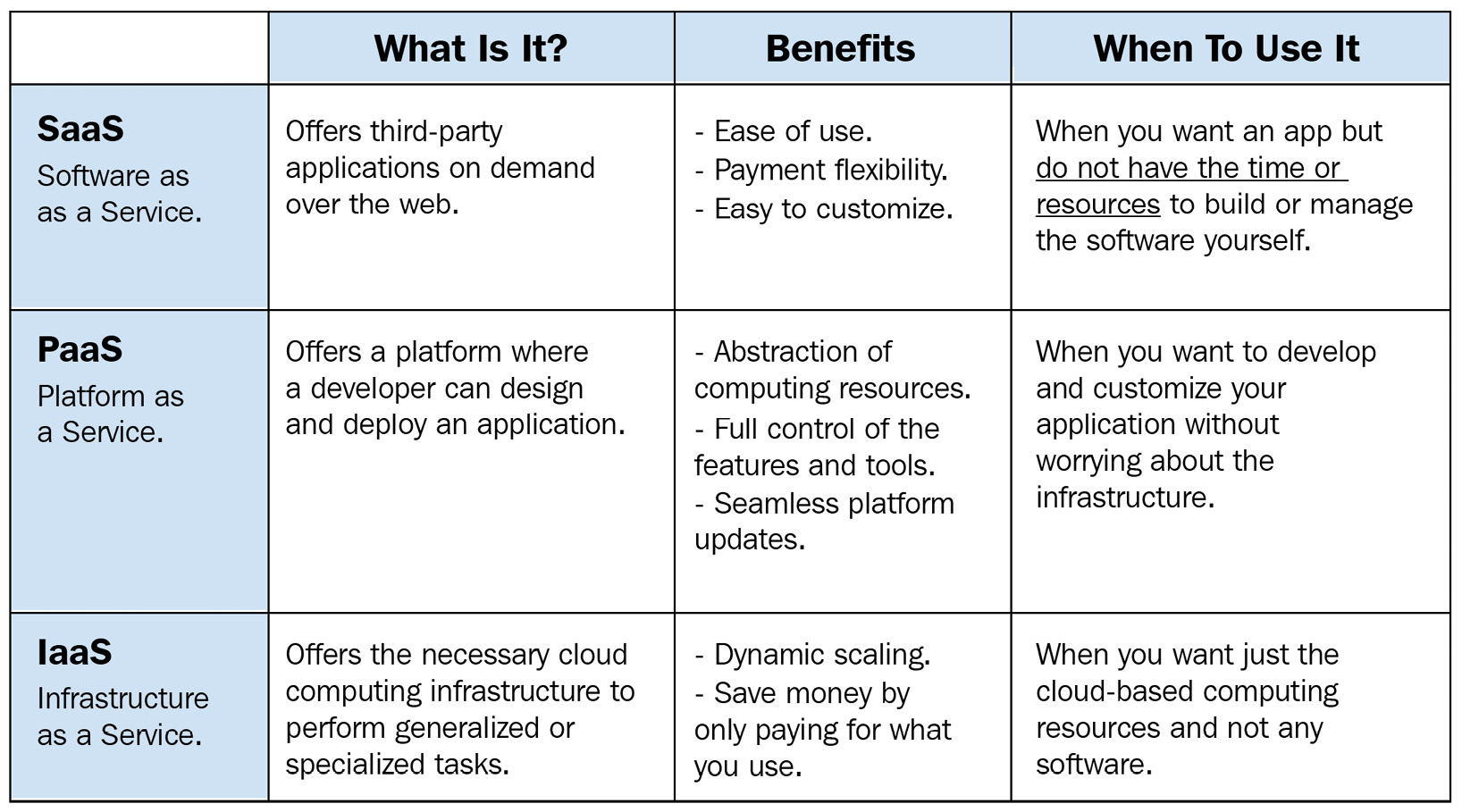
Figure 1.12 – How to find the right service model fit

