Quoting usability expert Jared Spool, Good design, when done well, should be invisible. This holds true for ML as well. The application of ML need not be apparent to the user and sometimes (more often than not) more subtle uses of ML can prove just as impactful.
A good example of this is an iOS feature called dynamic target resizing; it is working every time you type on an iOS keyboard, where it actively tries to predict what word you're trying to type:
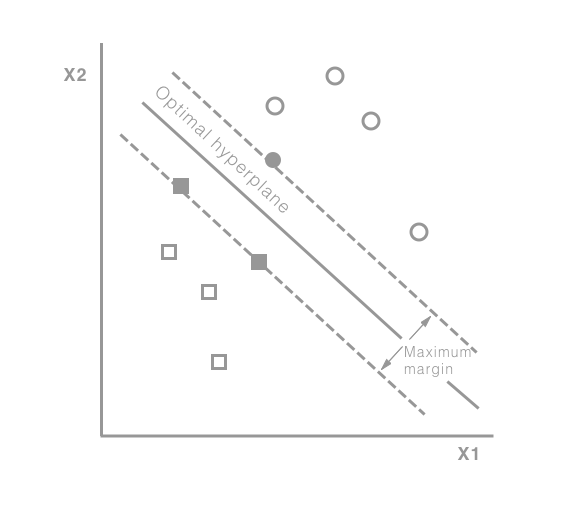
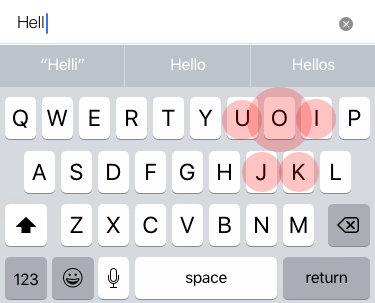
Using this prediction, the iOS keyboard dynamically changes the touch area of a key (here illustrated by the red circles) that is the most likely character based on what has already been typed before it.
For example, in the preceding diagram, the user has entered "Hell"; now it would be reasonable to assume that the most likely next character the user wants to tap is "o". This is intuitive given our knowledge of the English language, but how do we teach a machine to know this?
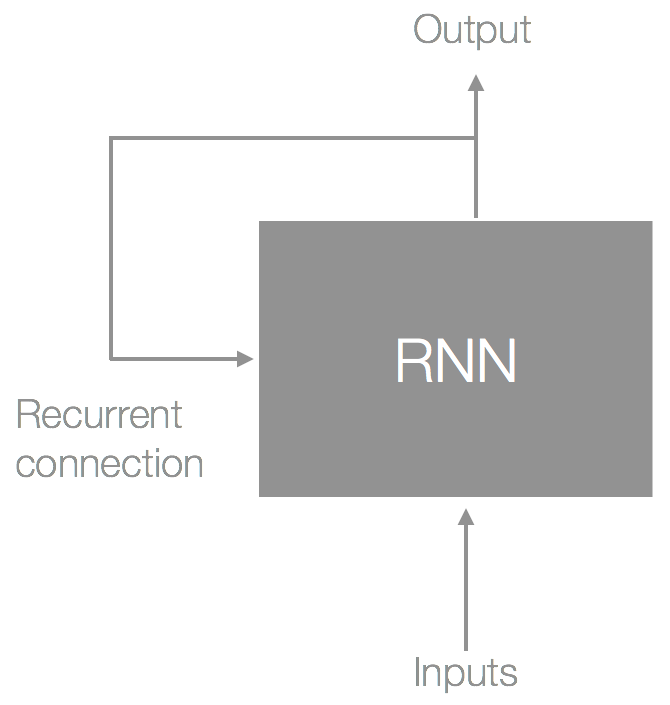
This is where recurrent neural networks (RNNs) come in; it's a type of neural network that persists state over time. You can think of this persisted state as a form of memory, making RNNs suitable for sequential data such as text (any data where the inputs and outputs are dependent on each other). This state is created by using a feedback loop from the output of the cell, as shown in the following diagram:
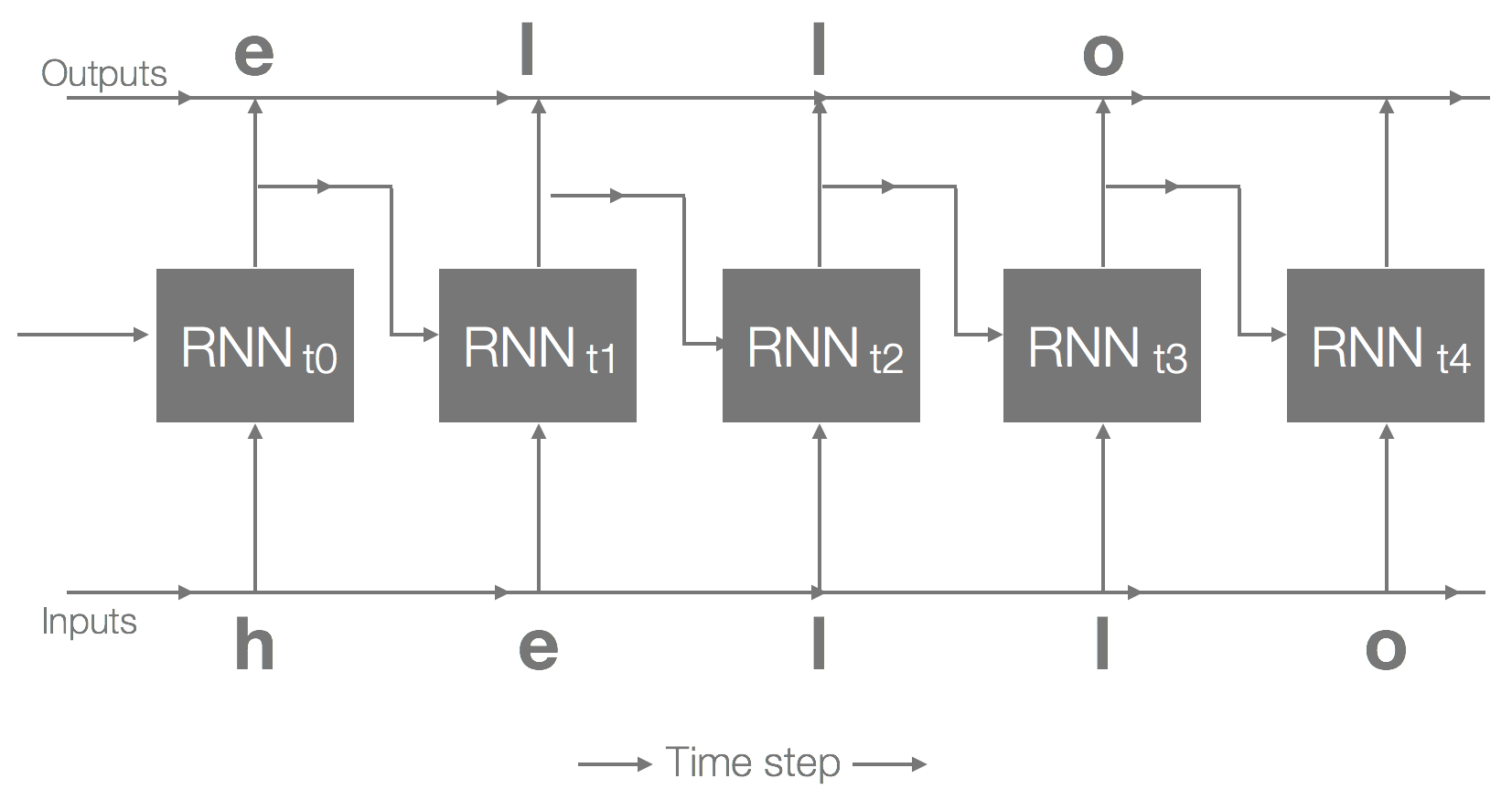
The preceding diagram shows a single RNN cell. If we unroll this over time, we would get something that looks like the following:
Using hello as our example, the preceding diagram shows an unrolled RNN over five time steps; at each time step, the RNN predicts the next likely character. This prediction is determined by its internal representation of the language (from training) and subsequent inputs. This internal representation is built by training it on samples of text where the output is using the inputs but at the next time step (as illustrated earlier). Once trained, the inference follows a similar path, except that we feed to the network the predicted character from the output, to get the next output (to generate the sequence, that is, words).
Neural networks and most ML algorithms require their inputs to be numbers, so we need to convert our characters to numbers, and back again. When dealing with text (characters and words), there are generally two approaches: one-hot encoding and embeddings. Let's quickly cover each of these to get some intuition of how to handle text.
Text (characters and words) is considered categorical, meaning that we cannot use a single number to represent text because there is no inherit relationship between the text and the value; that is, assigning the 10 and cat 20 implies that cat has a greater value than the. Instead, we need to encode them into something where no bias is introduced. One solution to this is encoding them using one-hot encoding, which uses an array of the size of your vocabulary (number of characters in our case), with the index of the specific character set to 1 and the rest set to 0. The following diagram illustrates the encoding process for the corpus "hello":
In the preceding diagram, we show some of the steps required when encoding characters; we start off by splitting the corpus into individual characters (called tokens, and the process is called tokenization). Then we create a set that acts as our vocabulary, and finally we encode this with each character being assigned a vector.
Here, we'll only present some of the steps required for preparing text before passing it to our ML algorithm.
Once our inputs are encoded, we can feed them into our network. Outputs will also be represented in this format, with the most likely character being the index with the greatest value. For example, if 'e' is predicted, then the most likely the output may resemble something like [0.95, 0.2, 0.2, 0.1].
But there are two problems with one-hot encoding. The first is that for a large vocabulary, we end up with a very sparse data structure. This is not only an inefficient use of memory, but also requires additional calculations for training and inference. The second problem, which is more obvious when operating on words, is that we lose any contextual meaning after they have been encoded. For example, if we were to encode the words dog and dogs, we would lose any relationship between these words after encoding.
An alternative, and something that addresses these two problems, is using an embedding. These are generally weights from a trained network that use a dense vector representation for each token, one that preserves some contextual meaning. This book focuses on computer vision tasks, so we won't be going into the details here. Just remember that we need to encode our text (characters) into something our ML algorithm will accept.
We train the model using weak supervision, similar to supervised learning, but inferring the label without it having been explicitly labelled. Once trained, we can predict the next character using multi-class classification, as described earlier.
Over the past couple of years, we have seen the evolution of assistive writing; one example is Google's Smart Reply, which provides an end-to-end method for automatically generating short email responses. Exciting times!
This concludes our brief tour of introducing types of ML problems along with the associated data types, algorithms, and learning style. We have only scratched the surface of each, but as you make your way through this book, you will be introduced to more data types, algorithms, and learning styles.
In the next section, we will take a step back and review the overall workflow for training and inference before wrapping up this chapter.