






















































Building a neural agent
This recipe will guide you through the steps to build a complete agent and the agent-environment interaction loop, which is the main building block for any RL application. When you complete the recipe, you will have an executable script where a simple agent tries to act in a Gridworld environment. A glimpse of what the agent you build will likely be doing is shown in the following screenshot:
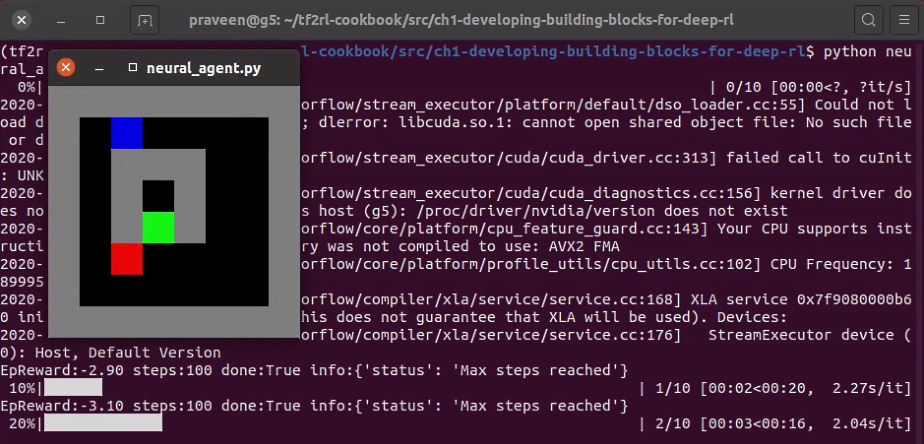
Figure 1.11 – Screenshot of output from the neural_agent.py script
Getting ready
Let's get started by activating the tf2rl-cookbook Conda Python environment and running the following code to install and import the necessary Python modules:
pip install tensorflow gym tqdm # Run this line in a terminal import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import gym import envs from tqdm import tqdm
How to do it…
We will start by implementing a Brain class powered by a neural network implemented using TensorFlow 2.x:
- Let's first initialize a neural brain model using TensorFlow 2.x and the Keras functional API:
class Brain(keras.Model): def __init__(self, action_dim=5, input_shape=(1, 8 * 8)): """Initialize the Agent's Brain model Args: action_dim (int): Number of actions """ super(Brain, self).__init__() self.dense1 = layers.Dense(32, input_shape= \ input_shape, activation="relu") self.logits = layers.Dense(action_dim)
- Next, we implement the Brain class's
call(…)method:def call(self, inputs): x = tf.convert_to_tensor(inputs) if len(x.shape) >= 2 and x.shape[0] != 1: x = tf.reshape(x, (1, -1)) return self.logits(self.dense1(x))
- Now we need to implement the Brain class's
process()method to conveniently perform predictions on a batch of inputs/observations:def process(self, observations): # Process batch observations using `call(inputs)` # behind-the-scenes action_logits = \ self.predict_on_batch(observations) return action_logits
- Let's now implement the init function of the agent class:
class Agent(object): def __init__(self, action_dim=5, input_shape=(1, 8 * 8)): """Agent with a neural-network brain powered policy Args: brain (keras.Model): Neural Network based model """ self.brain = Brain(action_dim, input_shape) self.policy = self.policy_mlp
- Now let's define a simple policy function for the agent:
def policy_mlp(self, observations): observations = observations.reshape(1, -1) # action_logits = self.brain(observations) action_logits = self.brain.process(observations) action = tf.random.categorical(tf.math.\ log(action_logits), num_samples=1) return tf.squeeze(action, axis=1)
- After that, let's implement a convenient
get_actionmethod for the agent:def get_action(self, observations): return self.policy(observations)
- Let's now create a placeholder function for
learn()that will be implemented as part of RL algorithm implementation in future recipes:def learn(self, samples): raise NotImplementedError
This completes our basic agent implementation with the necessary ingredients!
- Let's now evaluate the agent in a given environment for one episode:
def evaluate(agent, env, render=True): obs, episode_reward, done, step_num = env.reset(), 0.0, False, 0 while not done: action = agent.get_action(obs) obs, reward, done, info = env.step(action) episode_reward += reward step_num += 1 if render: env.render() return step_num, episode_reward, done, info
- Finally, let's implement the main function:
if __name__ == "__main__": env = gym.make("Gridworld-v0") agent = Agent(env.action_space.n, env.observation_space.shape) for episode in tqdm(range(10)): steps, episode_reward, done, info = \ evaluate(agent, env) print(f"EpReward:{episode_reward:.2f}\ steps:{steps} done:{done} info:{info}") env.close() - Execute the script as follows:
python neural_agent.py
You should see the Gridworld environment GUI pop up. This will show you what the agent is doing in the environment, and it will look like the following screenshot:
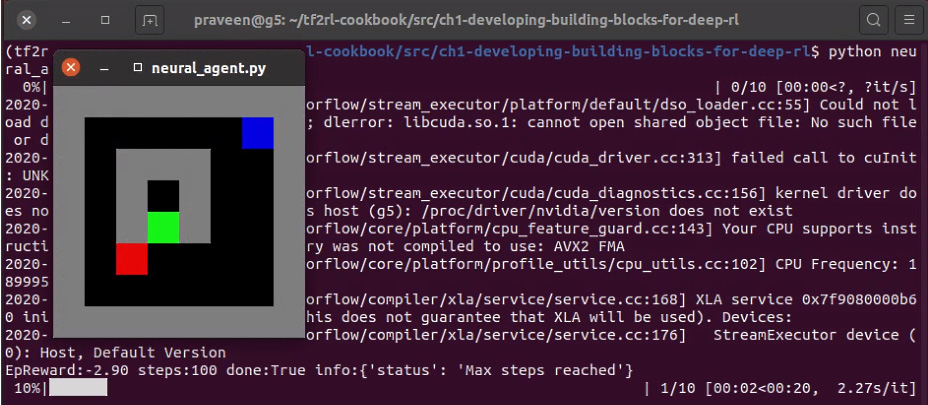
Figure 1.12 – A screenshot of the neural agent acting in the Gridworld environment
This provides a simple, yet complete, recipe to build an agent and the agent-environment interaction loop. All that is left is to add the RL algorithm of your choice to the learn() method and the agent will start acting intelligently!
How it works…
This recipe puts together the necessary ingredients to build a complete agent-environment system. The Brain class implements the neural network that serves as the processing unit of the agent, and the agent class utilizes the Brain class and a simple policy that chooses an action based on the output of the brain after processing the observations received from the environment.
We implemented the Brain class as a subclass of the keras.Model class, which allows us to define a custom neural network-based model for the agent's brain. The __init__ method initializes the Brain model and defines the necessary layers using the TensorFlow 2.x Keras functional API. In this Brain model, we are creating two dense (also known as fully-connected) layers to build our starter neural network. In addition to the __init__ method, the call(…) method is also a mandatory method that needs to be implemented by child classes inheriting from the keras.Model class. The call(…) method first converts the inputs to a TensorFlow 2.x tensor and then flattens the inputs to be of the shape 1 x total_number_of_elements in the input tensor. For example, if the input data has a shape of 8 x 8 (8 rows and 8 columns), the data is first converted to a tensor and the shape is flattened to 1 x 8 * 8 = 1 x 64. The flattened inputs are then processed by the dense1 layer, which contains 32 neurons and a ReLU activation function. Finally, the logits layer processes the output from the previous layer and produces n number of outputs corresponding to the action dimension (n).
The predict_on_batch(…) method performs predictions on the batch of inputs given as the argument. This function (unlike the predict() function of Keras) assumes that the inputs (observations) provided as the argument are exactly one batch of inputs and thus feeds the batch to the network without any further splitting of the input data.
We then implemented the Agent class and, in the agent initialization function, we created an object instance of the Brain class by defining the following:
self.brain = Brain(action_dim, input_shape)
Here, input_shape is the shape of the input that is expected to be processed by the brain, and action_dim is the shape of the output expected from the brain. The agent's policy is defined to be a custom Multi-Layer Perceptron (MLP)-based policy based on the brain's neural network architecture. Note that we can reuse DiscretePolicy from the previous recipe to initialize the agent's policy as well.
The agent's policy function, policy_mlp, flattens the input observations and sends it for processing by the agent's brain to receive the action_logits, which are the unnormalized probabilities for the actions. The final action to be taken is obtained by using TensorFlow 2.x's categorical method from the random module, which samples a valid action from the given action_logits (unnormalized probabilities).
Important note
If all of the observations supplied to the predict_on_batch function cannot be accommodated in the given amount of GPU memory or RAM (CPU), the operation can cause a GPU Out Of Memory (OOM) error.
The main function that gets launched – if the neural_agent.py script is run directly – creates an instance of the Gridworld-v0 environment, initializes an agent using the action and observation space of this environment, and starts evaluating the agent for 10 episodes.





