






















































TF-IDF stands for Term Frequency-Inverse Document Frequency. It has two segments: Term Frequency (TF) and Inverse Document Frequency (IDF). TF only counts the occurrence of words in each document. It is equivalent to BoW. TF does not consider the context of words and is biased toward longer documents. IDF computes values that correspond to the amount of information kept by a word.
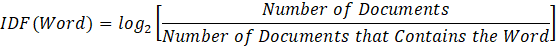
TF-IDF is the dot product of both segments – TF and IDF. TF-IDF normalizes the document weights. A higher value of TF-IDF for a word represents a higher occurrence in that document. Let's take the following three documents:
Document 1: I like pizza.
Document 2: I do not like burgers.
Document 3: Pizza and burgers both are junk food.
Now, we will create the DTM. This matrix consists of the document name in the row headers, the words in the column headers, and the TF-IDF values in the cells:
|
I |
like |
pizza |
do |
not |
burgers |
and |
both |
are |
junk |
food |
|





