






















































Case study: sentiment analysis of social media feeds
Consider a marketing department that wants to evaluate the effectiveness of its campaigns by monitoring brand sentiment on social media sites. Because changes in sentiment could have negative effects on the larger company, this analysis is performed in real time. An overview of this example is shown in the Figure 6.
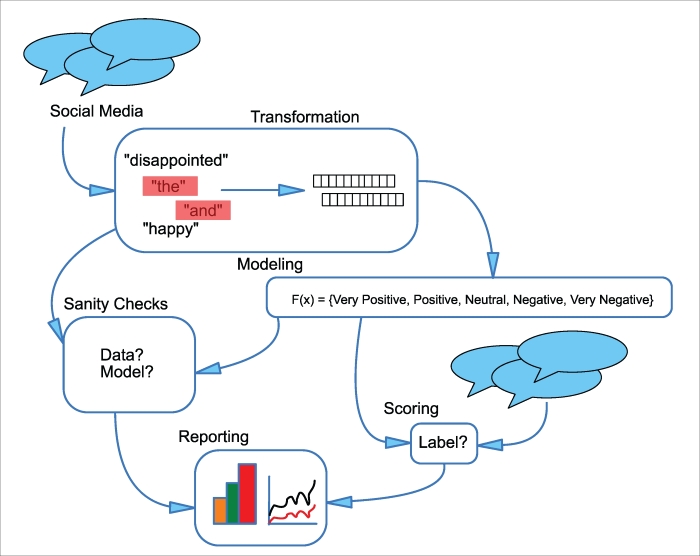
Figure 6: Diagram of social media sentiment analysis case study
Data input and transformation
The input data to this application are social media posts. This data is available in real time, but a number of steps need to be applied to make it usable by the sentiment-scoring model. Common words (such as and and the) need to be filtered, messages to be selected which actually refer to the company, and misspellings and word capitalization need to be normalized. Once this cleaning is done, further transformations may turn the message into a vector, with a count of each word in the model's allowed vocabulary, or hashed to populate a fixed-length vector.
Sanity checking
The outputs of the preceding transformations need to be sanity checked – are there any users who account for an unusually large number of messages (which might indicate bot spam)? Are there unexpected words in the input (which could be due to character encoding issues)? Are any of the input messages longer than the allowed message size for the service (which could indicate incorrect separation of messages in the input stream)?
Once the model is developed, sanity checking involves some human guidance. Do the sentiments predicted by the model correlate with the judgment of human readers? Do the words that correspond to high probability for a given sentiment in the model make intuitive sense?
These and other sanity checks can be visualized as a webpage or document summary that can be utilized by both the modeler, to evaluate model health, and the rest of the marketing staff to understand new topics that may correspond to positive or negative brand sentiment.
Model development
The model used in this pipeline is a multinomial logistic regression (Chapter 5, Putting Data in its Place – Classification Methods and Analysis) that takes as input counts of the words in each social media message and outputs a predicted probability that the message belongs to a given sentiment category: VERY POSITIVE, POSITIVE, NEUTRAL, NEGATIVE, and VERY NEGATIVE. While in theory (because the multinomial logistic regression can be trained using stochastic gradient updates), we could perform model training online, in practice this is not possible because the labels (sentiments) need to be assigned by a human expert. Therefore, our model is developed in an offline batch-process each week as a sufficient set of social media messages labelled by an expert becomes available. The hyperparameters of this model (the regularization weight and learning weight) have been estimated previously, so the batch retraining calculates the regression coefficient weights for a set of training messages and evaluates the performance on a separate batch of test messages.
Scoring
Incoming messages processed by this pipeline can be scored by the existing model and assigned to one of the five sentiment classes, and the volume of each category is updated in real time to allow monitoring of brand sentiment and immediate action if there is an extremely negative response to one of the marketing department's campaigns.
Visualization and reporting
As the model scores new social media messages, it updates a real-time dashboard with the volume of messages in each category compared to yesterday, the preceding week, and the preceding month, along with which words are given most weight in this week's model for the different classes. It also monitors the presence of new words, which may not have been present in the model's vocabulary, and which could indicate new features that the model cannot appropriately score, and suggest the need for inter-week retraining. In addition to this real-time dashboard, which the marketing department uses to monitor response to its campaigns, the analyst develops a more detailed report concerning model parameters and performance along with input dataset summary statistics, which they use to determine if the model training process each week is performing as expected, or if the quality of the model is degrading over time.


