






















































Clustering is a collection of unsupervised machine learning algorithms in which parts of the data are grouped based on similarity. For example, clusters might consist of data that is close together in n-dimensional Euclidean space. Clustering is useful in cybersecurity for distinguishing between normal and anomalous network activity, and for helping to classify malware into families.
Performing clustering using scikit-learn
Getting ready
Preparation for this recipe consists of installing the scikit-learn, pandas, and plotly packages in pip. The command for this is as follows:
pip install sklearn plotly pandas
In addition, a dataset named file_pe_header.csv is provided in the repository for this recipe.
How to do it...
In the following steps, we will see a demonstration of how scikit-learn's K-means clustering algorithm performs on a toy PE malware classification:
- Start by importing and plotting the dataset:
import pandas as pd
import plotly.express as px
df = pd.read_csv("file_pe_headers.csv", sep=",")
fig = px.scatter_3d(
df,
x="SuspiciousImportFunctions",
y="SectionsLength",
z="SuspiciousNameSection",
color="Malware",
)
fig.show()
The following screenshot shows the output:
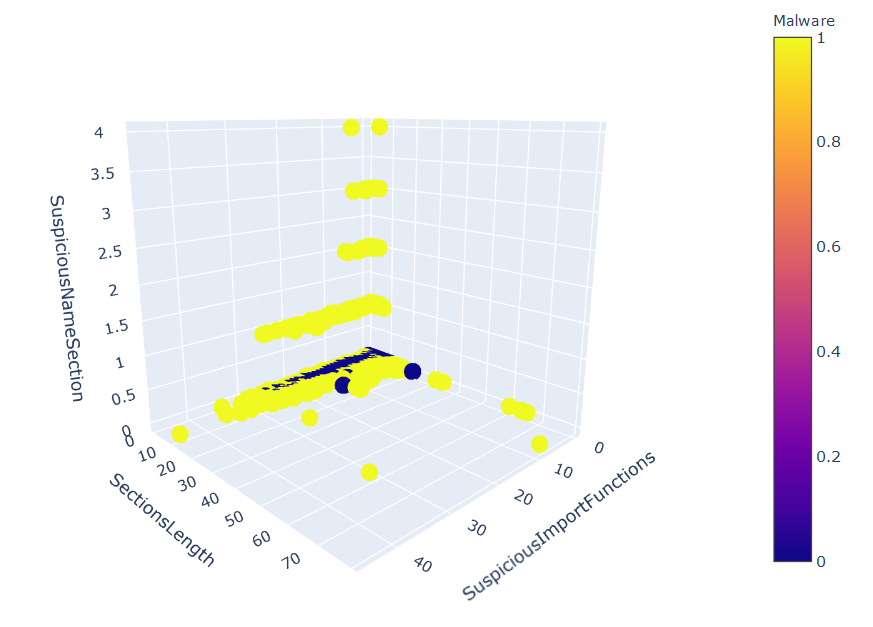
- Extract the features and target labels:
y = df["Malware"]
X = df.drop(["Name", "Malware"], axis=1).to_numpy()
- Next, import scikit-learn's clustering module and fit a K-means model with two clusters to the data:
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=len(set(y)))
estimator.fit(X)
- Predict the cluster using our trained algorithm:
y_pred = estimator.predict(X)
df["pred"] = y_pred
df["pred"] = df["pred"].astype("category")
- To see how the algorithm did, plot the algorithm's clusters:
fig = px.scatter_3d(
df,
x="SuspiciousImportFunctions",
y="SectionsLength",
z="SuspiciousNameSection",
color="pred",
)
fig.show()
The following screenshot shows the output:
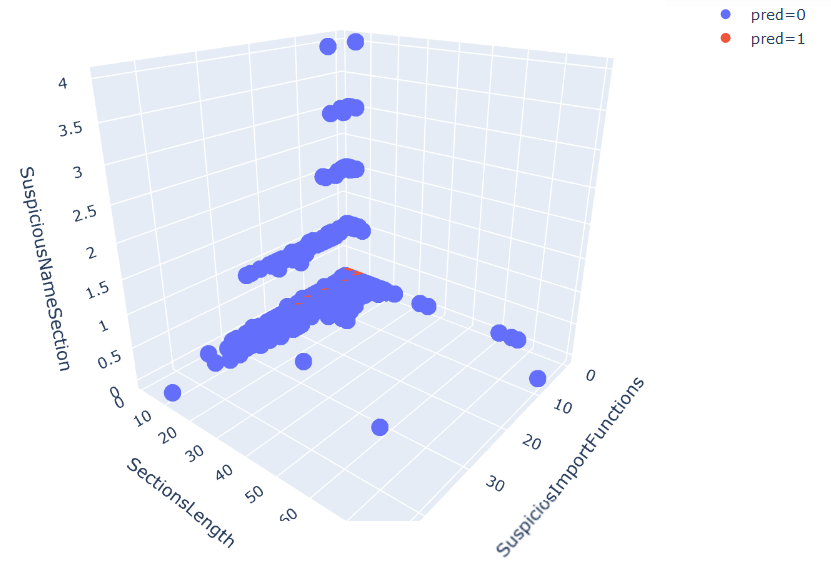
The results are not perfect, but we can see that the clustering algorithm captured much of the structure in the dataset.
How it works...
We start by importing our dataset of PE header information from a collection of samples (step 1). This dataset consists of two classes of PE files: malware and benign. We then use plotly to create a nice-looking interactive 3D graph (step 1). We proceed to prepare our dataset for machine learning. Specifically, in step 2, we set X as the features and y as the classes of the dataset. Based on the fact that there are two classes, we aim to cluster the data into two groups that will match the sample classification. We utilize the K-means algorithm (step 3), about which you can find more information at: https://en.wikipedia.org/wiki/K-means_clustering. With a thoroughly trained clustering algorithm, we are ready to predict on the testing set. We apply our clustering algorithm to predict to which cluster each of the samples should belong (step 4). Observing our results in step 5, we see that clustering has captured a lot of the underlying information, as it was able to fit the data well.






