






















































Missing values are caused by incomplete data. It is important to handle missing values effectively, as they can lead to inaccurate inferences and conclusions. In this section, we will look at how to analyze, visualize, and treat missing values.
Analyzing, visualizing, and treating missing values
How to do it...
Let's start by analyzing variables with missing values. Set the options in pandas to view all rows and columns, as shown in the previous section:
- With the following syntax, we can see which variables have missing values:
# Check which variables have missing values
columns_with_missing_values = housepricesdata.columns[housepricesdata.isnull().any()]
housepricesdata[columns_with_missing_values].isnull().sum()
This will produce the following output:

- You might also like to see the missing values in terms of percentages. To see the count and percentage of missing values, execute the following command:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# To hold variable names
labels = []
# To hold the count of missing values for each variable
valuecount = []
# To hold the percentage of missing values for each variable
percentcount = []
for col in columns_with_missing_values:
labels.append(col)
valuecount.append(housepricesdata[col].isnull().sum())
# housepricesdata.shape[0] will give the total row count
percentcount.append(housepricesdata[col].isnull().sum()/housepricesdata.shape[0])
ind = np.arange(len(labels))
fig, (ax1, ax2) = plt.subplots(1,2,figsize=(20,18))
rects = ax1.barh(ind, np.array(valuecount), color='blue')
ax1.set_yticks(ind)
ax1.set_yticklabels(labels, rotation='horizontal')
ax1.set_xlabel("Count of missing values")
ax1.set_title("Variables with missing values")
rects = ax2.barh(ind, np.array(percentcount), color='pink')
ax2.set_yticks(ind)
ax2.set_yticklabels(labels, rotation='horizontal')
ax2.set_xlabel("Percentage of missing values")
ax2.set_title("Variables with missing values")
It will show you the missing values in both absolute and percentage terms, as shown in the following screenshot:
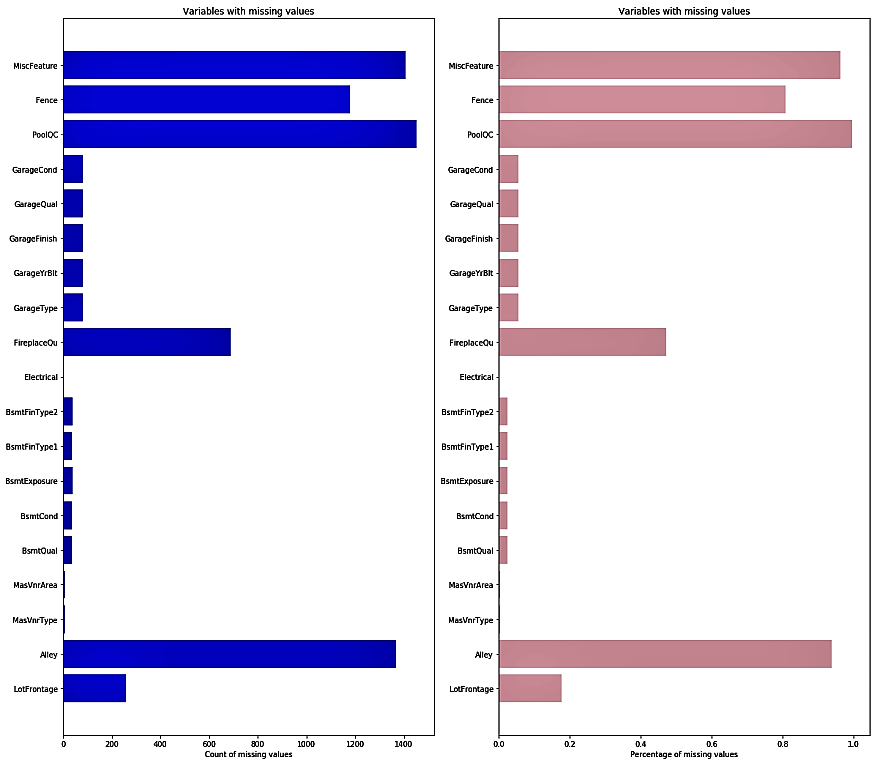
We notice that variables such as Alley, PoolQC, Fence, and MiscFeature have 80% to 90% of their values missing. FireplaceQu has 47.26% of its values missing. A few other variables, such as LotFrontage, MasVnrType, MasVnrArea, BsmtQual, BsmtCond, and a few more Garage-related variables have missing values as well.
But there is a catch. Let's look at the Alley variable again. It shows us that it has 93.76% missing values. Now take another look at the data description that we looked at in the preceding section. The variable description for Alley shows that it has three levels: gravel, paved, and no access. In the original dataset, 'No Access' is codified as NA. When NA is read in Python, it is treated as NaN, which means that a value is missing, so we need to be careful.
- Now, we will replace the missing values for Alley with a valid value, such as 'No Access':
# Replacing missing values with 'No Access' in Alley variable
housepricesdata['Alley'].fillna('No Access', inplace=True)
- Now, let's visualize the missing values and try to see how can we treat them. The following code generates a chart that showcases the spread of missing values. Here we use the seaborn library to plot the charts:
# Lets import seaborn. We will use seaborn to generate our charts
import seaborn as sns
# We will import matplotlib to resize our plot figure
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(20, 10))
# cubehelix palette is a part of seaborn that produces a colormap
cmap = sns.cubehelix_palette(light=1, as_cmap=True, reverse=True)
sns.heatmap(housepricesdata.isnull(), cmap=cmap)
The color of the map is generated with linearly increasing brightness by the cubehelix_palette() function:
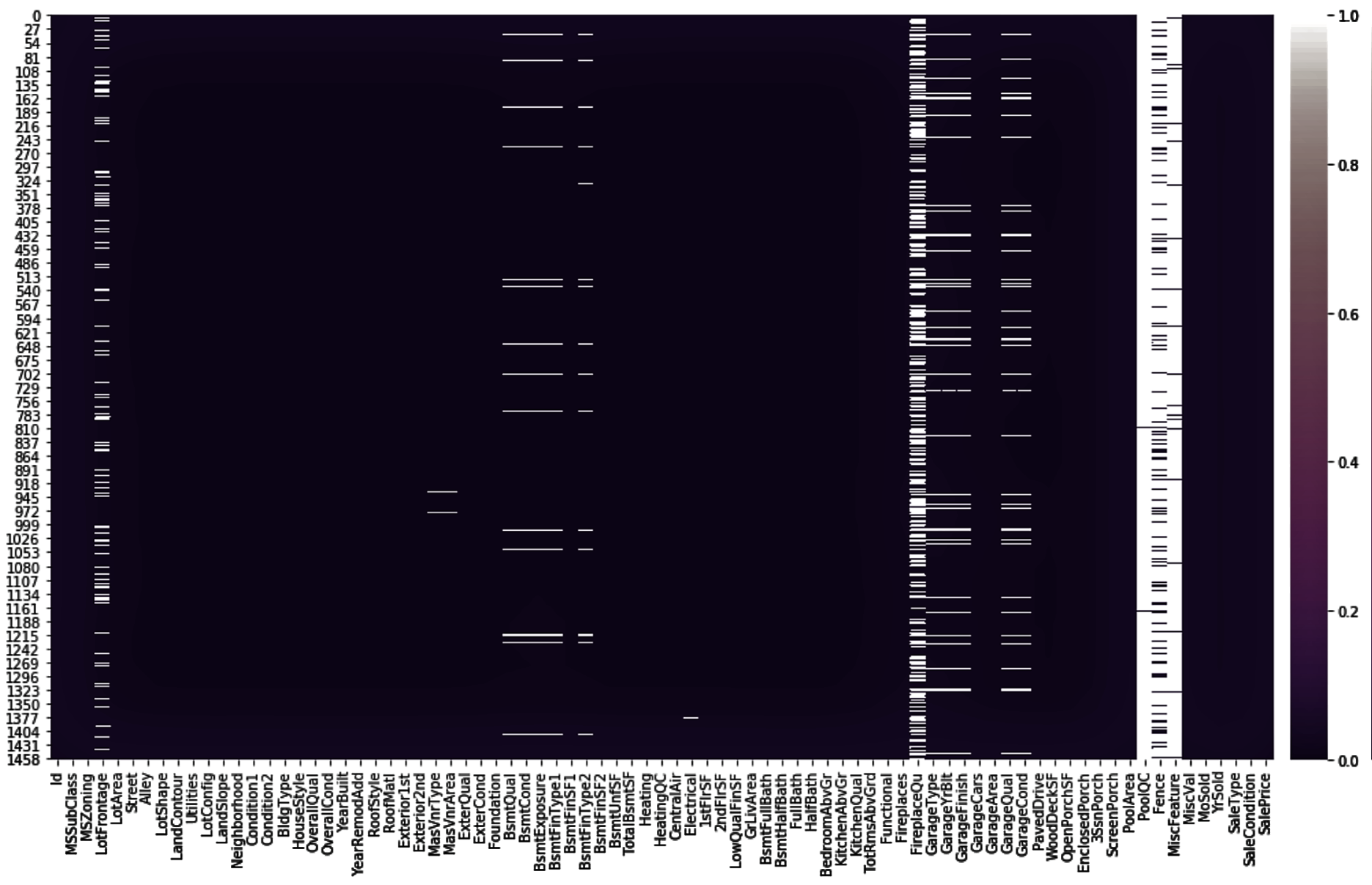
From the preceding plot, it is easier to read the spread of the missing values. The white marks on the chart indicate missing values. Notice that Alley no longer reports any missing values.
- LotFrontage is a continuous variable and has 17.74% of its values missing. Replace the missing values in this variable with its median as follows:
# Filling in the missing values in LotFrontage with its median value
housepricesdata['LotFrontage'].fillna(housepricesdata['LotFrontage'].median(), inplace=True)
- Let's view the missing value plot once again to see if the missing values from LotFrontage have been imputed. Copy and execute the preceding code. The missing value plot will look as follows:
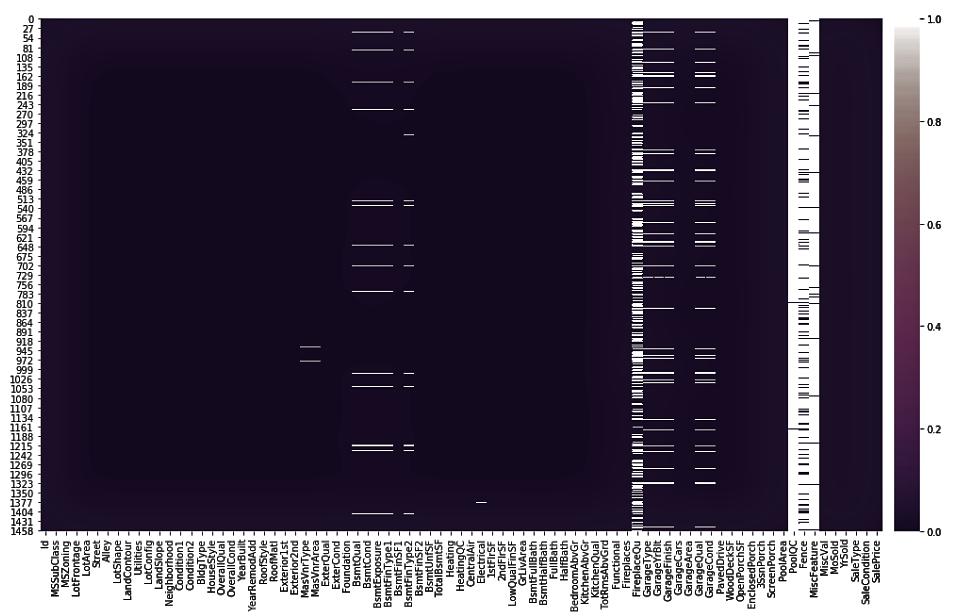
Here, we can see in the preceding plot that there are no more missing values for Alley or LotFrontage.
- We have figured out from the data description that several variables have values that are codified as NA. Because this is read in Python as missing values, we replace all of these with their actual values, which we get to see in the data description shown in the following code block:
# Replacing all NA values with their original meaning
housepricesdata['BsmtQual'].fillna('No Basement', inplace=True)
housepricesdata['BsmtCond'].fillna('No Basement', inplace=True)
housepricesdata['BsmtExposure'].fillna('No Basement', inplace=True)
housepricesdata['BsmtFinType1'].fillna('No Basement', inplace=True)
housepricesdata['BsmtFinType2'].fillna('No Basement', inplace=True)
housepricesdata['GarageYrBlt'].fillna(0, inplace=True)
# For observations where GarageType is null, we replace null values in GarageYrBlt=0
housepricesdata['GarageType'].fillna('No Garage', inplace=True)
housepricesdata['GarageFinish'].fillna('No Garage', inplace=True)
housepricesdata['GarageQual'].fillna('No Garage', inplace=True)
housepricesdata['GarageCond'].fillna('No Garage', inplace=True)
housepricesdata['PoolQC'].fillna('No Pool', inplace=True)
housepricesdata['Fence'].fillna('No Fence', inplace=True)
housepricesdata['MiscFeature'].fillna('None', inplace=True)
housepricesdata['FireplaceQu'].fillna('No Fireplace', inplace=True)
- Let's take a look at the missing value plot after having treated the preceding variables:
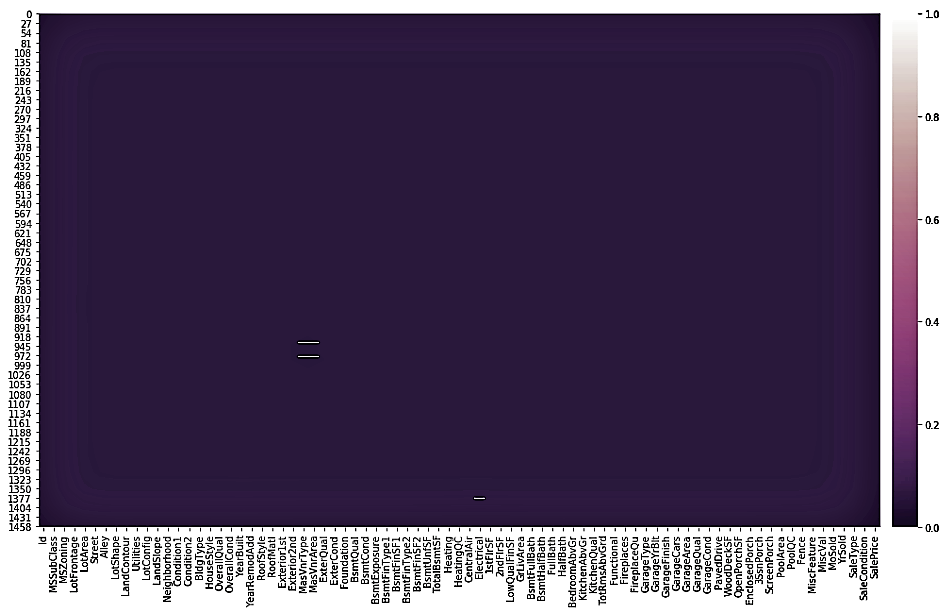
We notice from the preceding plot that there are no more missing values for the variables that we have just treated. However, we are left with a few missing values in MasVnrType, MasVnrArea, and Electrical.
- Let's try to look at the distribution of MasVnrType by MasVnrArea with a crosstab:
# Using crosstab to generate the count of MasVnrType by type of MasVnrArea
print(pd.crosstab(index=housepricesdata["MasVnrType"],\
columns=housepricesdata["MasVnrArea"], dropna=False, margins=True))
The following output shows that when MasVnrArea is zero, we have MasVnrType as None in the majority of cases:

- We will then impute the missing values in MasVnrType with None and MasVnrArea with zero. This is done with the commands shown in the following code block:
# Filling in the missing values for MasVnrType and MasVnrArea with None and 0 respectively
housepricesdata['MasVnrType'].fillna('None', inplace=True)
housepricesdata['MasVnrArea'].fillna(0, inplace=True)
We are still left with one missing value in the Electrical variable.
- Let's take a look at the observation where Electrical has a missing value:
housepricesdata['MSSubClass'][housepricesdata['Electrical'].isnull()]

- We see that MSSubClass is 80 when Electrical is null. Let's see the distribution of the Electrical type by MSSubClass:
# Using crosstab to generate the count of Electrical Type by MSSubClass
print(pd.crosstab(index=housepricesdata["Electrical"],\
columns=housepricesdata['MSSubClass'], dropna=False, margins=True))
From the following output, we can see that when MSSubClass is 80, the majority of cases of the Electrical type are SBrkr:
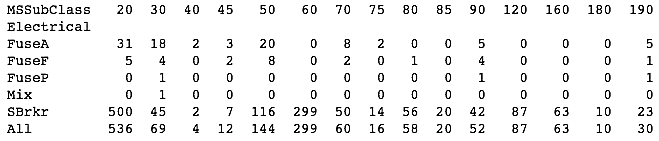
- Go ahead and impute the missing value in the Electrical variable with SBrKr by executing the following code:
housepricesdata['Electrical'].fillna('SBrkr', inplace=True)
- After this, let's take a look at our missing value plot for a final time:
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(20, 10))
cmap = sns.cubehelix_palette(light=1, as_cmap=True, reverse=True)
sns.heatmap(housepricesdata.isnull(), cmap=cmap)
The output we get can be seen in the following chart:

Notice that the plot has changed and now shows no missing values in our DataFrame.
How it works...
In Step 1 and Step 2, we looked at the variables with missing values in absolute and percentage terms. We noticed that the Alley variable had more than 93% of its values missing. However, from the data description, we figured out that the Alley variable had a No Access to Alley value, which is codified as NA in the dataset. When this value was read in Python, all instances of NA were treated as missing values. In Step 3, we replaced the NA in Alley with No Access.
Note that we used %matplotlib inline in Step 2. This is a magic function that renders the plot in the notebook itself.
In Step 4, we used the seaborn library to plot the missing value chart. In this chart, we identified the variables that had missing values. The missing values were denoted in white, while the presence of data was denoted in color. We noticed from the chart that Alley had no more missing values.
In Step 4, we used cubehelix_palette() from the seaborn library, which produces a color map with linearly decreasing (or increasing) brightness. The seaborn library also provides us with options including light_palette() and dark_palette(). light_palette() gives a sequential palette that blends from light to color, while dark_palette() produces a sequential palette that blends from dark to color.
In Step 5, we noticed that one of the numerical variables, LotFrontage, had more than 17% of its values missing. We decided to impute the missing values with the median of this variable. We revisited the missing value chart in Step 6 to see whether the variables were left with any missing values. We noticed that Alley and LotFrontage showed no white marks, indicating that neither of the two variables had any further missing values.
In Step 7, we identified a handful of variables that had data codified with NA. This caused the same problem we encountered previously, as Python treated them as missing values. We replaced all such codified values with actual information.
We then revisited the missing value chart in Step 8. We saw that almost all the variables then had no missing values, except for MasVnrType, MasVnrArea, and Electrical.
In Step 9 and 10, we filled in the missing values for the MasVnrType and MasVnrArea variables. We noticed that MasVnrType is None whenever MasVnrArea is 0.0, except for some rare occasions. So, we imputed the MasVnrType variable with None, and MasVnrArea with 0.0 wherever those two variables had missing values. We were then only left with one variable with missing values, Electrical.
In Step 11, we looked at what type of house was missing the Electrical value. We noticed that MSSubClass denoted the dwelling type and, for the missing Electrical value, the MSSubClass was 80, which meant it was split or multi-level. In Step 12, we checked the distribution of Electrical by the dwelling type, which was MSSubClass. We noticed that when MSSubClass equals 80, the majority of the values of Electrical are SBrkr, which stands for standard circuit breakers and Romex. For this reason, we decided to impute the missing value in Electrical with SBrkr.
Finally, in Step 14, we again revisited the missing value chart and saw that there were no more missing values in the dataset.
There's more...
Using the preceding plots and missing value charts, it was easy to figure out the count, percentage, and spread of missing values in the datasets. We noticed that many variables had missing values for the same observations. However, after consulting the data description, we saw that most of the missing values were actually not missing, but since they were codified as NA, pandas treated them as missing values.
It is very important for data analysts to understand data descriptions and treat the missing values appropriately.
Usually, missing data is categorized into three categories:
- Missing completely at random (MCAR): MCAR denotes that the missing values have nothing to do with the object being studied. In other words, data is MCAR when the probability of missing data on a variable is not related to other measured variables or to the values themselves. An example of this could be, for instance, the age of certain respondents to a survey not being recorded, purely by chance.
- Missing at random (MAR): The name MAR is a little misleading here because the absence of values is not random in this case. Data is MAR if its absence is related to other observed variables, but not to the underlying values of the data itself. For example, when we collect data from customers, rich customers are less likely to disclose their income than their other counterparts, resulting in MAR data.
- Missing not at random (MNAR): Data is MNAR, also known as non-ignorable if it can't be classified as MCAR nor MAR. For example, perhaps some consumers don't want to share their age when it is above 40 because they would like to hide it.
There are various strategies that can be applied to impute the missing values, as listed here:
- Source the missing data
- Leave out incomplete observations
- Replace missing data with an estimate, such as a mean or a median
- Estimate the missing data from other variables in the dataset
See also
- The scikit-learn module for imputation (https://bit.ly/2MzFwiG)
- Multiple imputation by chained equations using the StatsModels library in Python (https://bit.ly/2PYLuYy)
- Feature imputation algorithms using fancyimpute (https://bit.ly/2MJKfOY)




