






















































In this section, we'll present some of the most popular deep learning frameworks. Then we will discuss some cloud based platforms where you can deploy/run your DL applications. In short, almost all of the libraries provide the possibility of using a graphics processor to speed up the learning process, are released under an open license, and are the result of university research groups.
DL frameworks and cloud platforms
Deep learning frameworks
TensorFlow is mathematical software, and an open source software library for machine intelligence. The Google Brain team developed it in 2011 and open-sourced it in 2015. The main features offered by the latest release of TensorFlow (v1.8 during the writing of this book) are faster computing, flexibility, portability, easy debugging, a unified API, transparent use of GPU computing, easy use, and extensibility. Once you have constructed your neural network model, after the necessary feature engineering, you can simply perform the training interactively using plotting or TensorBoard.
Keras is a deep learning library that sits atop TensorFlow and Theano, providing an intuitive API inspired by Torch. It is perhaps the best Python API in existence. DeepLearning4J relies on Keras as its Python API and imports models from Keras and through Keras from Theano and TensorFlow.
Theano is also a deep learning framework written in Python. It allows using GPU, which is 24x faster than a single CPU. Defining, optimizing, and evaluating complex mathematical expressions is very straightforward in Theano.
Neon is a Python-based deep learning framework developed by Nirvana. Neon has a syntax similar to Theano's high-level framework (for example, Keras). Currently, Neon is considered the fastest tool for GPU-based implementation, especially for CNNs. But its CPU-based implementation is relatively worse than most other libraries.
PyTorch is a vast ecosystem for ML that offers a large number of algorithms and functions, including for DL and for processing various types of multimedia data, with a particular focus on parallel computing. Torch is a highly portable framework supported on various platforms, including Windows, macOS, Linux, and Android.
Caffe, developed primarily by Berkeley Vision and Learning Center (BVLC), is a framework designed to stand out because of its expression, speed, and modularity.
MXNet (http://mxnet.io/) is a deep learning framework that supports many languages, such as R, Python, C++, and Julia. This is helpful because if you know any of these languages, you will not need to step out of your comfort zone at all to train your deep learning models. Its backend is written in C++ and CUDA and it is able to manage its own memory in a way similar to Theano.
The Microsoft Cognitive Toolkit (CNTK) is a unified deep learning toolkit from Microsoft Research that makes it easy to train and combine popular model types across multiple GPUs and servers. CNTK implements highly efficient CNN and RNN training for speech, image, and text data. It supports cuDNN v5.1 for GPU acceleration.
DeepLearning4J is one of the first commercial-grade, open source, distributed deep learning libraries written for Java and Scala. This also provides integrated support for Hadoop and Spark. DeepLearning4 is designed to be used in business environments on distributed GPUs and CPUs.
DeepLearning4J aims to be cutting-edge and plug-and-play, with more convention than configuration, which allows for fast prototyping for non-researchers. The following libraries can be integrated with DeepLearning4 and will make your JVM experience easier whether you are developing your ML application in Java or Scala.
ND4J is just like NumPy for JVM. It comes with some basic operations of linear algebra such as matrix creation, addition, and multiplication. ND4S, on the other hand, is a scientific computing library for linear algebra and matrix manipulation. It supports n-dimensional arrays for JVM-based languages.
To conclude, the following figure shows the last 1 year's Google trends concerning the popularity of different DL frameworks:
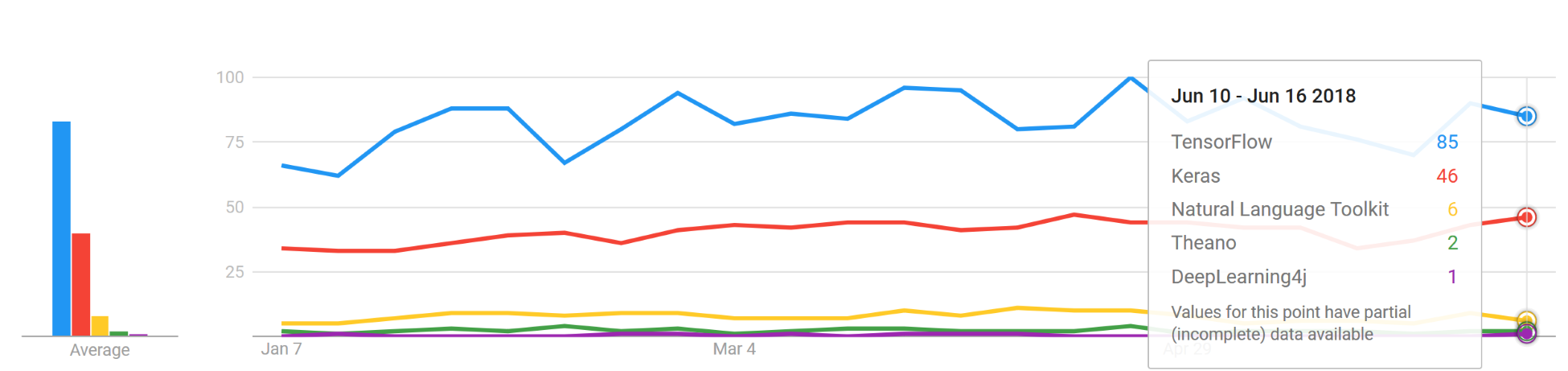
The trends of different DL frameworks. TensorFlow and Keras are most dominating. Theano is losing its popularity. On the other hand, DeepLearning4J is emerging for JVM.
Cloud-based platforms for DL
Apart from the preceding libraries, there have been some recent initiatives for deep learning on the cloud. The idea is to bring deep learning capabilities to big data with millions of billions of data points and high-dimensional data. For example, Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, and NVIDIA GPU Cloud (NGC) all offer machine and deep learning services that are native to their public clouds.
In October 2017, AWS released deep learning Amazon Machine Images (AMIs) for Amazon Elastic Compute Cloud (EC2) P3 instances. These AMIs come pre-installed with deep learning frameworks, such as TensorFlow, Gluon, and Apache MXNet, that are optimized for the NVIDIA Volta V100 GPUs within Amazon EC2 P3 instances.
The Microsoft Cognitive Toolkit is Azure's open source, deep learning service. Similar to AWS's offering, it focuses on tools that can help developers build and deploy deep learning applications.
On the other hand, NGC empowers AI scientists and researchers with GPU-accelerated containers (see https://www.nvidia.com/en-us/data-center/gpu-cloud-computing/). NGC features containerized deep learning frameworks such as TensorFlow, PyTorch, MXNet, and more that are tuned, tested, and certified by NVIDIA to run on the latest NVIDIA GPUs.
Now that we have a minimum of knowledge about available DL libraries, frameworks, and cloud-based platforms for running and deploying our DL applications, we can dive into coding. First, we will start by solving the famous Titanic survival prediction problem. However, we won't use the previously listed frameworks; we will be using the Apache Spark ML library. Since we will be using Spark along with other DL libraries, knowing a little bit of Spark would help us grasp things in the upcoming chapters.








