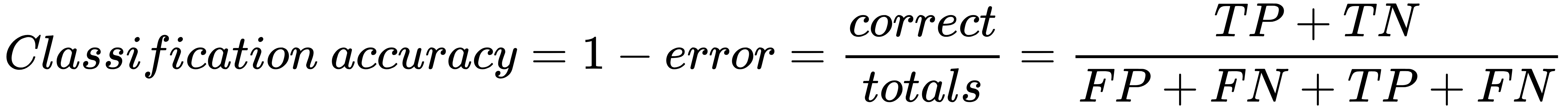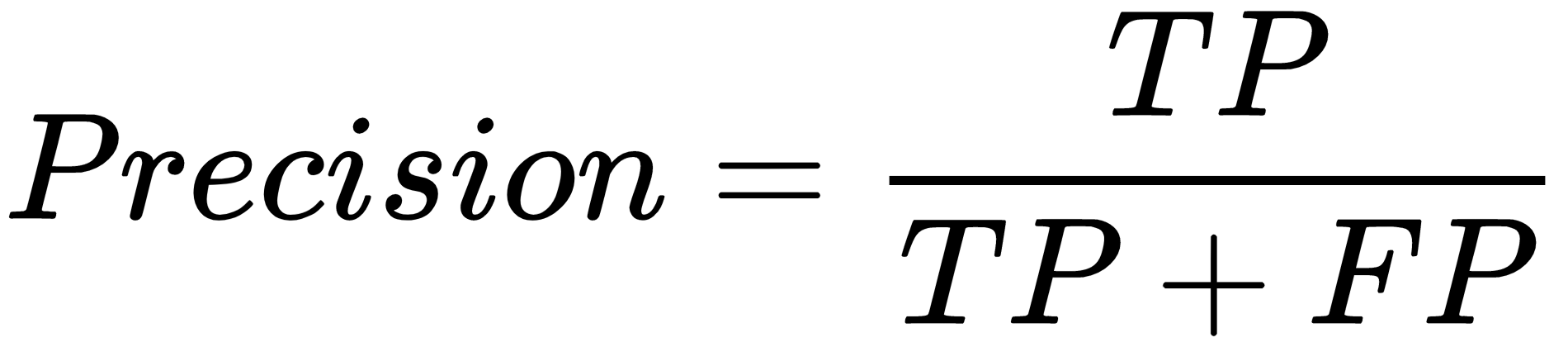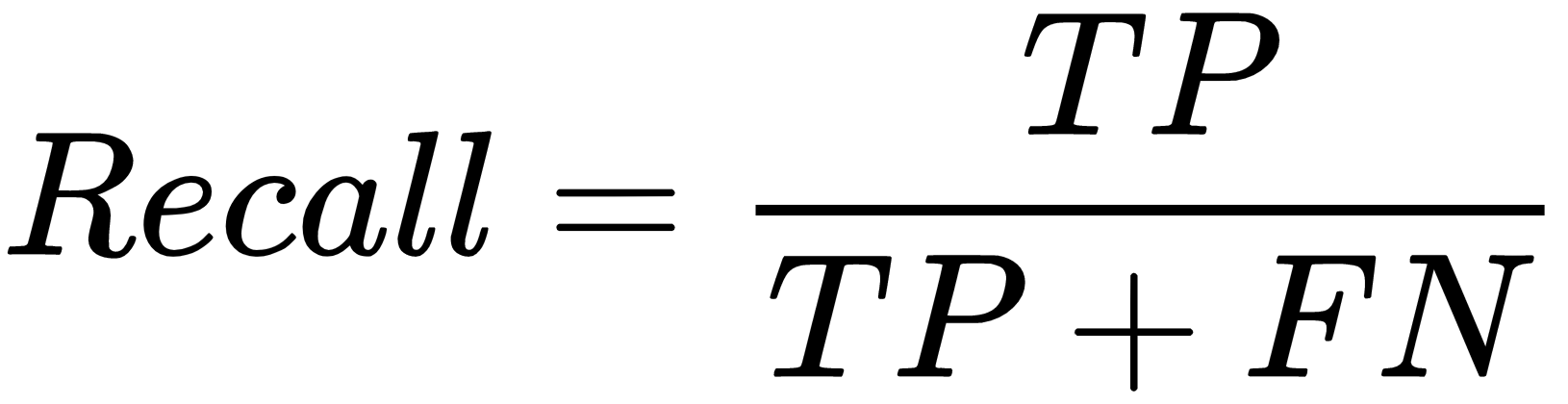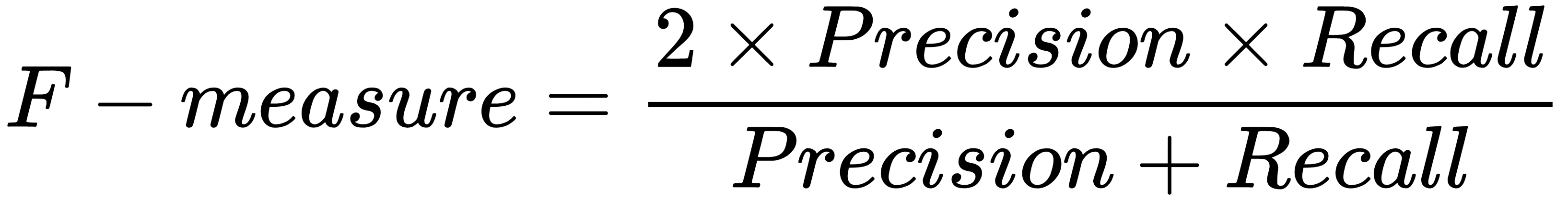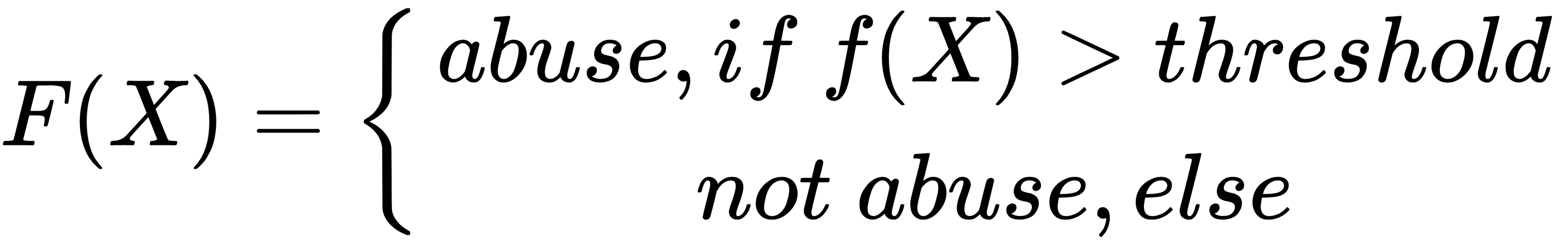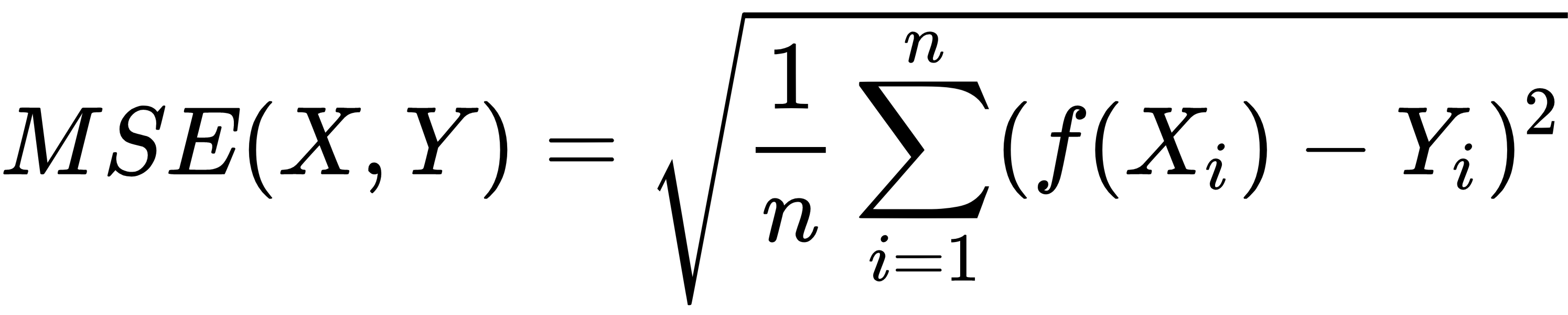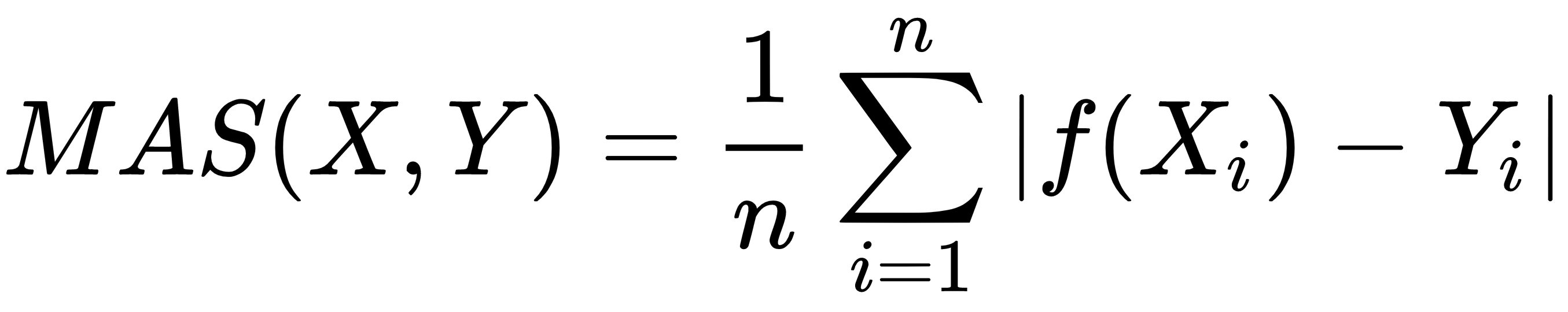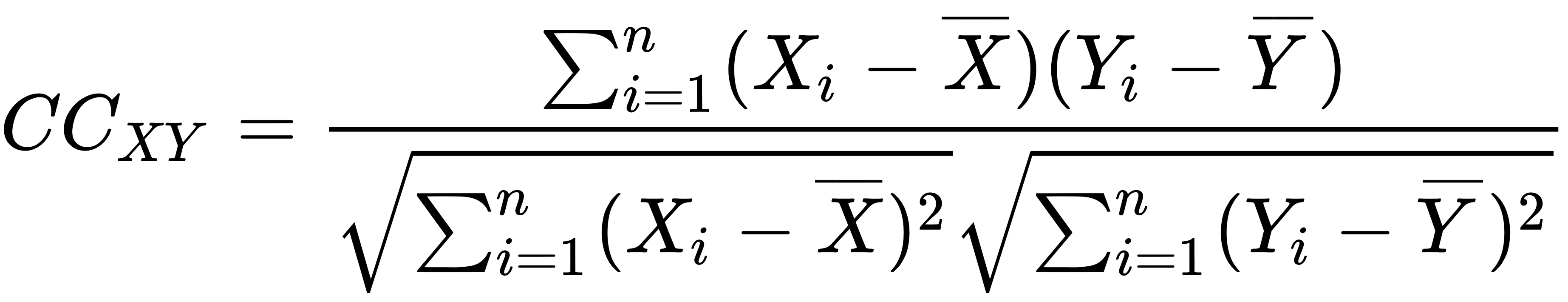Supervised learning is the key concept behind such amazing things as voice recognition, email spam filtering, and face recognition in photos, and detecting credit card frauds. More formally, given a set, D, of learning examples described with features, X, the goal of supervised learning is to find a function that predicts a target variable, Y. The function, f ,that describes the relation between features X and class Y is called a model:
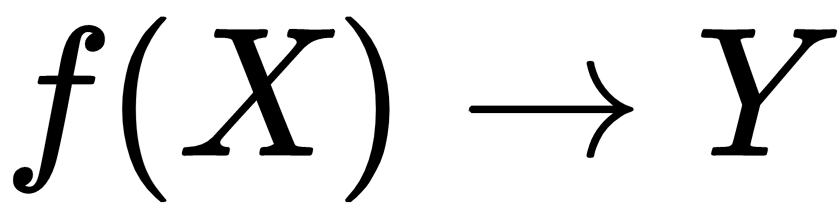
The general structure of supervised learning algorithms is defined by the following decisions (Hand et al., 2001):
- Define the task
- Decide on the machine learning algorithm, which introduces specific inductive bias; that is, and a priori assumptions that it makes regarding the target concept
- Decide on the score or cost function, for instance, information gain, root mean square error, and so on
- Decide on the optimization/search method to optimize the score function
- Find a function that describes the relation between X and Y
Many decisions are already made for us by the type of the task and dataset that we have. In the following sections, we will take a closer look at the classification and regression methods and the corresponding score functions.