






















































Exploring the PyTorch library
PyTorch is a machine learning library for Python based on the Torch library. PyTorch is extensively used as a deep learning tool both for research as well as building industrial applications. It is primarily developed by Facebook's machine learning research labs. PyTorch is competition for the other well-known deep learning library – TensorFlow, which is developed by Google. The initial difference between these two was that PyTorch was based on eager execution whereas TensorFlow was built on graph-based deferred execution. Although, TensorFlow now also provides an eager execution mode.
Eager execution is basically an imperative programming mode where mathematical operations are computed immediately. A deferred execution mode would have all the operations stored in a computational graph without immediate calculations and then the entire graph would be evaluated later. Eager execution is considered advantageous for reasons such as intuitive flow, easy debugging, and less scaffolding code.
PyTorch is more than just a deep learning library. With its NumPy-like syntax/interface, it provides tensor computation capabilities with strong acceleration using GPUs. But what is a tensor? Tensors are computational units, very similar to NumPy arrays, except that they can also be used on GPUs to accelerate computing.
With accelerated computing and the facility to create dynamic computational graphs, PyTorch provides a complete deep learning framework. Besides all that, it is truly Pythonic in nature, which enables PyTorch users to exploit all the features Python provides, including the extensive Python data science ecosystem.
In this section, we will take a look at some of the useful PyTorch modules that extend various functionalities helpful in loading data, building models, and specifying the optimization schedule during the training of a model. We will also expand on what a tensor is and how it is implemented with all of its attributes in PyTorch.
PyTorch modules
The PyTorch library, besides offering the computational functions as NumPy does, also offers a set of modules that enable developers to quickly design, train, and test deep learning models. The following are some of the most useful modules.
torch.nn
When building a neural network architecture, the fundamental aspects that the network is built on are the number of layers, the number of neurons in each layer, and which of those are learnable, and so on. The PyTorch nn module enables users to quickly instantiate neural network architectures by defining some of these high-level aspects as opposed to having to specify all the details manually. The following is a one-layer neural network initialization without using the nn module:
import math # we assume a 256-dimensional input and a 4-dimensional output for this 1-layer neural network # hence, we initialize a 256x4 dimensional matrix filled with random values weights = torch.randn(256, 4) / math.sqrt(256) # we then ensure that the parameters of this neural network ar trainable, that is, the numbers in the 256x4 matrix can be tuned with the help of backpropagation of gradients weights.requires_grad_() # finally we also add the bias weights for the 4-dimensional output, and make these trainable too bias = torch.zeros(4, requires_grad=True)
We can instead use nn.Linear(256, 4) to represent the same thing.
Within the torch.nn module, there is a submodule called torch.nn.functional. This submodule consists of all the functions within the torch.nn module whereas all the other submodules are classes. These functions are loss functions, activating functions, and also neural functions that can be used to create neural networks in a functional manner (that is, when each subsequent layer is expressed as a function of the previous layer) such as pooling, convolutional, and linear functions. An example of a loss function using the torch.nn.functional module could be the following:
import torch.nn.functional as F loss_func = F.cross_entropy loss = loss_func(model(X), y)
Here, X is the input, y is the target output, and model is the neural network model.
torch.optim
As we train a neural network, we back-propagate errors to tune the weights or parameters of the network – the process that we call optimization. The optim module includes all the tools and functionalities related to running various types of optimization schedules while training a deep learning model. Let's say we define an optimizer during a training session using the torch.optim modules, as shown in the following snippet:
opt = optim.SGD(model.parameters(), lr=lr)
Then, we don't need to manually write the optimization step as shown here:
with torch.no_grad(): # applying the parameter updates using stochastic gradient descent for param in model.parameters(): param -= param.grad * lr model.zero_grad()
We can simply write this instead:
opt.step() opt.zero_grad()
Next, we will look at the utis.data module.
torch.utils.data
Under the utis.data module, torch provides its own dataset and DatasetLoader classes, which are extremely handy due to their abstract and flexible implementations. Basically, these classes provide intuitive and useful ways of iterating and performing other such operations on tensors. Using these, we can ensure high performance due to optimized tensor computations and also have fail-safe data I/O. For example, let's say we use torch.utils.data.DataLoader as follows:
from torch.utils.data import (TensorDataset, DataLoader) train_dataset = TensorDataset(x_train, y_train) train_dataloader = DataLoader(train_dataset, batch_size=bs)
Then, we don't need to iterate through batches of data manually, like this:
for i in range((n-1)//bs + 1): x_batch = x_train[start_i:end_i] y_batch = y_train[start_i:end_i] pred = model(x_batch)
We can simply write this instead:
for x_batch,y_batch in train_dataloader: pred = model(x_batch)
Let's now look at tensor modules.
Tensor modules
As mentioned earlier, tensors are conceptually similar to NumPy arrays. A tensor is an n-dimensional array on which we can operate mathematical functions, accelerate computations via GPUs, and tensors can also be used to keep track of a computational graph and gradients, which prove vital for deep learning. To run a tensor on a GPU, all we need is to cast the tensor into a certain data type.
Here is how we can instantiate a tensor in PyTorch:
points = torch.tensor([1.0, 4.0, 2.0, 1.0, 3.0, 5.0])
To fetch the first entry, simply write the following:
float(points[0])
We can also check the shape of the tensor using this:
points.shape
In PyTorch, tensors are implemented as views over a one-dimensional array of numerical data stored in contiguous chunks of memory. These arrays are called storage instances. Every PyTorch tensor has a storage attribute that can be called to output the underlying storage instance for a tensor as shown in the following example:
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]]) points.storage()
This should output the following:
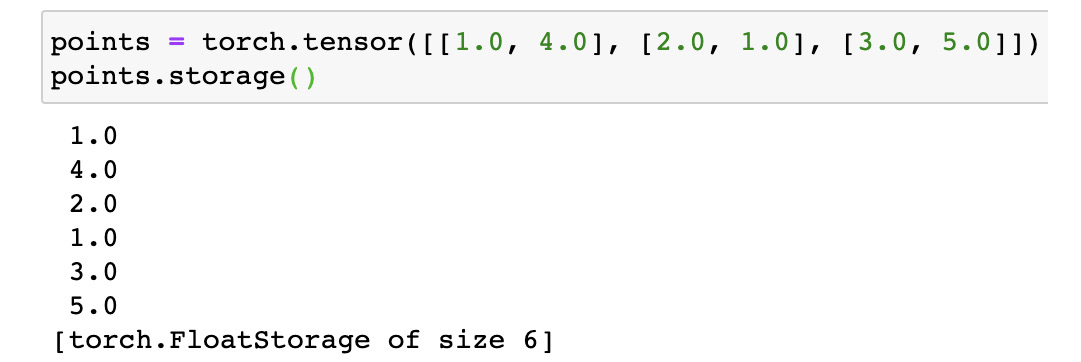
Figure 1.14 – PyTorch tensor storage
When we say a tensor is a view on the storage instance, the tensor uses the following information to implement the view:
- Size
- Storage
- Offset
- Stride
Let's look into this with the help of our previous example:
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
Let's investigate what these different pieces of information mean:
points.size()
This should output the following:
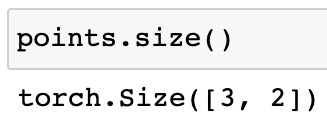
Figure 1.15 – PyTorch tensor size
As we can see, size is similar to the shape attribute in NumPy, which tells us the number of elements across each dimension. The multiplication of these numbers equals the length of the underlying storage instance (6 in this case).
As we have already examined what the storage attribute means, let's look at offset:
points.storage_offset()
This should output the following:
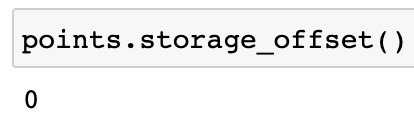
Figure 1.16 – PyTorch tensor storage offset 1
The offset here represents the index of the first element of the tensor in the storage array. Because the output is 0, it means that the first element of the tensor is the first element in the storage array.
Let's check this:
points[1].storage_offset()
This should output the following:
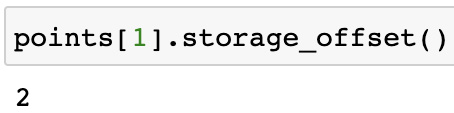
Figure 1.17 – PyTorch tensor storage offset 2
Because points[1] is [2.0, 1.0] and the storage array is [1.0, 4.0, 2.0, 1.0, 3.0, 5.0], we can see that the first element of the tensor [2.0, 1.0], that is, . 2.0 is at index 2 of the storage array.
Finally, we'll look at the stride attribute:
points.stride()
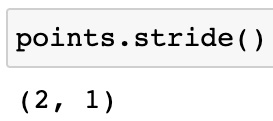
Figure 1.18 – PyTorch tensor stride
As we can see, stride contains, for each dimension, the number of elements to be skipped in order to access the next element of the tensor. So, in this case, along the first dimension, in order to access the element after the first one, that is, 1.0 we need to skip 2 elements (that is, 1.0 and 4.0) to access the next element, that is, 2.0. Similarly, along the second dimension, we need to skip 1 element to access the element after 1.0, that is, 4.0. Thus, using all these attributes, tensors can be derived from a contiguous one-dimensional storage array.
The data contained within tensors is of numeric type. Specifically, PyTorch offers the following data types to be contained within tensors:
torch.float32ortorch.float—32-bit floating-pointtorch.float64ortorch.double—64-bit, double-precision floating-pointtorch.float16ortorch.half—16-bit, half-precision floating-pointtorch.int8—Signed 8-bit integerstorch.uint8—Unsigned 8-bit integerstorch.int16ortorch.short—Signed 16-bit integerstorch.int32ortorch.int—Signed 32-bit integerstorch.int64ortorch.long—Signed 64-bit integers
An example of how we specify a certain data type to be used for a tensor is as follows:
points = torch.tensor([[1.0, 2.0], [3.0, 4.0]], dtype=torch.float32)
Besides the data type, tensors in PyTorch also need a device specification where they will be stored. A device can be specified as instantiation:
points = torch.tensor([[1.0, 2.0], [3.0, 4.0]], dtype=torch.float32, device='cpu')
Or we can also create a copy of a tensor in the desired device:
points_2 = points.to(device='cuda')
As seen in the two examples, we can either allocate a tensor to a CPU (using device='cpu'), which happens by default if we do not specify a device, or we can allocate the tensor to a GPU (using device='cuda').
Note
PyTorch currently supports only GPUs that support CUDA.
When a tensor is placed on a GPU, the computations speed up and because the tensor APIs are largely uniform across CPU and GPU placed tensors in PyTorch, it is quite convenient to move the same tensor across devices, perform computations, and move it back.
If there are multiple devices of the same type, say more than one GPU, we can precisely locate the device we want to place the tensor in using the device index, such as the following:
points_3 = points.to(device='cuda:0')
You can read more about PyTorch-CUDA here: https://pytorch.org/docs/stable/notes/cuda.html. And you can read more generally about CUDA here: https://developer.nvidia.com/about-cuda.
Now that we have explored the PyTorch library and understood the PyTorch and Tensor modules, let's learn how to train a neural network using PyTorch.






