






















































The data
We can find the spam dataset from the following link:
http://spamassassin.apache.org/
In the following screenshot, we can see the easy ham (not spam) folder with 2551 files:
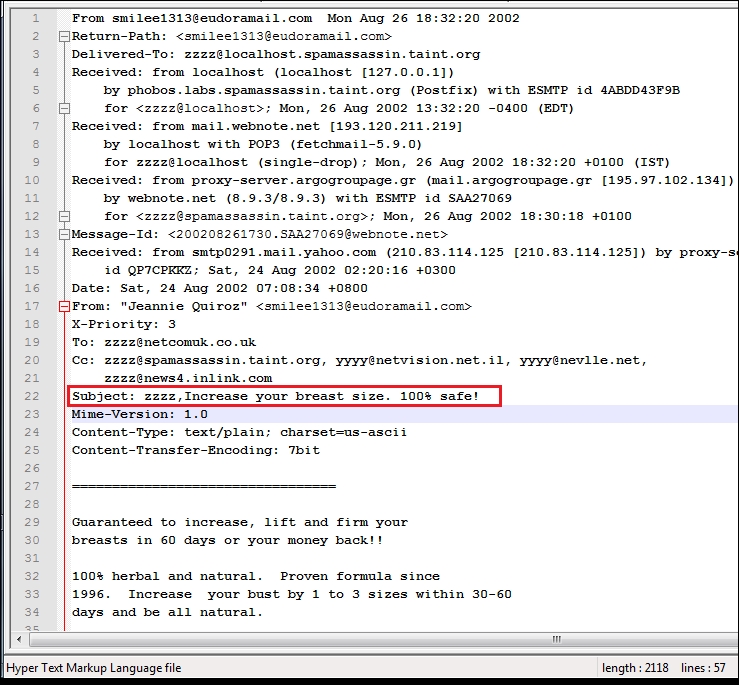
The spam text looks like the following screenshot, which may include HTML tags and plain text. In this case, we are only interested in the subject line, so we need to write a code to obtain the subject from all the files.
This example will show you how to preprocess the SpamAssassin data using Python in order to collect all the subject lines from the e-mails.
First, we need to import the os module in order to get the list of file names using the listdir function from the " \spam" and " \easy_ham" folders:
import os files = os.listdir(r" \spam")
Now we need a new file to store the subject lines and the category (spam or not spam); this time, we will use a comma as a separator:
with open("SubjectsSpam.out","a") as out:
category = "spam"
Now we will parse each file and get the subject. Finally, we write...










