






















































Installing spaCy's statistical models
The spaCy installation doesn't come with the statistical language models needed for the spaCy pipeline tasks. spaCy language models contain knowledge about a specific language collected from a set of resources. Language models let us perform a variety of NLP tasks, including POS tagging and named-entity recognition (NER).
Different languages have different models and are language specific. There are also different models available for the same language. We'll see the differences between those models in detail in the Pro tip at the end of this section, but basically the training data is different. The underlying statistical algorithm is the same. Some of the currently supported languages are as follows:
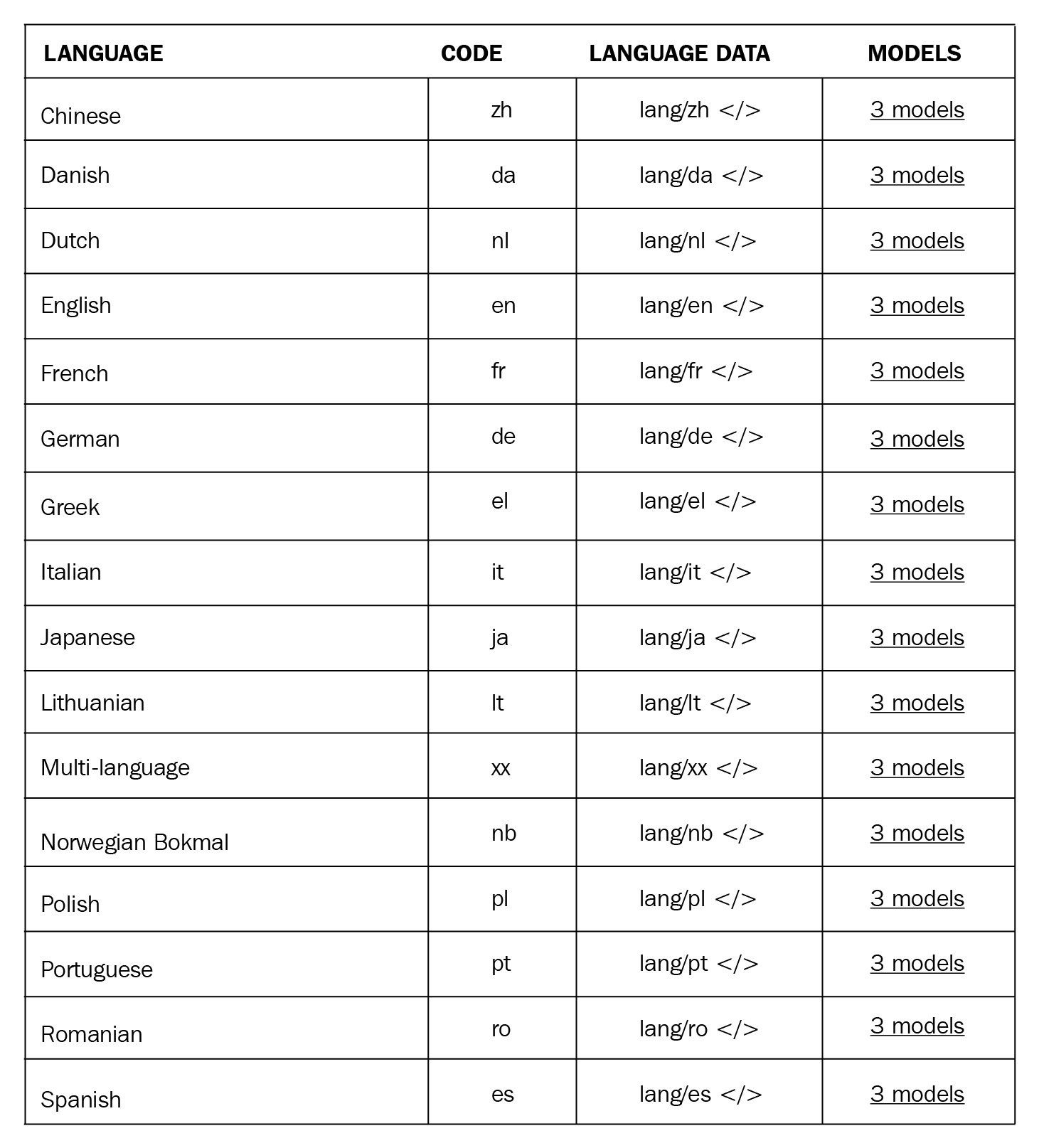
Figure 1.9 – spaCy models overview
The number of supported languages grows rapidly. You can follow the list of supported languages on the spaCy Models and Languages page (https://spacy.io/usage/models#languages).
Several pretrained models are available for different languages. For English, the following models are available for download: en_core_web_sm, en_core_web_md, and en_core_web_lg. These models use the following naming convention:
- Language: Indicates the language code:
enfor English,defor German, and so on. - Type: Indicates the model capability. For instance,
coremeans a general-purpose model for the vocabulary, syntax, entities, and vectors. - Genre: The type of text the model recognizes. The genre can be
web(Wikipedia),news(news, media)Twitter, and so on. - Size: Indicates the model size:
lgfor large,mdfor medium, andsmfor small.
Here is what a typical language model looks like:

Figure 1.10 – The small-sized spaCy English web model
Large models can require a lot of disk space, for example en_core_web_lg takes up 746 MB, while en_core_web_md needs 48MB and en_core_web_sm takes only 11MB. Medium-sized models work well for many development purposes, so we'll use the English md model throughout the book.
Pro tip
It is a good practice to match model genre to your text type. We recommend picking the genre as close as possible to your text. For example, the vocabulary in the social media genre will be very different from that in the Wikipedia genre. You can pick the web genre if you have social media posts, newspaper articles, financial news – that is, more language from daily life. The Wikipedia genre is suitable for rather formal articles, long documents, and technical documents. In case you are not sure which genre is the most suitable, you can download several models and test some example sentences from your own corpus and see how each model performs.
Now that we're well-informed about how to choose a model, let's download our first model.
Installing language models
Since v1.7.0, spaCy offers a great benefit: installing the models as Python packages. You can install spaCy models just like any other Python module and make them a part of your Python application. They're properly versioned, so they can go into your requirements.txt file as a dependency. You can install the models from a download URL or a local director manually, or via pip. You can put the model data anywhere on your local filesystem.
You can download a model via spaCy's download command. download looks for the most compatible model for your spaCy version, and then downloads and installs it. This way you don't need to bother about any potential mismatch between the model and your spaCy version. This is the easiest way to install a model:
$ python -m spacy download en_core_web_md
The preceding command selects and downloads the most compatible version of this specific model for your local spaCy version.
To download the exact model version, the following is what needs to be done (though you often don't need it):
$ python -m spacy download en_core_web_lg-2.0.0 --direct
The download command deploys pip behind the scenes. When you make a download, pip installs the package and places it in your site-packages directory just as any other installed Python package.
After the download, we can load the packages via spaCy's load () method.
This is what we did so far:
$ pip install spacy
$ python -m spacy download en_core_web_md
import spacy
nlp = spacy.load('en_core_web_md')
doc = nlp('I have a ginger cat.')
We can also download models via pip:
- First, we need the link to the model we want to download.
- We navigate to the model releases (https://github.com/explosion/spacy-models/releases), find the model, and copy the archive file link.
- Then, we do a
pip installwith the model link.
Here is an example command for downloading with a custom URL:
$ pip install https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-2.0.0/en_core_web_lg-2.0.0.tar.gz
You can install a local file as follows:
$ pip install /Users/yourself/en_core_web_lg-2.0.0.tar.gz
This installs the model into your site-packages directory. Then we run spacy.load() to load the model via its package name, create a shortcut link to give it a custom name (usually a shorter name), or import it as a module.
Importing the language model as a module is also possible:
import en_core_web_md
nlp = en_core_web_md.load()
doc = nlp('I have a ginger cat.')
Pro tip
In professional software development, we usually download models as part of an automated pipeline. In this case, it's not feasible to use spaCy's download command; rather, we use pip with the model URL. You can add the model into your requirements.txt file as a package as well.
How you like to load your models is your choice and also depends on the project requirements you're working on.
At this point, we're ready to explore the spaCy world. Let's now learn about spaCy's powerful visualization tool, displaCy.


