






















































A data flow graph or computation graph is the basic unit of computation in TensorFlow. We will refer to them as the computation graph from now on. A computation graph is made up of nodes and edges. Each node represents an operation (tf.Operation) and each edge represents a tensor (tf.Tensor) that gets transferred between the nodes.
A program in TensorFlow is basically a computation graph. You create the graph with nodes representing variables, constants, placeholders, and operations and feed it to TensorFlow. TensorFlow finds the first nodes that it can fire or execute. The firing of these nodes results in the firing of other nodes, and so on.
Thus, TensorFlow programs are made up of two kinds of operations on computation graphs:
- Building the computation graph
- Running the computation graph
The TensorFlow comes with a default graph. Unless another graph is explicitly specified, a new node gets implicitly added to the default graph. We can get explicit access to the default graph using the following command:
graph = tf.get_default_graph()
For example, if we want to define three inputs and add them to produce output  , we can represent it using the following computation graph:
, we can represent it using the following computation graph:
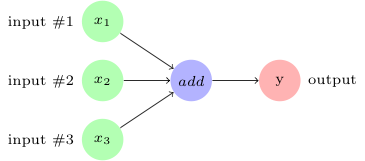
In TensorFlow, the add operation in the preceding image would correspond to the code y = tf.add( x1 + x2 + x3 ).
As we create the variables, constants, and placeholders, they get added to the graph. Then we create a session object to execute the operation objects and evaluate the tensor objects.
Let's build and execute a computation graph to calculate  , as we already saw in the preceding example:
, as we already saw in the preceding example:
# Assume Linear Model y = w * x + b
# Define model parameters
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Define model input and output
x = tf.placeholder(tf.float32)
y = w * x + b
output = 0
with tf.Session() as tfs:
# initialize and print the variable y
tf.global_variables_initializer().run()
output = tfs.run(y,{x:[1,2,3,4]})
print('output : ',output)
Creating and using a session in the with block ensures that the session is automatically closed when the block is finished. Otherwise, the session has to be explicitly closed with the tfs.close() command, where tfs is the session name.



