When designing microservices, a common point of confusion is how big or small a service should be. This confusion can lead engineers to focus on things such as the number of lines of code in a particular service. Lines of code are an awful metric for measuring software; it's much more useful to focus on the role that a service plays, both in terms of the business capability it provides and the domain objects it helps manage. We want to design services that have low coupling with other services, because this limits what we have to change when introducing a new feature in our product or making changes to an existing one. We also want to give services a single responsibility.
When decomposing a monolith, it's often useful to look at the data model when deciding what services to extract. In our fictional image-messaging application, we can imagine the following data model:
We have a table for messages, a table for users, and a table for attachments. The Message entity has a one-to-many relationship with the User entity; every user can have many messages that originate from or are targeted at them, and every message can have multiple attachments. What happens as the application evolves and we add more features? The preceding data model does not include anything about social graphs. Let's imagine that we want a user to be able to follow other users. We'll define the following as a asymmetric relationship, just because user 1 follows user 2, that does not mean that user 2 follows user 1.
There are a number of ways to model this kind of relationship; we'll focus on one of the simplest, which is an adjacency list. Take a look at the following diagram:
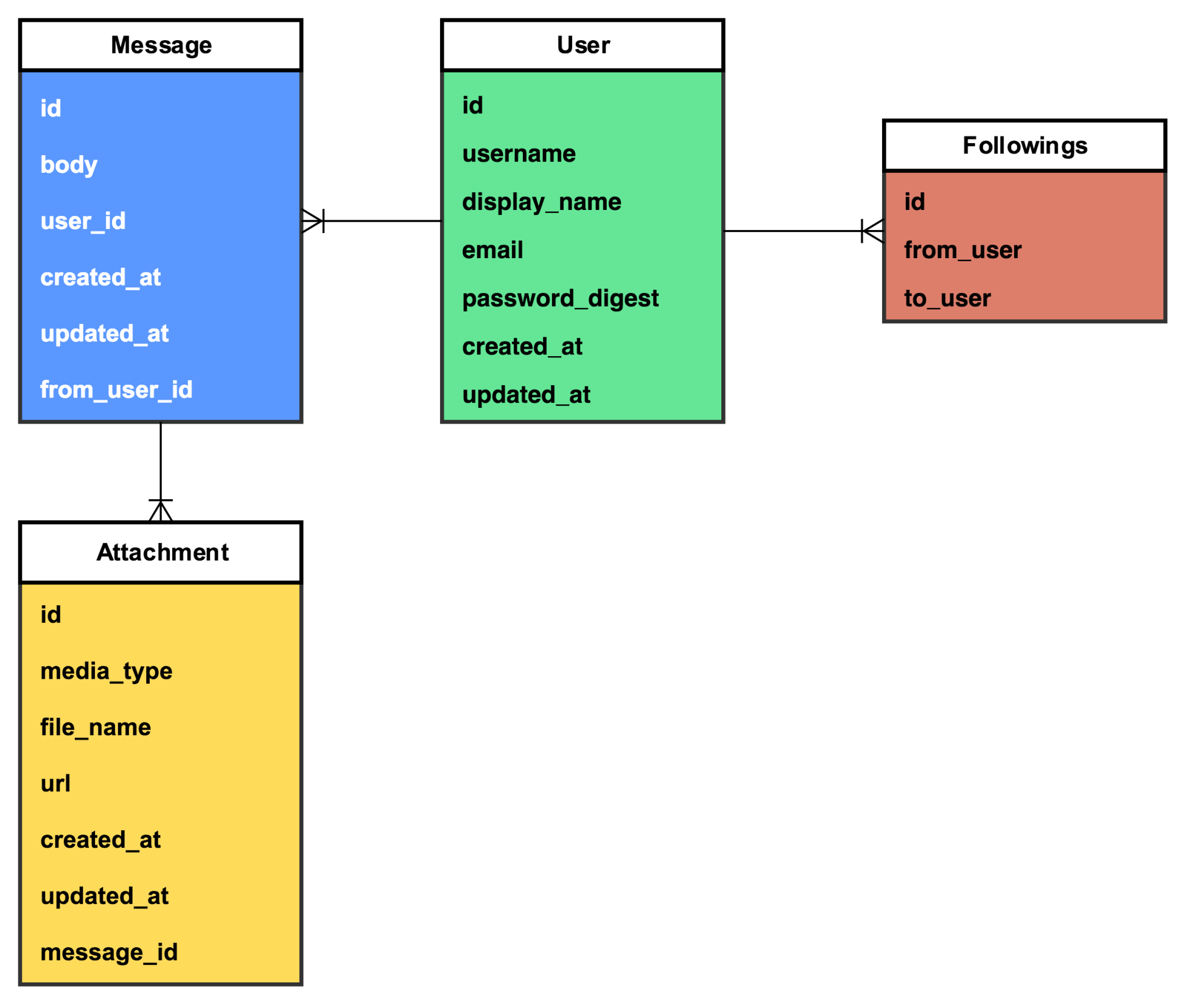
We now have an entity, Followings, to represent a follow relationship between two users. This works perfectly in our monolith, but introduces a challenge with microservices. If we were to build two new services, one to handle attachments, and another to handle the social graph (two distinct responsibilities), we now have two definitions of the user. This duplication of models is often necessary. The alternative is to have multiple services access and make updates to the same model, which is extremely brittle and can quickly lead to unreliable code.
This is where bounded contexts can help. A bounded context is a term from Domain-Driven Design (DDD) and it defines the area of a system within which a particular model makes sense. In the preceding example, the social-graph service would have a User model whose bounded context would be the users social graph (easy enough). The media service would have a User model whose bounded context would be photos and videos. Identifying these bounded contexts is important, especially when deconstructing a monolith—you'll often find that as a monolithic code base grows, the previously discussed business capabilities (uploading and viewing photos and videos, and user relationships) would probably end up sharing the same, bloated User model, which will then have to be untangled. This can be a tricky but enlightening and important process.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Japan
Japan
 Slovakia
Slovakia



















