






















































NLP applications are everywhere, and it is highly unlikely that you have not interacted with any such application over the past few days. The current applications include virtual assistants (Alexa, Siri, Cortana, and so on), customer support tools (chatbots, email routers/classifiers, and so on), sentiment analyzers, translators, and document ranking systems. The adoption of these tools is quickly growing, since the speed and accuracy of these applications have increased manifold over the years. It should be noted that many popular NLP applications such as, Alexa and conversational bots, need to process audio data, which can be quantified by capturing the frequency of the underlying sound waves of the audio. For these applications, the data preprocessing steps are different from those for a text-based application, but the core principles of analyzing the data remain the same and will be discussed in detail in this book.
The following are examples of some widely used NLP tools. These tools could be web applications or desktop applications with which you can interact via the user interface. We will be covering the models powering these tools in detail in the subsequent chapters.
Chatbots
Chatbots are AI-based software that can conduct conversations with humans in natural languages. Chatbots are used extensively as the first point of customer support and have been very effective in resolving simple user queries. As per industry estimates, the size of the global chatbot market is expected to grow to $102 billion by 2025, compared to the market size of $17 billion in 2019 (source: https://www.mordorintelligence.com/industry-reports/chatbot-market). The significant savings generated by these chatbots for organizations is the major driver for the increase in the uptake of this technology.
Chatbots can be simple and rule-based, or highly sophisticated, depending on business requirements. Most chatbots deployed in the industry today are trained to direct users to the appropriate source of information or respond to queries pertaining to a specific subject. It is highly unlikely to have a generalist chatbot capable of fielding questions pertaining to a number of areas. This is because training a chatbot on a given topic requires a copious amount of data, and training on a number of topics could result in performance issues.
The next screenshots are from my conversation with one of the smartest chatbots available, named Mitsuku (https://www.pandorabots.com/mitsuku/). The Mitsuku chatbot was created by Steve Worswick and it has the distinction of winning the Loebner Prize multiple times due to it being adjudged the most human-like AI application.
The application was created using Artificial Intelligence Markup Language (AIML) and is mostly a rule-based application. Have a look at the following screenshots:

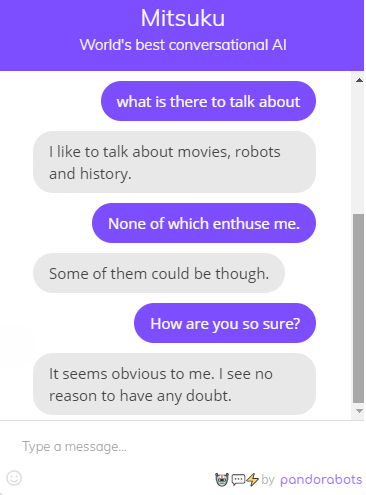
As you can see, this bot is able to hold simple conversations, just like a human. However, once you start asking technical questions or delve deeper into a topic, the quality of the responses deteriorates. This is expected, though, and we are still some time away from full human-like chatbots. You are encouraged to try engaging with Mitsuku in both simple and technical conversations and judge the accuracy yourself.
Sentiment analysis
Sentiment analysis is a set of algorithms and techniques used to detect the sentiment (positive, negative, or neutral) of a given text. This is a very powerful application of NLP and finds usage in a number of industries. Sentiment analysis has allowed entities to mine opinions from a much wider audience at significantly reduced costs. The traditional way of garnering feedback for companies has been through surveys, closed user group testing, and so on, which could be quite expensive. However, organizations can reduce costs by scraping data (from social media platforms or review-gathering sites) and using sentiment analysis to come up with an overall sentiment index of their products.
Here are some other examples of use cases of sentiment analysis:
- A stock investor scanning news about a company to assess overall market sentiment
- An individual scanning tweets about the launch of a new phone to decide the prevailing sentiment
- A political party analyzing social media feeds to assess the sentiment regarding their candidate
Sentiment analyzing systems can be simple lexicon-based (akin to a dictionary lookup) or ML-/DL-based. The choice of the method is dictated by business requirements, the respective pros and cons of each approach, and other development constraints. We will be covering the ML/DL based methods in detail in this book.
A simple Google search will yield numerous online sentiment analyzing sources such as paralleldots.com (https://www.paralleldots.com/sentiment-analysis).
You are encouraged to try submitting sentences or paragraphs to the tool and analyze the response. These tools will most likely do a reasonably good analysis of simple sentences or articles. However, the output for sentences with complex structures (double negation, rhetorical questions, qualifiers, and so on) will likely not be accurate. It should also be noted that before using a prebuilt sentiment analyzer, it is very important to understand the methodology and training dataset used to build that analyzer. You do not want to use a sentiment analyzer trained on movie review data to predict the sentiment of text from a different area (such as financial news articles or restaurant reviews), as words that carry a positive or negative context for one area may have a neutral or opposite polarity context for another area. For example, some words signifying a positive sentiment in financial news articles are bullish, green, expansion, and growth. However, these words, if used in a movie review context, would not be polarity-influencing words. Therefore, it is important to use suitable training data in order to build a sentiment analyzer.
We will delve deeper into sentiment analysis in Chapter 7, Identifying Patterns in Text Using Machine Learning, and will build a sentiment analyzer using product review data.
Machine translation
Language translation was one of the early problems NLP techniques tried to solve. At the height of the Cold War, there was a pressing need for American researchers to translate Russian documents into English using AI techniques. In 1964, the US government even created a multidisciplinary committee of leading scientists, linguists, and researchers to explore the feasibility of machine translation, and called the committee the Automatic Language Processing Advisory Committee (ALPAC). However, ALPAC was unable to make any significant breakthrough, which caused major skepticism around the feasibility of AI technology, leading to massive funding cuts and a reduced interest in AI research throughout the 1970s. This period is often called the AI Winter due to the significant drop in research output pertaining to AI. Although the efforts of ALPAC did not yield promising results back then, today, we have translators with a very high level of accuracy.
The high market value of the translation industry in the present era of highly interconnected communities and global businesses is self-evident. Although businesses still rely mostly on human translators to translate important documents such as legal contracts, the use of NLP techniques to translate conversations has been increasing.
The modern NLP approach toward document translation is rooted in DL and pattern detection, which has significantly increased the accuracy of translations. Google Translate (https://translate.google.co.in/) supposedly uses an Artificial Neural Network (ANN)-based system that predicts the possible sequence of the translated words.
We wanted to conduct a quick test of Google Translate's accuracy in translating a text from English to Hindi.
Here is a screenshot, showing the result:
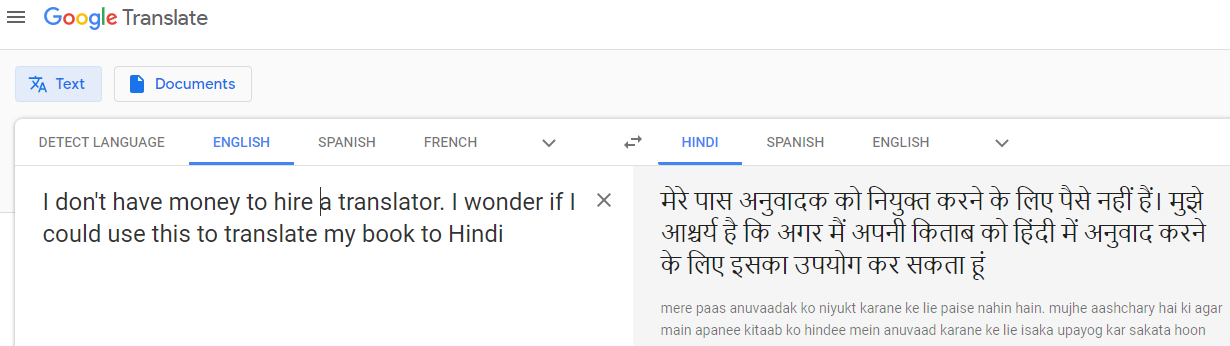
For readers who can read Hindi, the first sentence was translated perfectly. However, the second translated sentence is nonsensical. This could be because the usage of the word wonder in the sentence is not a wide one, and the training data possibly had all instances of wonder in a different context.
We thought it may be a good idea to see how other popular translators would translate the same sentence. The following screenshot shows the result derived from the Bing translator (https://www.bing.com/translator):
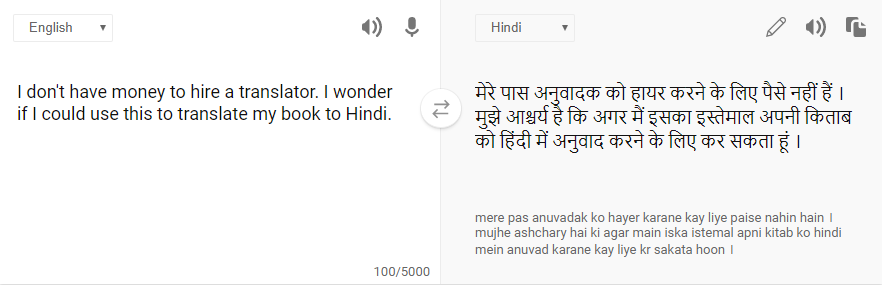
We found that the Bing translator's translation for our sentence was slightly inferior to that provided by Google Translate as, in addition to getting the context of the word wonder wrong, it was also unable to translate the word hire and simply transliterated it.
Finally, we tried the Babylon translator (https://translation.babylon-software.com/) with the same sentence. The following screenshot shows the result:
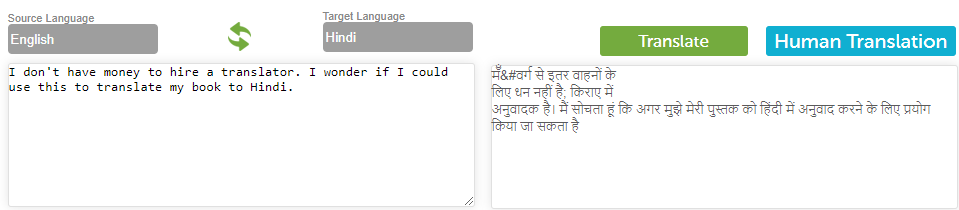
We found that the Babylon translator was unable to translate the sentence, as the output was gibberish.
It should be noted that the translation was instant in all three translators, meaning that the execution time for machine translation has greatly reduced. Based on our very unscientific testing, it is clear that while we have made huge strides in machine translation efficacy, there is still scope for improvement, and research in this area is still ongoing.
Named-entity recognition
When we read and process sentences, we tend to first identify the key players in the sentence (for example, people, places, and organizations). This classification helps us break down the sentence into entities and make sense of the semantics of the sentence. Named-entity recognition (NER) mimics the same behavior and is used to classify the named entities (or proper nouns) in a given text. The applications of this seemingly facile categorization are profound and are used extensively in the industry. Here are some real-world applications of NER:
- Text summarization: Scanning text documents and summarizing them by identifying key entities in the document. A popular use case is resume categorization, wherein the NER processes a large number of resumes and highlights key entities such as name, institution, and skills, which facilitates quick evaluation.
- Automatic indexing: Indexing is the method of organizing data for efficient retrieval. Using NER, documents are indexed based on underlying entities, which facilitates faster retrieval.
- Information extraction: Extracting relevant information (entities) from a document for faster processing. A use case is customer feedback processing, wherein key entities from feedback, such as product name and location are extracted for further processing. Typically, customer feedback processing also involves a sentiment analyzer that detects the tone of the feedback (positive or negative), and the NER then identifies the product, location, and so on, which is covered in the feedback. Such systems allow organizations to quickly process large volumes of customer feedback data and gain precision insights.
Stanford Named Entity Tagger (https://nlp.stanford.edu/software/CRF-NER.html) is a popular open source NER tool that comes with a default trained model that classifies entities such as Person, Location, and Organization. However, users can train their own models on the Stanford NER tool using a labeled dataset. The application is built on a linear chain Conditional Random Field (CRF) sequence model, which is a class of statistical modeling methods often used for pattern recognition. The software is written in Java and is available to download for free.
In addition, the trained model can also be accessed through a web interface. The following screenshot shows a sample sentence being processed by the Stanford NER web interface:

In this example, the NER tool did a decent job and correctly categorized the two persons (Virat Kohli and Sachin Tendulkar) and one location (India) mentioned in the sentence. It should be noted that there are other entities as well in the sentence shown in the preceding screenshot (for example, number and profession). However, the Stanford NER tool only recognizes four entities. The choice of the number of entities to be recognized depends on the training data and the model design.
Now, let's look at some promising future applications of NLP as well.
Future applications of NLP
Although we have made huge strides in improving NLP technologies, ongoing research continues to strive for improved accuracy and more optimized algorithms (for reduced response time). The objective continues to be moving toward more human-like applications. Here are some examples of technological advances and potential future applications in the area of NLP:
- BERT: BERT is a path-breaking technique for NLP research and development. It is being developed by Google and is a very clever amalgamation of a number of algorithms and techniques used in NLP (Transformer, ELMo, Semi-Supervised Sequence Learning, and so on). The paper, published by Google researchers, explaining this model can be accessed at https://arxiv.org/abs/1810.04805. At a high level, BERT tries to understand the context of a word by taking into account all surrounding words rather than an ordered sequence of words. For example, if the sentence Are you game for a cup of coffee? is analyzed by traditional NLP algorithms, they will analyze the word game by either looking at Are you game or at game for a cup of coffee. However, since BERT is bidirectional, it considers the entire sentence to decide the context of the word. BERT is open source and comes with rigorous pre trained models. BERT has significantly improved the efficiency and accuracy of building NLP models. We will get into the details of BERT in Chapter 11, State of the Art in NLP.
- Legal tech: The possibility of applying NLP technology to the legal profession is a very promising and lucrative prospect, and a lot of research is being conducted in this area. Given the vast number of legal documents lawyers need to pore through in order to retrieve required information for a case or the repetitive nature of perusing through legal contracts to ensure that they are correct, NLP can play a significant role in this field. However, most solutions to date remain in the Proof of Concept (PoC) phase, and adoption is minimal. However, many legal, tech-focused start-ups are springing up, trying to get a piece of a very lucrative developing market.
- Unstructured data: Most NLP tools rely on clean input data to be provided as input. However, the real world has a lot of unstructured data that needs analyzing. For example, a financial analyst may need to go through a company's annual financial filings, emails, call records, chat transcripts, news reports, complaint logs, and so on to prepare their report. Extracting relevant information from these unstructured data sources is a promising area of NLP application, and some exciting research in this area is ongoing.
- Text summarization: Research is underway around building applications that have the ability to read through a document, understand the context, and present a summary in a coherent way.













