






















































Preparing and testing the serve script in R
In this recipe, we will create a serve script using R that runs an inference API using the plumber package. This API loads the model during initialization and uses the model to perform predictions during endpoint invocation.
The following diagram shows the expected behavior of the R serve script that we will prepare in this recipe. The R serve script loads the model file from the /opt/ml/model directory and runs a plumber web server on port 8080:
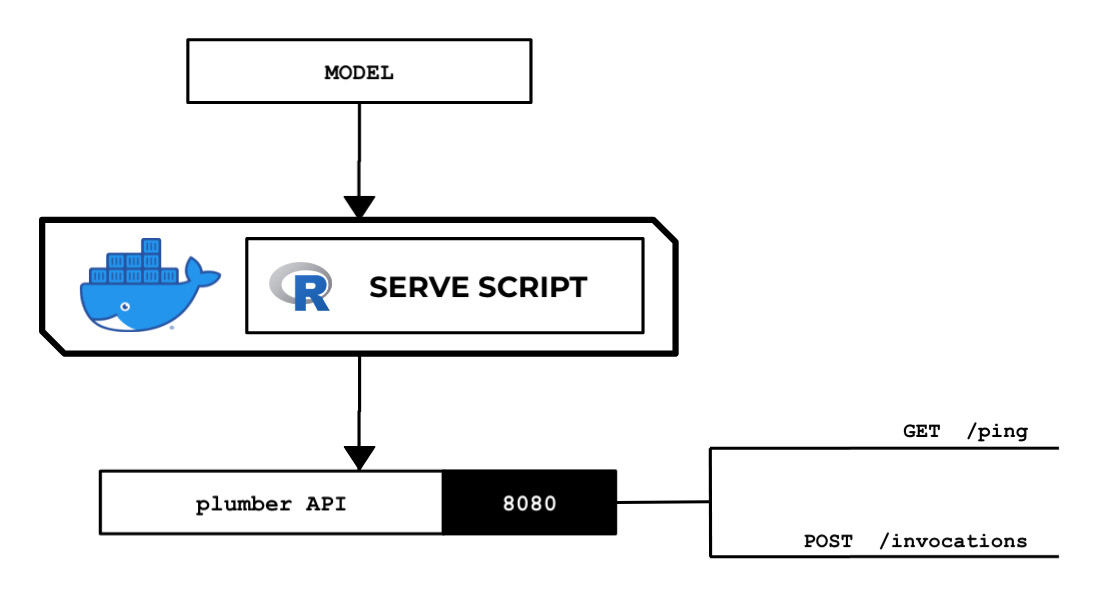
Figure 2.84 – The R serve script loads and deserializes the model and runs a plumber API server that acts as the inference endpoint
The web server is expected to have the /ping and /invocations endpoints. This standalone R backend API server will run inside a custom container later.
Getting ready
Make sure you have completed the Preparing and testing the train script in R recipe.
How to do it...
We will start by preparing the api.r file:
- Double-click the
api.rfile inside theml-rdirectory in the file tree:
Figure 2.85 – An empty api.r file inside the ml-r directory
Here, we can see four files under the
ml-rdirectory. Remember that we created an emptyapi.rfile in the Setting up the Python and R experimentation environments recipe:
Figure 2.86 – Empty api.r file
In the next couple of steps, we will add a few lines of code inside this
api.rfile. Later, we will learn how to use the plumber package to generate an API from thisapi.rfile. - Define the
prepare_paths()function, which we will use to initialize thePATHSvariable. This will help us manage the paths of the primary files and directories used in the script. This function allows us to initialize thePATHSvariable with a dictionary-like data structure, which we can use to get the absolute paths of the required files:prepare_paths <- function() { keys <- c('hyperparameters', 'input', 'data', 'model') values <- c('input/config/hyperparameters.json', 'input/config/inputdataconfig.json', 'input/data/', 'model/') paths <- as.list(values) names(paths) <- keys return(paths); } PATHS <- prepare_paths() - Next, define the
get_path()function, which makes use of thePATHSvariable from the previous step:get_path <- function(key) { output <- paste( '/opt/ml/', PATHS[[key]], sep="") return(output); } - Create the following function (including the comments), which responds with
"OK"when triggered from the/pingendpoint:#* @get /ping function(res) { res$body <- "OK" return(res) }The line containing
#* @get /pingtellsplumberthat we will use this function to handle the GET requests with the/pingroute. - Define the
load_model()function:load_model <- function() { model <- NULL filename <- paste0(get_path('model'), 'model') print(filename) model <- readRDS(filename) return(model) } - Define the following
/invocationsfunction, which loads the model and uses it to perform a prediction on the input value from the request body:#* @post /invocations function(req, res) { print(req$postBody) model <- load_model() payload_value <- as.double(req$postBody) X_test <- data.frame(payload_value) colnames(X_test) <- "X" print(summary(model)) y_test <- predict(model, X_test) output <- y_test[[1]] print(output) res$body <- toString(output) return(res) }Here, we loaded the model using the
load_model()function, transformed and prepared the input payload before passing it to thepredict()function, used thepredict()function to perform the actual prediction when given anXinput value, and returned the predicted value in the request body.Tip
You can access a working copy of the
api.rfile in the Machine Learning with Amazon SageMaker Cookbook GitHub repository: https://github.com/PacktPublishing/Machine-Learning-with-Amazon-SageMaker-Cookbook/blob/master/Chapter02/ml-r/api.r.Now that the
api.rfile is ready, let's prepare theservescript: - Double-click the
servefile inside theml-rdirectory in the file tree:
Figure 2.87 – The serve file inside the ml-r directory
It should open an empty
servefile, similar to what is shown in the following screenshot:
Figure 2.88 – The serve file inside the ml-r directory
We will add the necessary code to this empty
servefile in the next set of steps. - Start the
servescript with the following lines of code. Here, we are loading theplumberandherepackages:#!/usr/bin/Rscript suppressWarnings(library(plumber)) library('here')The
herepackage provides utility functions to help us easily build paths to files (for example,api.r). - Add the following lines of code to start the
plumberAPI server:path <- paste0(here(), "/api.r") pr <- plumb(path) pr$run(host="0.0.0.0", port=8080)
Here, we used the
plumb()andrun()functions to launch the web server. It is important to note that the web server endpoint needs to run on port8080for this to work correctly.Tip
You can access a working copy of the serve script in the Machine Learning with Amazon SageMaker Cookbook GitHub repository: https://github.com/PacktPublishing/Machine-Learning-with-Amazon-SageMaker-Cookbook/blob/master/Chapter02/ml-r/serve.
- Open a new Terminal tab:

Figure 2.89 – Locating the Terminal
Here, we see that a Terminal tab is already open. If you need to create a new one, simply click the plus (+) sign and then click New Terminal.
- Install
libcurl4-openssl-devandlibsodium-devusingapt-get install. These are some of the prerequisites for installing theplumberpackage:sudo apt-get install -y --no-install-recommends libcurl4-openssl-dev sudo apt-get install -y --no-install-recommends libsodium-dev
- Install the
herepackage:sudo R -e "install.packages('here',repos='https://cloud.r-project.org')"The
herepackage helps us get the string path values we need to locate specific files (for example,api.r). Feel free to check out https://cran.r-project.org/web/packages/here/index.html for more information. - Install the
plumberpackage:sudo R -e "install.packages('plumber',repos='https://cloud.r-project.org')"The plumber package allows us to generate an HTTP API in R. For more information, feel free to check out https://cran.r-project.org/web/packages/plumber/index.html.
- Navigate to the
ml-rdirectory:cd /home/ubuntu/environment/opt/ml-r
- Make the
servescript executable usingchmod:chmod +x serve
- Run the
servescript:./serve
This should yield log messages similar to the following ones:

Figure 2.90 – The serve script running
Here, we can see that our serve script has successfully run a
plumberAPI web server on port8080.Finally, we must trigger this running web server.
- Open a new Terminal tab:

Figure 2.91 – New Terminal
Here, we are creating a new Terminal tab as the first tab is already running the
servescript. - Set the value of the
SERVE_IPvariable tolocalhost:SERVE_IP=localhost
- Check if the
pingendpoint is available withcurl:curl http://$SERVE_IP:8080/ping
Running the previous line of code should yield an
OKfrom the/pingendpoint. - Test the
invocationsendpoint withcurl:curl -d "1" -X POST http://$SERVE_IP:8080/invocations
We should get a value close to
881.342840085751.
Now, let's see how this works!
How it works…
In this recipe, we prepared the serve script in R. The serve script makes use of the plumber package to serve an API that allows GET requests for the /ping route and POST requests for the /invocations route. The serve script is expected to load the model file(s) from the specified model directory and run a backend API server inside the custom container. This should provide a /ping route and an /invocations route.
Compared to its Python recipe counterpart, we are dealing with two files instead of one as that's how we used plumber in this recipe:
- The
api.rfile defines what the API looks like and how it behaves. - The
servescript uses theapi.rfile to initialize and launch a web server using theplumb()function from theplumberpackage. Note that with Flask, there is no need to create a separate file to define the API routes.
When working with the plumber package, we start with an R file describing how the API will behave (for example, api.r). This R file follows the following format:
#* @get /ping
function(res) {
res$body <- "OK"
return(<RETURN VALUE>)
}
#* @post /invocations
function(req, res) {
return(<RETURN VALUE>)
}
Once this R file is ready, we simply create an R script that makes use of the plumb() function from the plumber package. This will launch a web server using the configuration and behavior coded in the api.r file:
pr <- plumb(<PATH TO API.R>) pr$run(host="0.0.0.0", port=8080)
With this, whenever the /ping URL is accessed, the mapped function defined in the api.r file is executed. Similarly, whenever the /invocations URL is accessed with a POST request, the corresponding mapped function is executed. For more information on the plumber package, feel free to check out https://www.rplumber.io/.










