






















































Building a neural evolutionary agent
Evolutionary methods are based on black-box optimization and are also known as gradient-free methods since no gradient computation is involved. This recipe will walk you through the steps for implementing a simple, approximate cross-entropy-based neural evolutionary agent using TensorFlow 2.x.
Getting ready
Activate the tf2rl-cookbook Python environment and import the following packages necessary to run this recipe:
from collections import namedtuple import gym import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from tqdm import tqdm import envs
With the packages installed, we are ready to begin.
How to do it…
Let's put together all that we have learned in this chapter to build a neural agent that improves its policy to navigate the Gridworld environment using an evolutionary process:
- Let's start by importing the basic neural agent and the Brain class from
neural_agent.py:from neural_agent import Agent, Brain from envs.gridworld import GridworldEnv
- Next, let's implement a method to roll out the agent in a given environment for one episode and return
obs_batch,actions_batch, andepisode_reward:def rollout(agent, env, render=False): obs, episode_reward, done, step_num = env.reset(), 0.0, False, 0 observations, actions = [], [] episode_reward = 0.0 while not done: action = agent.get_action(obs) next_obs, reward, done, info = env.step(action) # Save experience observations.append(np.array(obs).reshape(1, -1)) # Convert to numpy & reshape (8, 8) to (1, 64) actions.append(action) episode_reward += reward obs = next_obs step_num += 1 if render: env.render() env.close() return observations, actions, episode_reward
- Let's now test the trajectory rollout method:
env = GridworldEnv() # input_shape = (env.observation_space.shape[0] * \ env.observation_space.shape[1], ) brain = Brain(env.action_space.n) agent = Agent(brain) obs_batch, actions_batch, episode_reward = rollout(agent, env)
- Now, it's time for us to verify that the experience data generated using the rollouts is coherent:
assert len(obs_batch) == len(actions_batch)
- Let's now roll out multiple complete trajectories to collect experience data:
# Trajectory: (obs_batch, actions_batch, episode_reward) # Rollout 100 episodes; Maximum possible steps = 100 * 100 = 10e4 trajectories = [rollout(agent, env, render=True) \ for _ in tqdm(range(100))]
- We can then visualize the reward distribution from a sample of experience data. Let's also plot a red vertical line at the 50th percentile of the episode reward values in the collected experience data:
from tqdm.auto import tqdm import matplotlib.pyplot as plt %matplotlib inline sample_ep_rewards = [rollout(agent, env)[-1] for _ in \ tqdm(range(100))] plt.hist(sample_ep_rewards, bins=10, histtype="bar");
Running this code will generate a plot like the one shown in the following diagram:
Figure 1.13 – Histogram plot of the episode reward values
- Let's now create a container for storing trajectories:
from collections import namedtuple Trajectory = namedtuple("Trajectory", ["obs", "actions", "reward"]) # Example for understanding the operations: print(Trajectory(*(1, 2, 3))) # Explanation: `*` unpacks the tuples into individual # values Trajectory(*(1, 2, 3)) == Trajectory(1, 2, 3) # The rollout(...) function returns a tuple of 3 values: # (obs, actions, rewards) # The Trajectory namedtuple can be used to collect # and store mini batch of experience to train the neuro # evolution agent trajectories = [Trajectory(*rollout(agent, env)) \ for _ in range(2)] - Now it's time to choose elite experiences for the evolution process:
def gather_elite_xp(trajectories, elitism_criterion): """Gather elite trajectories from the batch of trajectories Args: batch_trajectories (List): List of episode \ trajectories containing experiences (obs, actions,episode_reward) Returns: elite_batch_obs elite_batch_actions elite_reard_threshold """ batch_obs, batch_actions, batch_rewards = zip(*trajectories) reward_threshold = np.percentile(batch_rewards, elitism_criterion) indices = [index for index, value in enumerate( batch_rewards) if value >= reward_threshold] elite_batch_obs = [batch_obs[i] for i in indices] elite_batch_actions = [batch_actions[i] for i in \ indices] unpacked_elite_batch_obs = [item for items in \ elite_batch_obs for item in items] unpacked_elite_batch_actions = [item for items in \ elite_batch_actions for item in items] return np.array(unpacked_elite_batch_obs), \ np.array(unpacked_elite_batch_actions), \ reward_threshold
- Let's now test the elite experience gathering routine:
elite_obs, elite_actions, reward_threshold = gather_elite_xp(trajectories, elitism_criterion=75)
- Let's now look at implementing a helper method to convert discrete action indices to one-hot encoded vectors or probability distribution over actions:
def gen_action_distribution(action_index, action_dim=5): action_distribution = np.zeros(action_dim).\ astype(type(action_index)) action_distribution[action_index] = 1 action_distribution = \ np.expand_dims(action_distribution, 0) return action_distribution
- It's now time to test the action distribution generation function:
elite_action_distributions = np.array([gen_action_distribution(a.item()) for a in elite_actions])
- Now, let's create and compile the neural network brain with TensorFlow 2.x using the Keras functional API:
brain = Brain(env.action_space.n) brain.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
- You can now test the brain training loop as follows:
elite_obs, elite_action_distributions = elite_obs.astype("float16"), elite_action_distributions.astype("float16") brain.fit(elite_obs, elite_action_distributions, batch_size=128, epochs=1);This should produce the following output:
1/1 [==============================] - 0s 960us/step - loss: 0.8060 - accuracy: 0.4900
Note
The numbers may vary.
- The next big step is to implement an agent class that can be initialized with a brain to act in an environment:
class Agent(object): def __init__(self, brain): """Agent with a neural-network brain powered policy Args: brain (keras.Model): Neural Network based \ model """ self.brain = brain self.policy = self.policy_mlp def policy_mlp(self, observations): observations = observations.reshape(1, -1) action_logits = self.brain.process(observations) action = tf.random.categorical( tf.math.log(action_logits), num_samples=1) return tf.squeeze(action, axis=1) def get_action(self, observations): return self.policy(observations)
- Next, we will implement a helper function to evaluate the agent in a given environment:
def evaluate(agent, env, render=True): obs, episode_reward, done, step_num = env.reset(), 0.0, False, 0 while not done: action = agent.get_action(obs) obs, reward, done, info = env.step(action) episode_reward += reward step_num += 1 if render: env.render() return step_num, episode_reward, done, info
- Let's now test the agent evaluation loop:
env = GridworldEnv() agent = Agent(brain) for episode in tqdm(range(10)): steps, episode_reward, done, info = evaluate(agent, env) env.close()
- As a next step, let's define the parameters for the training loop:
total_trajectory_rollouts = 70 elitism_criterion = 70 # percentile num_epochs = 200 mean_rewards = [] elite_reward_thresholds = []
- Let's now create the
environment,brain, andagentobjects:env = GridworldEnv() input_shape = (env.observation_space.shape[0] * \ env.observation_space.shape[1], ) brain = Brain(env.action_space.n) brain.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) agent = Agent(brain) for i in tqdm(range(num_epochs)): trajectories = [Trajectory(*rollout(agent, env)) \ for _ in range(total_trajectory_rollouts)] _, _, batch_rewards = zip(*trajectories) elite_obs, elite_actions, elite_threshold = \ gather_elite_xp(trajectories, elitism_criterion=elitism_criterion) elite_action_distributions = \ np.array([gen_action_distribution(a.item()) \ for a in elite_actions]) elite_obs, elite_action_distributions = \ elite_obs.astype("float16"), elite_action_distributions.astype("float16") brain.fit(elite_obs, elite_action_distributions, batch_size=128, epochs=3, verbose=0); mean_rewards.append(np.mean(batch_rewards)) elite_reward_thresholds.append(elite_threshold) print(f"Episode#:{i + 1} elite-reward-\ threshold:{elite_reward_thresholds[-1]:.2f} \ reward:{mean_rewards[-1]:.2f} ") plt.plot(mean_rewards, 'r', label="mean_reward") plt.plot(elite_reward_thresholds, 'g', label="elites_reward_threshold") plt.legend() plt.grid() plt.show()This will generate a plot like the one shown in the following diagram:
Important note
The episode rewards will vary and the plots may look different.
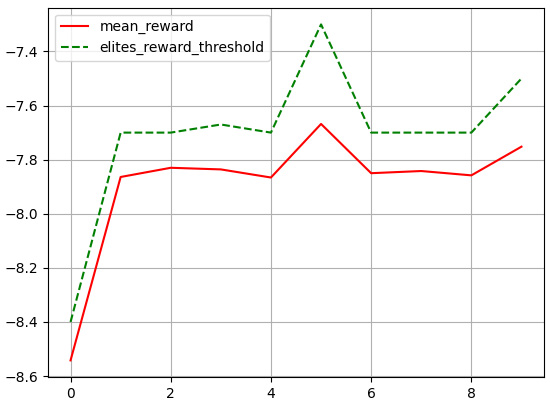
Figure 1.14 – Plot of the mean reward (solid, red) and reward threshold for elites (dotted, green)
The solid line in the plot is the mean reward obtained by the neural evolutionary agent, and the dotted line shows the reward threshold used for determining the elites.
How it works…
On every iteration, the evolutionary process rolls out or collects a bunch of trajectories to build up the experience data using the current set of neural weights in the agent's brain. An elite selection process is then employed that picks the top k percentile (elitism criterion) trajectories/experiences based on the episode reward obtained in that trajectory. This shortlisted experience data is then used to update the agent's brain model. The process repeats for a preset number of iterations allowing the agent's brain model to improve and collect more rewards.
See also
For more information, I suggest reading The CMA Evolution Strategy: A Tutorial: https://arxiv.org/pdf/1604.00772.pdf.





