






















































Chapter 5. Handling Databases
In this chapter, we will cover the following recipes:
- Installing relational databases with MySQL
- Storing and retrieving data with MySQL
- Importing and exporting bulk data
- Adding users and assigning access rights
- Installing web access for MySQL
- Setting backups
- Optimizing MySQL performance – queries
- Optimizing MySQL performance – configuration
- Creating MySQL replicas for scaling and high availability
- Troubleshooting MySQL
- Installing MongoDB
- Storing and retrieving data with MongoDB
Introduction
In this chapter, we will learn how to set up database servers. A database is the backbone of any application, enabling an application to efficiently store and retrieve crucial data to and from persistent storage. We will learn how to install and set up relational databases with MySQL and NoSQL databases with MongoDB.
MySQL is a popular open source database server used by various large scale applications. It is a mature database system that can be scaled to support large volumes of data. MySQL is a relational database and stores data in the form of rows and columns organized in tables. It provides various storage engines, such as MyISAM, InnoDB, and in-memory storage. MariaDB is a fork of a MySQL project and can be used as a drop-in replacement for MySQL. It was started by the developers of MySQL after Oracle took over Sun Microsystems, the owner of the MySQL project. MariaDB is guaranteed to be open source and offers faster security releases and advanced features. It provides additional storage engines, including XtraDB by Percona and Cassandra for the NoSQL backend. PostgreSQL is another well-known name in relational database systems.
NoSQL, on the other hand, is a non-relational database system. It is designed for distributed large-scale data storage requirements. For some types of data, it is not efficient to store it in the tabular form offered by relational database systems, for example, data in the form of a document. NoSQL databases are used for these types of data. Some emerging NoSQL categories are document storage, key value store, BigTable, and the graph database.
In this chapter, we will start by installing MySQL, followed by storing and manipulating data in MySQL. We will also cover user management and access control. After an introduction to relational databases, we will cover some advanced topics on scaling and high availability. We will learn how to set up the web administration tool, PHPMyAdmin, but the focus will be on working with MySQL through command line access. In later recipes, we will also cover the document storage server, MongoDB.
Installing relational databases with MySQL
In this recipe, we will learn how to install and configure the MySQL database on an Ubuntu server.
Getting ready
You will need access to a root account or an account with sudo privileges.
Make sure that the MySQL default port 3306 is available and not blocked by any firewall.
How to do it…
Follow these steps to install the relational database MySQL:
- To install the MySQL server, use the following command:
$ sudo apt-get update $ sudo apt-get install mysql-server-5.7
The installation process will download the necessary packages and then prompt you to enter a password for the MySQL root account. Choose a strong password:

- Once the installation process is complete, you can check the server status with the following command. It should return an output similar to the following:
$ sudo service mysql status mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service Active: active (running) since Tue 2016-05-10 05:
- Next, create a copy of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Set MySQL to listen for a connection from network hosts. Open the configuration file
/etc/mysql/mysql.conf.d/mysqld.cnfand changebind-addressunder the[mysqld]section to your server’s IP address:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf bind-address = 10.0.2.6

Note
For MySQL 5.5 and 5.6, the configuration file can be found at
/etc/mysql/my.cnf - Optionally, you can change the default port used by the MySQL server. Find the
[mysqld]section in the configuration file and change the value of theportvariable as follows:port = 30356Make sure that the selected port is available and open under firewall.
- Save the changes to the configuration file and restart the MySQL server:
$ sudo service mysql restart - Now open a connection to the server using the MySQL client. Enter the password when prompted:
$ mysql -u root -p - To get a list of available commands, type
\h:mysql> \h
How it works…
MySQL is a default database server available in Ubuntu. If you are installing the Ubuntu server, you can choose MySQL to be installed by default as part of the LAMP stack. In this recipe, we have installed the latest production release of MySQL (5.7) from the Ubuntu package repository. Ubuntu 16.04 contains MySQL 5.7, whereas Ubuntu 14.04 defaults to MySQL version 5.5.
If you prefer to use an older version on Ubuntu 16, then use following command:
$ sudo add-apt-repository ‘deb http://archive.ubuntu.com/ubuntu trusty universe’ $ sudo apt-get update $ sudo apt-get install mysql-server-5.6
After installation, configure the MySQL server to listen for connections from external hosts. Make sure that you open your database installation to trusted networks such as your private network. Making it available on the Internet will open your database to attackers.
There’s more…
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
Getting ready
You will need access to a root account or an account with sudo privileges.
Make sure that the MySQL default port 3306 is available and not blocked by any firewall.
How to do it…
Follow these steps to install the relational database MySQL:
- To install the MySQL server, use the following command:
$ sudo apt-get update $ sudo apt-get install mysql-server-5.7
The installation process will download the necessary packages and then prompt you to enter a password for the MySQL root account. Choose a strong password:
- Once the installation process is complete, you can check the server status with the following command. It should return an output similar to the following:
$ sudo service mysql status mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service Active: active (running) since Tue 2016-05-10 05:
- Next, create a copy of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Set MySQL to listen for a connection from network hosts. Open the configuration file
/etc/mysql/mysql.conf.d/mysqld.cnfand changebind-addressunder the[mysqld]section to your server’s IP address:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf bind-address = 10.0.2.6
Note
For MySQL 5.5 and 5.6, the configuration file can be found at
/etc/mysql/my.cnf - Optionally, you can change the default port used by the MySQL server. Find the
[mysqld]section in the configuration file and change the value of theportvariable as follows:port = 30356Make sure that the selected port is available and open under firewall.
- Save the changes to the configuration file and restart the MySQL server:
$ sudo service mysql restart - Now open a connection to the server using the MySQL client. Enter the password when prompted:
$ mysql -u root -p - To get a list of available commands, type
\h:mysql> \h
How it works…
MySQL is a default database server available in Ubuntu. If you are installing the Ubuntu server, you can choose MySQL to be installed by default as part of the LAMP stack. In this recipe, we have installed the latest production release of MySQL (5.7) from the Ubuntu package repository. Ubuntu 16.04 contains MySQL 5.7, whereas Ubuntu 14.04 defaults to MySQL version 5.5.
If you prefer to use an older version on Ubuntu 16, then use following command:
$ sudo add-apt-repository ‘deb http://archive.ubuntu.com/ubuntu trusty universe’ $ sudo apt-get update $ sudo apt-get install mysql-server-5.6
After installation, configure the MySQL server to listen for connections from external hosts. Make sure that you open your database installation to trusted networks such as your private network. Making it available on the Internet will open your database to attackers.
There’s more…
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
How to do it…
Follow these steps to install the relational database MySQL:
- To install the MySQL server, use the following command:
$ sudo apt-get update $ sudo apt-get install mysql-server-5.7
The installation process will download the necessary packages and then prompt you to enter a password for the MySQL root account. Choose a strong password:
- Once the installation process is complete, you can check the server status with the following command. It should return an output similar to the following:
$ sudo service mysql status mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service Active: active (running) since Tue 2016-05-10 05:
- Next, create a copy of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Set MySQL to listen for a connection from network hosts. Open the configuration file
/etc/mysql/mysql.conf.d/mysqld.cnfand changebind-addressunder the[mysqld]section to your server’s IP address:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf bind-address = 10.0.2.6
Note
For MySQL 5.5 and 5.6, the configuration file can be found at
/etc/mysql/my.cnf - Optionally, you can change the default port used by the MySQL server. Find the
[mysqld]section in the configuration file and change the value of theportvariable as follows:port = 30356Make sure that the selected port is available and open under firewall.
- Save the changes to the configuration file and restart the MySQL server:
$ sudo service mysql restart - Now open a connection to the server using the MySQL client. Enter the password when prompted:
$ mysql -u root -p - To get a list of available commands, type
\h:mysql> \h
How it works…
MySQL is a default database server available in Ubuntu. If you are installing the Ubuntu server, you can choose MySQL to be installed by default as part of the LAMP stack. In this recipe, we have installed the latest production release of MySQL (5.7) from the Ubuntu package repository. Ubuntu 16.04 contains MySQL 5.7, whereas Ubuntu 14.04 defaults to MySQL version 5.5.
If you prefer to use an older version on Ubuntu 16, then use following command:
$ sudo add-apt-repository ‘deb http://archive.ubuntu.com/ubuntu trusty universe’ $ sudo apt-get update $ sudo apt-get install mysql-server-5.6
After installation, configure the MySQL server to listen for connections from external hosts. Make sure that you open your database installation to trusted networks such as your private network. Making it available on the Internet will open your database to attackers.
There’s more…
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
How it works…
MySQL is a default database server available in Ubuntu. If you are installing the Ubuntu server, you can choose MySQL to be installed by default as part of the LAMP stack. In this recipe, we have installed the latest production release of MySQL (5.7) from the Ubuntu package repository. Ubuntu 16.04 contains MySQL 5.7, whereas Ubuntu 14.04 defaults to MySQL version 5.5.
If you prefer to use an older version on Ubuntu 16, then use following command:
$ sudo add-apt-repository ‘deb http://archive.ubuntu.com/ubuntu trusty universe’ $ sudo apt-get update $ sudo apt-get install mysql-server-5.6
After installation, configure the MySQL server to listen for connections from external hosts. Make sure that you open your database installation to trusted networks such as your private network. Making it available on the Internet will open your database to attackers.
There’s more…
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
There’s more…
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
Securing MySQL installation
MySQL provides a simple script to configure basic settings related to security. Execute this script before using your server in production:
$ mysql_secure_installation
This command will start a basic security check, starting with changing the root password. If you have not set a strong password for the root account, you can do it now. Other settings include disabling remote access to the root account and removing anonymous users and unused databases.
MySQL is popularly used with PHP. You can easily install PHP drivers for MySQL with the following command:
$ sudo apt-get install php7.0-mysql
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
See also
- The Ubuntu server guide mysql page at https://help.ubuntu.com/14.04/serverguide/mysql.html
Storing and retrieving data with MySQL
In this recipe, we will learn how to create databases and tables and store data in those tables. We will learn the basic Structured Query Language (SQL) required for working with MySQL. We will focus on using the command-line MySQL client for this tutorial, but you can use the same queries with any client software or code.
Getting ready
Ensure that the MySQL server is installed and running. You will need administrative access to the MySQL server. Alternatively, you can use the root account of MySQL.
How to do it…
Follow these steps to store and retrieve data with MySQL:
- First, we will need to connect to the MySQL server. Replace
adminwith a user account on the MySQL server. You can use root as well but it’s not recommended:$ mysql -u admin -h localhost -p - When prompted, enter the password for the
adminaccount. If the password is correct, you will see the following MySQL prompt:
- Create a database with the following query. Note the semi-colon at the end of query:
mysql > create database myblog; - Check all databases with a
showdatabases query. It should listmyblog:mysql > show databases;
- Select a database to work with, in this case
myblog:mysql > use myblog; Database changed
- Now, after the database has changed, we need to create a table to store our data. Use the following query to create a table:
CREATE TABLE `articles` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(255) NOT NULL, `content` text NOT NULL, `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1;
- Again, you can check tables with the
show tablesquery:mysql > show tables;

- Now, let’s insert some data in our table. Use the following query to create a new record:
mysql > INSERT INTO `articles` (`id`, `title`, `content`, `created_at`) VALUES (NULL, ‘My first blog post’, ‘contents of article’, CURRENT_TIMESTAMP);

- Retrieve data from the table. The following query will select all records from the articles table:
mysql > Select * from articles;

- Retrieve the selected records from the table:
mysql > Select * from articles where id = 1;
- Update the selected record:
mysql > update articles set title=”New title” where id=1;

- Delete the record from the
articlestable using the following command:mysql > delete from articles where id = 2;
How it works…
We have created a relational database to store blog data with one table. Actual blog databases will need additional tables for comments, authors, and various entities. The queries used to create databases and tables are known as Data Definition Language (DDL), and queries that are used to select, insert, and update the actual data are known as Data Manipulation Language (DML).
MySQL offers various data types to be used for columns such as tinyint, int, long, double, varchar, text, blob, and so on. Each data type has its specific use and a proper selection may help to improve the performance of your database.
Getting ready
Ensure that the MySQL server is installed and running. You will need administrative access to the MySQL server. Alternatively, you can use the root account of MySQL.
How to do it…
Follow these steps to store and retrieve data with MySQL:
- First, we will need to connect to the MySQL server. Replace
adminwith a user account on the MySQL server. You can use root as well but it’s not recommended:$ mysql -u admin -h localhost -p - When prompted, enter the password for the
adminaccount. If the password is correct, you will see the following MySQL prompt: - Create a database with the following query. Note the semi-colon at the end of query:
mysql > create database myblog; - Check all databases with a
showdatabases query. It should listmyblog:mysql > show databases; - Select a database to work with, in this case
myblog:mysql > use myblog; Database changed
- Now, after the database has changed, we need to create a table to store our data. Use the following query to create a table:
CREATE TABLE `articles` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(255) NOT NULL, `content` text NOT NULL, `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1;
- Again, you can check tables with the
show tablesquery:mysql > show tables;
- Now, let’s insert some data in our table. Use the following query to create a new record:
mysql > INSERT INTO `articles` (`id`, `title`, `content`, `created_at`) VALUES (NULL, ‘My first blog post’, ‘contents of article’, CURRENT_TIMESTAMP);
- Retrieve data from the table. The following query will select all records from the articles table:
mysql > Select * from articles;
- Retrieve the selected records from the table:
mysql > Select * from articles where id = 1;
- Update the selected record:
mysql > update articles set title=”New title” where id=1;
- Delete the record from the
articlestable using the following command:mysql > delete from articles where id = 2;
How it works…
We have created a relational database to store blog data with one table. Actual blog databases will need additional tables for comments, authors, and various entities. The queries used to create databases and tables are known as Data Definition Language (DDL), and queries that are used to select, insert, and update the actual data are known as Data Manipulation Language (DML).
MySQL offers various data types to be used for columns such as tinyint, int, long, double, varchar, text, blob, and so on. Each data type has its specific use and a proper selection may help to improve the performance of your database.
How to do it…
Follow these steps to store and retrieve data with MySQL:
- First, we will need to connect to the MySQL server. Replace
adminwith a user account on the MySQL server. You can use root as well but it’s not recommended:$ mysql -u admin -h localhost -p - When prompted, enter the password for the
adminaccount. If the password is correct, you will see the following MySQL prompt: - Create a database with the following query. Note the semi-colon at the end of query:
mysql > create database myblog; - Check all databases with a
showdatabases query. It should listmyblog:mysql > show databases; - Select a database to work with, in this case
myblog:mysql > use myblog; Database changed
- Now, after the database has changed, we need to create a table to store our data. Use the following query to create a table:
CREATE TABLE `articles` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(255) NOT NULL, `content` text NOT NULL, `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1;
- Again, you can check tables with the
show tablesquery:mysql > show tables;
- Now, let’s insert some data in our table. Use the following query to create a new record:
mysql > INSERT INTO `articles` (`id`, `title`, `content`, `created_at`) VALUES (NULL, ‘My first blog post’, ‘contents of article’, CURRENT_TIMESTAMP);
- Retrieve data from the table. The following query will select all records from the articles table:
mysql > Select * from articles;
- Retrieve the selected records from the table:
mysql > Select * from articles where id = 1;
- Update the selected record:
mysql > update articles set title=”New title” where id=1;
- Delete the record from the
articlestable using the following command:mysql > delete from articles where id = 2;
How it works…
We have created a relational database to store blog data with one table. Actual blog databases will need additional tables for comments, authors, and various entities. The queries used to create databases and tables are known as Data Definition Language (DDL), and queries that are used to select, insert, and update the actual data are known as Data Manipulation Language (DML).
MySQL offers various data types to be used for columns such as tinyint, int, long, double, varchar, text, blob, and so on. Each data type has its specific use and a proper selection may help to improve the performance of your database.
How it works…
We have created a relational database to store blog data with one table. Actual blog databases will need additional tables for comments, authors, and various entities. The queries used to create databases and tables are known as Data Definition Language (DDL), and queries that are used to select, insert, and update the actual data are known as Data Manipulation Language (DML).
MySQL offers various data types to be used for columns such as tinyint, int, long, double, varchar, text, blob, and so on. Each data type has its specific use and a proper selection may help to improve the performance of your database.
Importing and exporting bulk data
In this recipe, we will learn how to import and export bulk data with MySQL. Many times it happens that we receive data in CSV or XML format and we need to add this data to the database server for further processing. You can always use tools such as MySQL workbench and phpMyAdmin, but MySQL provides command-line tools for the bulk processing of data that are more efficient and flexible.
How to do it…
Follow these steps to import and export bulk data:
- To export a database from the MySQL server, use the following command:
$ mysqldump -u admin -p mytestdb > db_backup.sql - To export specific tables from a database, use the following command:
$ mysqldump -u admin -p mytestdb table1 table2 > table_backup.sql - To compress exported data, use
gzip:$ mysqldump -u admin -p mytestdb | gzip > db_backup.sql.gz - To export selective data to the CSV format, use the following query. Note that this will create
articles.csvon the same server as MySQL and not your local server:SELECT id, title, contents FROM articles INTO OUTFILE ‘/tmp/articles.csv’ FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘”’ LINES TERMINATED BY ‘\n’;
- To fetch data on your local system, you can use the MySQL client as follows:
- Write your query in a file:
$ nano query.sql select * from articles;
- Now pass this query to the
mysqlclient and collect the output in CSV:$ mysql -h 192.168.2.100 -u admin -p myblog < query.sql > output.csv
The resulting file will contain tab separated values.
- Write your query in a file:
- To import an SQL file to a MySQL database, we need to first create a database:
$ mysqladmin -u admin -p create mytestdb2 - Once the database is created, import data with the following command:
$ mysql -u admin -p mytestdb2 < db_backup.sql - To import a CSV file in a MySQL table, you can use the
Load Dataquery. The following is the sample CSV file:
Now use the following query from the MySQL console to import data from CSV:
LOAD DATA INFILE ‘c:/tmp/articles.csv’ INTO TABLE articles FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘”’ LINES TERMINATED BY \n IGNORE 1 ROWS;
See also
- MySQL select-into syntax at https://dev.mysql.com/doc/refman/5.6/en/select-into.html
- MySQL load data infile syntax at https://dev.mysql.com/doc/refman/5.6/en/load-data.html
- Importing from and exporting to XML files at https://dev.mysql.com/doc/refman/5.6/en/load-xml.html
How to do it…
Follow these steps to import and export bulk data:
- To export a database from the MySQL server, use the following command:
$ mysqldump -u admin -p mytestdb > db_backup.sql - To export specific tables from a database, use the following command:
$ mysqldump -u admin -p mytestdb table1 table2 > table_backup.sql - To compress exported data, use
gzip:$ mysqldump -u admin -p mytestdb | gzip > db_backup.sql.gz - To export selective data to the CSV format, use the following query. Note that this will create
articles.csvon the same server as MySQL and not your local server:SELECT id, title, contents FROM articles INTO OUTFILE ‘/tmp/articles.csv’ FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘”’ LINES TERMINATED BY ‘\n’;
- To fetch data on your local system, you can use the MySQL client as follows:
- Write your query in a file:
$ nano query.sql select * from articles;
- Now pass this query to the
mysqlclient and collect the output in CSV:$ mysql -h 192.168.2.100 -u admin -p myblog < query.sql > output.csv
The resulting file will contain tab separated values.
- Write your query in a file:
- To import an SQL file to a MySQL database, we need to first create a database:
$ mysqladmin -u admin -p create mytestdb2 - Once the database is created, import data with the following command:
$ mysql -u admin -p mytestdb2 < db_backup.sql - To import a CSV file in a MySQL table, you can use the
Load Dataquery. The following is the sample CSV file:Now use the following query from the MySQL console to import data from CSV:
LOAD DATA INFILE ‘c:/tmp/articles.csv’ INTO TABLE articles FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘”’ LINES TERMINATED BY \n IGNORE 1 ROWS;
See also
- MySQL select-into syntax at https://dev.mysql.com/doc/refman/5.6/en/select-into.html
- MySQL load data infile syntax at https://dev.mysql.com/doc/refman/5.6/en/load-data.html
- Importing from and exporting to XML files at https://dev.mysql.com/doc/refman/5.6/en/load-xml.html
See also
- MySQL select-into syntax at https://dev.mysql.com/doc/refman/5.6/en/select-into.html
- MySQL load data infile syntax at https://dev.mysql.com/doc/refman/5.6/en/load-data.html
- Importing from and exporting to XML files at https://dev.mysql.com/doc/refman/5.6/en/load-xml.html
Adding users and assigning access rights
In this recipe, we will learn how to add new users to the MySQL database server. MySQL provides very flexible and granular user management options. We can create users with full access to an entire database or limit a user to simply read the data from a single database. Again, we will be using queries to create users and grant them access rights. You are free to use any tool of your choice.
Getting ready
You will need a MySQL user account with administrative privileges. You can use the MySQL root account.
How to do it…
Follow these steps to add users to MySQL database server and assign access rights:
- Open the MySQL shell with the following command. Enter the password for the admin account when prompted:
$ mysql -u root -p - From the MySQL shell, use the following command to add a new user to MySQL:
mysql> create user ‘dbuser’@’localhost’ identified by ‘password’; - You can check the user account with the following command:
mysql> select user, host, password from mysql.user where user = ‘dbuser’;
- Next, add some privileges to this user account:
mysql> grant all privileges on *.* to ‘dbuser’@’localhost’ with grant option; - Verify the privileges for the account as follows:
mysql> show grants for ‘dbuser’@’localhost’
- Finally, exit the MySQL shell and try to log in with the new user account. You should log in successfully:
mysql> exit $ mysql -u dbuser -p
How it works…
MySQL uses the same database structure to store user account information. It contains a hidden database named MySQL that contains all MySQL settings along with user accounts. The statements create user and grant work as a wrapper around common insert statements and make it easy to add new users to the system.
In the preceding example, we created a new user with the name dbuser. This user is allowed to log in only from localhost and requires a password to log in to the MySQL server. You can skip the identified by ‘password’ part to create a user without a password, but of course, it’s not recommended.
To allow a user to log in from any system, you need to set the host part to a %, as follows:
mysql> create user ‘dbuser’@’%’ identified by ‘password’;
You can also limit access from a specific host by specifying its FQDN or IP address:
mysql> create user ‘dbuser’@’host1.example.com’ identified by ‘password’;
Or
mysql> create user ‘dbuser’@’10.0.2.51’ identified by ‘password’;
Note that if you have an anonymous user account on MySQL, then a user created with username’@’% will not be able to log in through localhost. You will need to add a separate entry with username’@’localhost.
Next, we give some privileges to this user account using a grant statement. The preceding example gives all privileges on all databases to the user account dbuser. To limit the database, change the database part to dbname.*:
mysql> grant all privileges on dbname.* to ‘dbuser’@’localhost’ with grant option;
To limit privileges to certain tasks, mention specific privileges in a grant statement:
mysql> grant select, insert, update, delete, create -> on dbname.* to ‘dbuser’@’localhost’;
The preceding statement will grant select, insert, update, delete, and create privileges on any table under the dbname database.
There’s more…
Similar to preceding add user example, other user management tasks can be performed with SQL queries as follows:
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
Getting ready
You will need a MySQL user account with administrative privileges. You can use the MySQL root account.
How to do it…
Follow these steps to add users to MySQL database server and assign access rights:
- Open the MySQL shell with the following command. Enter the password for the admin account when prompted:
$ mysql -u root -p - From the MySQL shell, use the following command to add a new user to MySQL:
mysql> create user ‘dbuser’@’localhost’ identified by ‘password’; - You can check the user account with the following command:
mysql> select user, host, password from mysql.user where user = ‘dbuser’; - Next, add some privileges to this user account:
mysql> grant all privileges on *.* to ‘dbuser’@’localhost’ with grant option; - Verify the privileges for the account as follows:
mysql> show grants for ‘dbuser’@’localhost’ - Finally, exit the MySQL shell and try to log in with the new user account. You should log in successfully:
mysql> exit $ mysql -u dbuser -p
How it works…
MySQL uses the same database structure to store user account information. It contains a hidden database named MySQL that contains all MySQL settings along with user accounts. The statements create user and grant work as a wrapper around common insert statements and make it easy to add new users to the system.
In the preceding example, we created a new user with the name dbuser. This user is allowed to log in only from localhost and requires a password to log in to the MySQL server. You can skip the identified by ‘password’ part to create a user without a password, but of course, it’s not recommended.
To allow a user to log in from any system, you need to set the host part to a %, as follows:
mysql> create user ‘dbuser’@’%’ identified by ‘password’;
You can also limit access from a specific host by specifying its FQDN or IP address:
mysql> create user ‘dbuser’@’host1.example.com’ identified by ‘password’;
Or
mysql> create user ‘dbuser’@’10.0.2.51’ identified by ‘password’;
Note that if you have an anonymous user account on MySQL, then a user created with username’@’% will not be able to log in through localhost. You will need to add a separate entry with username’@’localhost.
Next, we give some privileges to this user account using a grant statement. The preceding example gives all privileges on all databases to the user account dbuser. To limit the database, change the database part to dbname.*:
mysql> grant all privileges on dbname.* to ‘dbuser’@’localhost’ with grant option;
To limit privileges to certain tasks, mention specific privileges in a grant statement:
mysql> grant select, insert, update, delete, create -> on dbname.* to ‘dbuser’@’localhost’;
The preceding statement will grant select, insert, update, delete, and create privileges on any table under the dbname database.
There’s more…
Similar to preceding add user example, other user management tasks can be performed with SQL queries as follows:
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
How to do it…
Follow these steps to add users to MySQL database server and assign access rights:
- Open the MySQL shell with the following command. Enter the password for the admin account when prompted:
$ mysql -u root -p - From the MySQL shell, use the following command to add a new user to MySQL:
mysql> create user ‘dbuser’@’localhost’ identified by ‘password’; - You can check the user account with the following command:
mysql> select user, host, password from mysql.user where user = ‘dbuser’; - Next, add some privileges to this user account:
mysql> grant all privileges on *.* to ‘dbuser’@’localhost’ with grant option; - Verify the privileges for the account as follows:
mysql> show grants for ‘dbuser’@’localhost’ - Finally, exit the MySQL shell and try to log in with the new user account. You should log in successfully:
mysql> exit $ mysql -u dbuser -p
How it works…
MySQL uses the same database structure to store user account information. It contains a hidden database named MySQL that contains all MySQL settings along with user accounts. The statements create user and grant work as a wrapper around common insert statements and make it easy to add new users to the system.
In the preceding example, we created a new user with the name dbuser. This user is allowed to log in only from localhost and requires a password to log in to the MySQL server. You can skip the identified by ‘password’ part to create a user without a password, but of course, it’s not recommended.
To allow a user to log in from any system, you need to set the host part to a %, as follows:
mysql> create user ‘dbuser’@’%’ identified by ‘password’;
You can also limit access from a specific host by specifying its FQDN or IP address:
mysql> create user ‘dbuser’@’host1.example.com’ identified by ‘password’;
Or
mysql> create user ‘dbuser’@’10.0.2.51’ identified by ‘password’;
Note that if you have an anonymous user account on MySQL, then a user created with username’@’% will not be able to log in through localhost. You will need to add a separate entry with username’@’localhost.
Next, we give some privileges to this user account using a grant statement. The preceding example gives all privileges on all databases to the user account dbuser. To limit the database, change the database part to dbname.*:
mysql> grant all privileges on dbname.* to ‘dbuser’@’localhost’ with grant option;
To limit privileges to certain tasks, mention specific privileges in a grant statement:
mysql> grant select, insert, update, delete, create -> on dbname.* to ‘dbuser’@’localhost’;
The preceding statement will grant select, insert, update, delete, and create privileges on any table under the dbname database.
There’s more…
Similar to preceding add user example, other user management tasks can be performed with SQL queries as follows:
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
How it works…
MySQL uses the same database structure to store user account information. It contains a hidden database named MySQL that contains all MySQL settings along with user accounts. The statements create user and grant work as a wrapper around common insert statements and make it easy to add new users to the system.
In the preceding example, we created a new user with the name dbuser. This user is allowed to log in only from localhost and requires a password to log in to the MySQL server. You can skip the identified by ‘password’ part to create a user without a password, but of course, it’s not recommended.
To allow a user to log in from any system, you need to set the host part to a %, as follows:
mysql> create user ‘dbuser’@’%’ identified by ‘password’;
You can also limit access from a specific host by specifying its FQDN or IP address:
mysql> create user ‘dbuser’@’host1.example.com’ identified by ‘password’;
Or
mysql> create user ‘dbuser’@’10.0.2.51’ identified by ‘password’;
Note that if you have an anonymous user account on MySQL, then a user created with username’@’% will not be able to log in through localhost. You will need to add a separate entry with username’@’localhost.
Next, we give some privileges to this user account using a grant statement. The preceding example gives all privileges on all databases to the user account dbuser. To limit the database, change the database part to dbname.*:
mysql> grant all privileges on dbname.* to ‘dbuser’@’localhost’ with grant option;
To limit privileges to certain tasks, mention specific privileges in a grant statement:
mysql> grant select, insert, update, delete, create -> on dbname.* to ‘dbuser’@’localhost’;
The preceding statement will grant select, insert, update, delete, and create privileges on any table under the dbname database.
There’s more…
Similar to preceding add user example, other user management tasks can be performed with SQL queries as follows:
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
There’s more…
Similar to preceding add user example, other user management tasks can be performed with SQL queries as follows:
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
Removing user accounts
You can easily remove a user account with the drop statement, as follows:
mysql> drop user ‘dbuser’@’localhost’;
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
Setting resource limits
MySQL allows setting limits on individual accounts:
mysql> grant all on dbname.* to ‘dbuser’@’localhost’ -> with max_queries_per_hour 20 -> max_updates_per_hour 10 -> max_connections_per_hour 5 -> max_user_connections 2;
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
See also
- MySQL user account management at https://dev.mysql.com/doc/refman/5.6/en/user-account-management.html
Installing web access for MySQL
In this recipe, we will set up a well-known web-based MySQL administrative tool—phpMyAdmin.
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need a web server set up to serve PHP contents.
How to do it…
Follow these steps to install web access for MySQL:
- Enable the
mcryptextension for PHP:$ sudo php5enmod mcrypt - Install
phpmyadminwith the following commands:$ sudo apt-get update $ sudo apt-get install phpmyadmin
- The installation process will download the necessary packages and then prompt you to configure
phpmyadmin:
- Choose
<yes>to proceed with the configuration process. - Enter the MySQL admin account password on the next screen:

- Another screen will pop up; this time, you will be asked for the new password for the
phpmyadminuser. Enter the new password and then confirm it on the next screen:
- Next,
phpmyadminwill ask for web server selection:
- Once the installation completes, you can access phpMyAdmin at
http://server-ip/phpmyadmin. Use your admin login credentials on the login screen. Thephpmyadminscreen will look something like this: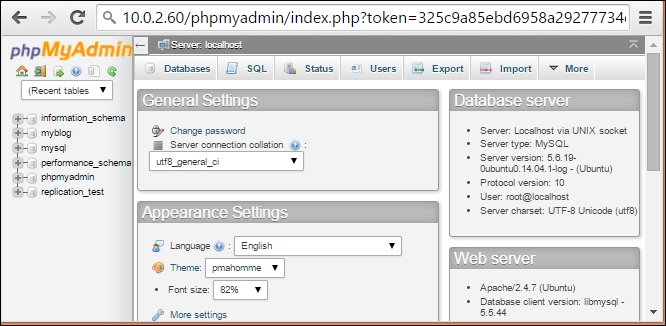
How it works…
PHPMyAdmin is a web-based administrative console for MySQL. It is developed in PHP and works with a web server such as Apache to serve web access. With PHPMyAdmin, you can do database tasks such as create databases and tables; select, insert, update data; modify table definitions; and a lot more. It provides a query console which can be used to type in custom queries and execute them from same screen.
With the addition of the Ubuntu software repository, it has become easy to install PHPMyAdmin with a single command. Once it is installed, a new user is created on the MySQL server. It also supports connecting to multiple servers. You can find all configuration files located in the /etc/phpmyadmin directory.
There’s more…
If you want to install the latest version of phpMyAdmin, you can download it from their official website, https://www.phpmyadmin.net/downloads/. You can extract downloaded contents to your web directory and set MySQL credentials in the config.inc.php file.
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need a web server set up to serve PHP contents.
How to do it…
Follow these steps to install web access for MySQL:
- Enable the
mcryptextension for PHP:$ sudo php5enmod mcrypt - Install
phpmyadminwith the following commands:$ sudo apt-get update $ sudo apt-get install phpmyadmin
- The installation process will download the necessary packages and then prompt you to configure
phpmyadmin: - Choose
<yes>to proceed with the configuration process. - Enter the MySQL admin account password on the next screen:
- Another screen will pop up; this time, you will be asked for the new password for the
phpmyadminuser. Enter the new password and then confirm it on the next screen: - Next,
phpmyadminwill ask for web server selection: - Once the installation completes, you can access phpMyAdmin at
http://server-ip/phpmyadmin. Use your admin login credentials on the login screen. Thephpmyadminscreen will look something like this:
How it works…
PHPMyAdmin is a web-based administrative console for MySQL. It is developed in PHP and works with a web server such as Apache to serve web access. With PHPMyAdmin, you can do database tasks such as create databases and tables; select, insert, update data; modify table definitions; and a lot more. It provides a query console which can be used to type in custom queries and execute them from same screen.
With the addition of the Ubuntu software repository, it has become easy to install PHPMyAdmin with a single command. Once it is installed, a new user is created on the MySQL server. It also supports connecting to multiple servers. You can find all configuration files located in the /etc/phpmyadmin directory.
There’s more…
If you want to install the latest version of phpMyAdmin, you can download it from their official website, https://www.phpmyadmin.net/downloads/. You can extract downloaded contents to your web directory and set MySQL credentials in the config.inc.php file.
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
How to do it…
Follow these steps to install web access for MySQL:
- Enable the
mcryptextension for PHP:$ sudo php5enmod mcrypt - Install
phpmyadminwith the following commands:$ sudo apt-get update $ sudo apt-get install phpmyadmin
- The installation process will download the necessary packages and then prompt you to configure
phpmyadmin: - Choose
<yes>to proceed with the configuration process. - Enter the MySQL admin account password on the next screen:
- Another screen will pop up; this time, you will be asked for the new password for the
phpmyadminuser. Enter the new password and then confirm it on the next screen: - Next,
phpmyadminwill ask for web server selection: - Once the installation completes, you can access phpMyAdmin at
http://server-ip/phpmyadmin. Use your admin login credentials on the login screen. Thephpmyadminscreen will look something like this:
How it works…
PHPMyAdmin is a web-based administrative console for MySQL. It is developed in PHP and works with a web server such as Apache to serve web access. With PHPMyAdmin, you can do database tasks such as create databases and tables; select, insert, update data; modify table definitions; and a lot more. It provides a query console which can be used to type in custom queries and execute them from same screen.
With the addition of the Ubuntu software repository, it has become easy to install PHPMyAdmin with a single command. Once it is installed, a new user is created on the MySQL server. It also supports connecting to multiple servers. You can find all configuration files located in the /etc/phpmyadmin directory.
There’s more…
If you want to install the latest version of phpMyAdmin, you can download it from their official website, https://www.phpmyadmin.net/downloads/. You can extract downloaded contents to your web directory and set MySQL credentials in the config.inc.php file.
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
How it works…
PHPMyAdmin is a web-based administrative console for MySQL. It is developed in PHP and works with a web server such as Apache to serve web access. With PHPMyAdmin, you can do database tasks such as create databases and tables; select, insert, update data; modify table definitions; and a lot more. It provides a query console which can be used to type in custom queries and execute them from same screen.
With the addition of the Ubuntu software repository, it has become easy to install PHPMyAdmin with a single command. Once it is installed, a new user is created on the MySQL server. It also supports connecting to multiple servers. You can find all configuration files located in the /etc/phpmyadmin directory.
There’s more…
If you want to install the latest version of phpMyAdmin, you can download it from their official website, https://www.phpmyadmin.net/downloads/. You can extract downloaded contents to your web directory and set MySQL credentials in the config.inc.php file.
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
There’s more…
If you want to install the latest version of phpMyAdmin, you can download it from their official website, https://www.phpmyadmin.net/downloads/. You can extract downloaded contents to your web directory and set MySQL credentials in the config.inc.php file.
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
See also
- Read more about phpMyAdmin in the Ubuntu server guide at https://help.ubuntu.com/lts/serverguide/phpmyadmin.html
- Install and secure phpMyAdmin at https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-14-04
Setting backups
In this recipe, we will learn how to back up the MySQL database.
Getting ready
You will need administrative access to the MySQL database.
How to do it…
Follow these steps to set up the backups:
- Backing up the MySQL database is the same as exporting data from the server. Use the
mysqldumptool to back up the MySQL database as follows:$ mysqldump -h localhost -u admin -p mydb > mydb_backup.sql - You will be prompted for the admin account password. After providing the password, the backup process will take time depending on the size of the database.
- To back up all databases, add the
--all-databasesflag to the preceding command:$ mysqldump --all-databases -u admin -p alldb_backup.sql - Next, we can restore the backup created with the
mysqldumptool with the following command:$ mysqladmin -u admin -p create mydb $ mysql -h localhost -u admin -p mydb < mydb_backup.sql
- To restore all databases, skip the database creation part:
$ mysql -h localhost -u admin -p < alldb_backup.sql
How it works…
MySQL provides a very general tool, mysqldump, to export all data from the database server. This tool can be used with any type of database engine, be it MyISAM or InnoDB or any other. To perform an online backup of InnoDB tables, mysqldump provides the --single-transaction option. With this option set, InnoDB tables will not be locked and will be available to other applications while backup is in progress.
Oracle provides the MySQL Enterprise backup tool for MySQL Enterprise edition users. This tool includes features such as incremental and compressed backups. Alternatively, Percona provides an open source utility known as Xtrabackup. It provides incremental and compressed backups and many more features.
Some other backup methods include copying MySQL table files and the mysqlhotcopy script for InnoDB tables. For these methods to work, you may need to pause or stop the MySQL server before backup.
You can also enable replication to mirror all data to the other server. It is a mechanism to maintain multiple copies of data by automatically copying data from one system to another. In this case, the primary server is called Master and the secondary server is called Slave. This type of configuration is known as Master-Slave replication. Generally, applications communicate with the Master server for all read and write requests. The Slave is used as a backup if the Master goes down. Many times, the Master-Slave configuration is used to load balance database queries by routing all read requests to the Slave server and write requests to the Master server. Replication can also be configured in Master-Master mode, where both servers receive read-write requests from clients.
See also
- MySQL backup methods at http://dev.mysql.com/doc/refman/5.6/en/backup-methods.html
- Percona XtraBackup at https://www.percona.com/doc/percona-xtrabackup/2.2/index.html
- MySQL binary log at http://dev.mysql.com/doc/refman/5.6/en/binary-log.html
Getting ready
You will need administrative access to the MySQL database.
How to do it…
Follow these steps to set up the backups:
- Backing up the MySQL database is the same as exporting data from the server. Use the
mysqldumptool to back up the MySQL database as follows:$ mysqldump -h localhost -u admin -p mydb > mydb_backup.sql - You will be prompted for the admin account password. After providing the password, the backup process will take time depending on the size of the database.
- To back up all databases, add the
--all-databasesflag to the preceding command:$ mysqldump --all-databases -u admin -p alldb_backup.sql - Next, we can restore the backup created with the
mysqldumptool with the following command:$ mysqladmin -u admin -p create mydb $ mysql -h localhost -u admin -p mydb < mydb_backup.sql
- To restore all databases, skip the database creation part:
$ mysql -h localhost -u admin -p < alldb_backup.sql
How it works…
MySQL provides a very general tool, mysqldump, to export all data from the database server. This tool can be used with any type of database engine, be it MyISAM or InnoDB or any other. To perform an online backup of InnoDB tables, mysqldump provides the --single-transaction option. With this option set, InnoDB tables will not be locked and will be available to other applications while backup is in progress.
Oracle provides the MySQL Enterprise backup tool for MySQL Enterprise edition users. This tool includes features such as incremental and compressed backups. Alternatively, Percona provides an open source utility known as Xtrabackup. It provides incremental and compressed backups and many more features.
Some other backup methods include copying MySQL table files and the mysqlhotcopy script for InnoDB tables. For these methods to work, you may need to pause or stop the MySQL server before backup.
You can also enable replication to mirror all data to the other server. It is a mechanism to maintain multiple copies of data by automatically copying data from one system to another. In this case, the primary server is called Master and the secondary server is called Slave. This type of configuration is known as Master-Slave replication. Generally, applications communicate with the Master server for all read and write requests. The Slave is used as a backup if the Master goes down. Many times, the Master-Slave configuration is used to load balance database queries by routing all read requests to the Slave server and write requests to the Master server. Replication can also be configured in Master-Master mode, where both servers receive read-write requests from clients.
See also
- MySQL backup methods at http://dev.mysql.com/doc/refman/5.6/en/backup-methods.html
- Percona XtraBackup at https://www.percona.com/doc/percona-xtrabackup/2.2/index.html
- MySQL binary log at http://dev.mysql.com/doc/refman/5.6/en/binary-log.html
How to do it…
Follow these steps to set up the backups:
- Backing up the MySQL database is the same as exporting data from the server. Use the
mysqldumptool to back up the MySQL database as follows:$ mysqldump -h localhost -u admin -p mydb > mydb_backup.sql - You will be prompted for the admin account password. After providing the password, the backup process will take time depending on the size of the database.
- To back up all databases, add the
--all-databasesflag to the preceding command:$ mysqldump --all-databases -u admin -p alldb_backup.sql - Next, we can restore the backup created with the
mysqldumptool with the following command:$ mysqladmin -u admin -p create mydb $ mysql -h localhost -u admin -p mydb < mydb_backup.sql
- To restore all databases, skip the database creation part:
$ mysql -h localhost -u admin -p < alldb_backup.sql
How it works…
MySQL provides a very general tool, mysqldump, to export all data from the database server. This tool can be used with any type of database engine, be it MyISAM or InnoDB or any other. To perform an online backup of InnoDB tables, mysqldump provides the --single-transaction option. With this option set, InnoDB tables will not be locked and will be available to other applications while backup is in progress.
Oracle provides the MySQL Enterprise backup tool for MySQL Enterprise edition users. This tool includes features such as incremental and compressed backups. Alternatively, Percona provides an open source utility known as Xtrabackup. It provides incremental and compressed backups and many more features.
Some other backup methods include copying MySQL table files and the mysqlhotcopy script for InnoDB tables. For these methods to work, you may need to pause or stop the MySQL server before backup.
You can also enable replication to mirror all data to the other server. It is a mechanism to maintain multiple copies of data by automatically copying data from one system to another. In this case, the primary server is called Master and the secondary server is called Slave. This type of configuration is known as Master-Slave replication. Generally, applications communicate with the Master server for all read and write requests. The Slave is used as a backup if the Master goes down. Many times, the Master-Slave configuration is used to load balance database queries by routing all read requests to the Slave server and write requests to the Master server. Replication can also be configured in Master-Master mode, where both servers receive read-write requests from clients.
See also
- MySQL backup methods at http://dev.mysql.com/doc/refman/5.6/en/backup-methods.html
- Percona XtraBackup at https://www.percona.com/doc/percona-xtrabackup/2.2/index.html
- MySQL binary log at http://dev.mysql.com/doc/refman/5.6/en/binary-log.html
How it works…
MySQL provides a very general tool, mysqldump, to export all data from the database server. This tool can be used with any type of database engine, be it MyISAM or InnoDB or any other. To perform an online backup of InnoDB tables, mysqldump provides the --single-transaction option. With this option set, InnoDB tables will not be locked and will be available to other applications while backup is in progress.
Oracle provides the MySQL Enterprise backup tool for MySQL Enterprise edition users. This tool includes features such as incremental and compressed backups. Alternatively, Percona provides an open source utility known as Xtrabackup. It provides incremental and compressed backups and many more features.
Some other backup methods include copying MySQL table files and the mysqlhotcopy script for InnoDB tables. For these methods to work, you may need to pause or stop the MySQL server before backup.
You can also enable replication to mirror all data to the other server. It is a mechanism to maintain multiple copies of data by automatically copying data from one system to another. In this case, the primary server is called Master and the secondary server is called Slave. This type of configuration is known as Master-Slave replication. Generally, applications communicate with the Master server for all read and write requests. The Slave is used as a backup if the Master goes down. Many times, the Master-Slave configuration is used to load balance database queries by routing all read requests to the Slave server and write requests to the Master server. Replication can also be configured in Master-Master mode, where both servers receive read-write requests from clients.
See also
- MySQL backup methods at http://dev.mysql.com/doc/refman/5.6/en/backup-methods.html
- Percona XtraBackup at https://www.percona.com/doc/percona-xtrabackup/2.2/index.html
- MySQL binary log at http://dev.mysql.com/doc/refman/5.6/en/binary-log.html
See also
- MySQL backup methods at http://dev.mysql.com/doc/refman/5.6/en/backup-methods.html
- Percona XtraBackup at https://www.percona.com/doc/percona-xtrabackup/2.2/index.html
- MySQL binary log at http://dev.mysql.com/doc/refman/5.6/en/binary-log.html
Optimizing MySQL performance – queries
MySQL performance optimizations can be divided into two parts. One is query optimization and the other is MySQL server configuration. To get optimum results, you have to work on both of these parts. Without proper configuration, queries will not provide consistent performance; on the other hand, without proper queries and a database structure, queries may take much longer to produce results.
In this recipe, we will learn how to evaluate query performance, set indexes, and identify the optimum database structure for our data.
Getting ready
You will need access to an admin account on the MySQL server.
You will need a large dataset to test queries. Various tools are available to generate test data. I will be using test data available at https://github.com/datacharmer/test_db.
How to do it…
Follow these steps to optimize MySQL performance:
- The first and most basic thing is to identify key columns and add indexes to them:
mysql> alter table salaries add index (salary); - Enable the slow query log to identify long-running queries. Enter the following commands from the MySQL console:
mysql> set global log_slow_queries = 1; mysql> set global slow_query_log_file = ‘/var/log/mysql/slow.log’;
- Once you identify the slow and repeated query, execute that query on the database and record query timings. The following is a sample query:
mysql> select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’;
- Next, use
explainto view the query execution plan:mysql> explain select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’;
- Add required indexes, if any, and recheck the query execution plan. Your new index should be listed under
possible_keysand key columns ofexplainoutput:mysql> alter table `salaries` add index ( `from_date` ) ; - If you found that MySQL is not using a proper index or using another index than expected then you can explicitly specify the index to be used or ignored:
mysql> select * from salaries use index (salaries) where salary between 30000 and 65000 and from_date > ‘1986-01-01’; mysql> select * from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’ ignore index (from_date);
Now execute the query again and check query timings for any improvements.
- Analyze your data and modify the table structure. The following query will show the minimum and maximum length of data in each column. Add a small amount of buffer space to the reported maximum length and reduce additional space allocation if any:
mysql> select * from `employees` procedure analyse();The following is the partial output for the
analyse()procedure:
- Check the database engines you are using. The two major engines available in MySQL are MyISAM and InnoDB:
mysql> show create table employees;
How it works…
MySQL uses SQL to accept commands for data processing. The query contains the operation, such as select, insert, and update; the target that is a table name; and conditions to match the data. The following is an example query:
select * from employee where id = 1001;
In the preceding query, select * is the operation asking MySQL to select all data for a row. The target is the employee table, and id = 1001 is a condition part.
Once a query is received, MySQL generates query execution plan for it. This step contains various steps such as parsing, preprocessing, and optimization. In parsing and pre-processing, the query is checked for any syntactical errors and the proper order of SQL grammar. The given query can be executed in multiple ways. Query optimizer selects the best possible path for query execution. Finally, the query is executed and the execution plan is stored in the query cache for later use.
The query execution plan can be retrieved from MySQL with the help of the explain query and explain extended. Explain executes the query until the generation of the query execution plan and then returns the execution plan as a result. The execution plan contains table names used in this query, key fields used to search data, the number of rows needed to be scanned, and temporary tables and file sorting used, if any. The query execution plan shows possible keys that can be used for query execution and then shows the actual key column used. Key is a column with an index on it, which can be a primary index, unique index, or non-unique index. You can check the MySQL documentation for more details on query execution plans and explain output.
If a specific column in a table is being used repeatedly, you should consider adding a proper index to that column. Indexes group similar data together, which reduces the look up time and total number of rows to be scanned. Also keep in mind that indexes use large amounts of memory, so be selective while adding indexes.
Secondly, if you have a proper index set on a required column and the query optimization plan does not recognize or use the index, you can force MySQL to use a specific index with the USE INDEX index_name statement. To ignore a specific index, use the statement IGNORE INDEX index_name.
You may get a small improvement with table maintenance commands. Optimize table is useful when a large part of the table is modified or deleted. It reorganizes table index data on physical storage and improves I/O performance. Flush table is used to reload the internal cache. Check table and Analyze table check for table errors and data distribution respectively. The improvements with these commands may not be significant for smaller tables. Reducing the extra space allocated to each column is also a good idea for reducing total physical storage used. Reduced storage will optimize I/O performance as well as cache utilization.
You should also check the storage engines used by specific tables. The two major storage engines used in MySQL are MyISAM and InnoDB. InnnoDB provides full transactional support and uses row-level locking, whereas MyISAM does not have transaction support and uses table-level locking. MyISAM is a good choice for faster reads where you have a large amount of data with limited writes on the table. MySQL does support the addition of external storage engines in the form of plugins. One popular open source storage engine is XtraDB by Percona systems.
There’s more…
If your tables are really large, you should consider partitioning them. Partitioning tables distributes related data across multiple files on disk. Partitioning on frequently used keys can give you a quick boost. MySQL supports various different types of partitioning such as hash partitions, range partitions, list partitions, key partitions, and also sub-partitions.
You can specify hash partitioning with table creation as follows:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
store_id int
) partition by hash(store_id) partitions 4;Alternatively, you can also partition an existing table with the following query:
mysql> alter table employees partition by hash(store_id) partitions 4;
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
Getting ready
You will need access to an admin account on the MySQL server.
You will need a large dataset to test queries. Various tools are available to generate test data. I will be using test data available at https://github.com/datacharmer/test_db.
How to do it…
Follow these steps to optimize MySQL performance:
- The first and most basic thing is to identify key columns and add indexes to them:
mysql> alter table salaries add index (salary); - Enable the slow query log to identify long-running queries. Enter the following commands from the MySQL console:
mysql> set global log_slow_queries = 1; mysql> set global slow_query_log_file = ‘/var/log/mysql/slow.log’;
- Once you identify the slow and repeated query, execute that query on the database and record query timings. The following is a sample query:
mysql> select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’; - Next, use
explainto view the query execution plan:mysql> explain select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’; - Add required indexes, if any, and recheck the query execution plan. Your new index should be listed under
possible_keysand key columns ofexplainoutput:mysql> alter table `salaries` add index ( `from_date` ) ; - If you found that MySQL is not using a proper index or using another index than expected then you can explicitly specify the index to be used or ignored:
mysql> select * from salaries use index (salaries) where salary between 30000 and 65000 and from_date > ‘1986-01-01’; mysql> select * from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’ ignore index (from_date);
Now execute the query again and check query timings for any improvements.
- Analyze your data and modify the table structure. The following query will show the minimum and maximum length of data in each column. Add a small amount of buffer space to the reported maximum length and reduce additional space allocation if any:
mysql> select * from `employees` procedure analyse();The following is the partial output for the
analyse()procedure: - Check the database engines you are using. The two major engines available in MySQL are MyISAM and InnoDB:
mysql> show create table employees;
How it works…
MySQL uses SQL to accept commands for data processing. The query contains the operation, such as select, insert, and update; the target that is a table name; and conditions to match the data. The following is an example query:
select * from employee where id = 1001;
In the preceding query, select * is the operation asking MySQL to select all data for a row. The target is the employee table, and id = 1001 is a condition part.
Once a query is received, MySQL generates query execution plan for it. This step contains various steps such as parsing, preprocessing, and optimization. In parsing and pre-processing, the query is checked for any syntactical errors and the proper order of SQL grammar. The given query can be executed in multiple ways. Query optimizer selects the best possible path for query execution. Finally, the query is executed and the execution plan is stored in the query cache for later use.
The query execution plan can be retrieved from MySQL with the help of the explain query and explain extended. Explain executes the query until the generation of the query execution plan and then returns the execution plan as a result. The execution plan contains table names used in this query, key fields used to search data, the number of rows needed to be scanned, and temporary tables and file sorting used, if any. The query execution plan shows possible keys that can be used for query execution and then shows the actual key column used. Key is a column with an index on it, which can be a primary index, unique index, or non-unique index. You can check the MySQL documentation for more details on query execution plans and explain output.
If a specific column in a table is being used repeatedly, you should consider adding a proper index to that column. Indexes group similar data together, which reduces the look up time and total number of rows to be scanned. Also keep in mind that indexes use large amounts of memory, so be selective while adding indexes.
Secondly, if you have a proper index set on a required column and the query optimization plan does not recognize or use the index, you can force MySQL to use a specific index with the USE INDEX index_name statement. To ignore a specific index, use the statement IGNORE INDEX index_name.
You may get a small improvement with table maintenance commands. Optimize table is useful when a large part of the table is modified or deleted. It reorganizes table index data on physical storage and improves I/O performance. Flush table is used to reload the internal cache. Check table and Analyze table check for table errors and data distribution respectively. The improvements with these commands may not be significant for smaller tables. Reducing the extra space allocated to each column is also a good idea for reducing total physical storage used. Reduced storage will optimize I/O performance as well as cache utilization.
You should also check the storage engines used by specific tables. The two major storage engines used in MySQL are MyISAM and InnoDB. InnnoDB provides full transactional support and uses row-level locking, whereas MyISAM does not have transaction support and uses table-level locking. MyISAM is a good choice for faster reads where you have a large amount of data with limited writes on the table. MySQL does support the addition of external storage engines in the form of plugins. One popular open source storage engine is XtraDB by Percona systems.
There’s more…
If your tables are really large, you should consider partitioning them. Partitioning tables distributes related data across multiple files on disk. Partitioning on frequently used keys can give you a quick boost. MySQL supports various different types of partitioning such as hash partitions, range partitions, list partitions, key partitions, and also sub-partitions.
You can specify hash partitioning with table creation as follows:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
store_id int
) partition by hash(store_id) partitions 4;Alternatively, you can also partition an existing table with the following query:
mysql> alter table employees partition by hash(store_id) partitions 4;
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
How to do it…
Follow these steps to optimize MySQL performance:
- The first and most basic thing is to identify key columns and add indexes to them:
mysql> alter table salaries add index (salary); - Enable the slow query log to identify long-running queries. Enter the following commands from the MySQL console:
mysql> set global log_slow_queries = 1; mysql> set global slow_query_log_file = ‘/var/log/mysql/slow.log’;
- Once you identify the slow and repeated query, execute that query on the database and record query timings. The following is a sample query:
mysql> select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’; - Next, use
explainto view the query execution plan:mysql> explain select count(*) from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’; - Add required indexes, if any, and recheck the query execution plan. Your new index should be listed under
possible_keysand key columns ofexplainoutput:mysql> alter table `salaries` add index ( `from_date` ) ; - If you found that MySQL is not using a proper index or using another index than expected then you can explicitly specify the index to be used or ignored:
mysql> select * from salaries use index (salaries) where salary between 30000 and 65000 and from_date > ‘1986-01-01’; mysql> select * from salaries where salary between 30000 and 65000 and from_date > ‘1986-01-01’ ignore index (from_date);
Now execute the query again and check query timings for any improvements.
- Analyze your data and modify the table structure. The following query will show the minimum and maximum length of data in each column. Add a small amount of buffer space to the reported maximum length and reduce additional space allocation if any:
mysql> select * from `employees` procedure analyse();The following is the partial output for the
analyse()procedure: - Check the database engines you are using. The two major engines available in MySQL are MyISAM and InnoDB:
mysql> show create table employees;
How it works…
MySQL uses SQL to accept commands for data processing. The query contains the operation, such as select, insert, and update; the target that is a table name; and conditions to match the data. The following is an example query:
select * from employee where id = 1001;
In the preceding query, select * is the operation asking MySQL to select all data for a row. The target is the employee table, and id = 1001 is a condition part.
Once a query is received, MySQL generates query execution plan for it. This step contains various steps such as parsing, preprocessing, and optimization. In parsing and pre-processing, the query is checked for any syntactical errors and the proper order of SQL grammar. The given query can be executed in multiple ways. Query optimizer selects the best possible path for query execution. Finally, the query is executed and the execution plan is stored in the query cache for later use.
The query execution plan can be retrieved from MySQL with the help of the explain query and explain extended. Explain executes the query until the generation of the query execution plan and then returns the execution plan as a result. The execution plan contains table names used in this query, key fields used to search data, the number of rows needed to be scanned, and temporary tables and file sorting used, if any. The query execution plan shows possible keys that can be used for query execution and then shows the actual key column used. Key is a column with an index on it, which can be a primary index, unique index, or non-unique index. You can check the MySQL documentation for more details on query execution plans and explain output.
If a specific column in a table is being used repeatedly, you should consider adding a proper index to that column. Indexes group similar data together, which reduces the look up time and total number of rows to be scanned. Also keep in mind that indexes use large amounts of memory, so be selective while adding indexes.
Secondly, if you have a proper index set on a required column and the query optimization plan does not recognize or use the index, you can force MySQL to use a specific index with the USE INDEX index_name statement. To ignore a specific index, use the statement IGNORE INDEX index_name.
You may get a small improvement with table maintenance commands. Optimize table is useful when a large part of the table is modified or deleted. It reorganizes table index data on physical storage and improves I/O performance. Flush table is used to reload the internal cache. Check table and Analyze table check for table errors and data distribution respectively. The improvements with these commands may not be significant for smaller tables. Reducing the extra space allocated to each column is also a good idea for reducing total physical storage used. Reduced storage will optimize I/O performance as well as cache utilization.
You should also check the storage engines used by specific tables. The two major storage engines used in MySQL are MyISAM and InnoDB. InnnoDB provides full transactional support and uses row-level locking, whereas MyISAM does not have transaction support and uses table-level locking. MyISAM is a good choice for faster reads where you have a large amount of data with limited writes on the table. MySQL does support the addition of external storage engines in the form of plugins. One popular open source storage engine is XtraDB by Percona systems.
There’s more…
If your tables are really large, you should consider partitioning them. Partitioning tables distributes related data across multiple files on disk. Partitioning on frequently used keys can give you a quick boost. MySQL supports various different types of partitioning such as hash partitions, range partitions, list partitions, key partitions, and also sub-partitions.
You can specify hash partitioning with table creation as follows:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
store_id int
) partition by hash(store_id) partitions 4;Alternatively, you can also partition an existing table with the following query:
mysql> alter table employees partition by hash(store_id) partitions 4;
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
How it works…
MySQL uses SQL to accept commands for data processing. The query contains the operation, such as select, insert, and update; the target that is a table name; and conditions to match the data. The following is an example query:
select * from employee where id = 1001;
In the preceding query, select * is the operation asking MySQL to select all data for a row. The target is the employee table, and id = 1001 is a condition part.
Once a query is received, MySQL generates query execution plan for it. This step contains various steps such as parsing, preprocessing, and optimization. In parsing and pre-processing, the query is checked for any syntactical errors and the proper order of SQL grammar. The given query can be executed in multiple ways. Query optimizer selects the best possible path for query execution. Finally, the query is executed and the execution plan is stored in the query cache for later use.
The query execution plan can be retrieved from MySQL with the help of the explain query and explain extended. Explain executes the query until the generation of the query execution plan and then returns the execution plan as a result. The execution plan contains table names used in this query, key fields used to search data, the number of rows needed to be scanned, and temporary tables and file sorting used, if any. The query execution plan shows possible keys that can be used for query execution and then shows the actual key column used. Key is a column with an index on it, which can be a primary index, unique index, or non-unique index. You can check the MySQL documentation for more details on query execution plans and explain output.
If a specific column in a table is being used repeatedly, you should consider adding a proper index to that column. Indexes group similar data together, which reduces the look up time and total number of rows to be scanned. Also keep in mind that indexes use large amounts of memory, so be selective while adding indexes.
Secondly, if you have a proper index set on a required column and the query optimization plan does not recognize or use the index, you can force MySQL to use a specific index with the USE INDEX index_name statement. To ignore a specific index, use the statement IGNORE INDEX index_name.
You may get a small improvement with table maintenance commands. Optimize table is useful when a large part of the table is modified or deleted. It reorganizes table index data on physical storage and improves I/O performance. Flush table is used to reload the internal cache. Check table and Analyze table check for table errors and data distribution respectively. The improvements with these commands may not be significant for smaller tables. Reducing the extra space allocated to each column is also a good idea for reducing total physical storage used. Reduced storage will optimize I/O performance as well as cache utilization.
You should also check the storage engines used by specific tables. The two major storage engines used in MySQL are MyISAM and InnoDB. InnnoDB provides full transactional support and uses row-level locking, whereas MyISAM does not have transaction support and uses table-level locking. MyISAM is a good choice for faster reads where you have a large amount of data with limited writes on the table. MySQL does support the addition of external storage engines in the form of plugins. One popular open source storage engine is XtraDB by Percona systems.
There’s more…
If your tables are really large, you should consider partitioning them. Partitioning tables distributes related data across multiple files on disk. Partitioning on frequently used keys can give you a quick boost. MySQL supports various different types of partitioning such as hash partitions, range partitions, list partitions, key partitions, and also sub-partitions.
You can specify hash partitioning with table creation as follows:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
store_id int
) partition by hash(store_id) partitions 4;Alternatively, you can also partition an existing table with the following query:
mysql> alter table employees partition by hash(store_id) partitions 4;
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
There’s more…
If your tables are really large, you should consider partitioning them. Partitioning tables distributes related data across multiple files on disk. Partitioning on frequently used keys can give you a quick boost. MySQL supports various different types of partitioning such as hash partitions, range partitions, list partitions, key partitions, and also sub-partitions.
You can specify hash partitioning with table creation as follows:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
store_id int
) partition by hash(store_id) partitions 4;Alternatively, you can also partition an existing table with the following query:
mysql> alter table employees partition by hash(store_id) partitions 4;
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
Sharding MySQL
You can also shard your database. Sharding is a form of horizontal partitioning where you store part of the table data across multiple instances of a table. The table instance can exist on the same server under separate databases or across different servers. Each table instance contains parts of the total data, thus improving queries that need to access limited data. Sharding enables you to scale a database horizontally across multiple servers.
The best implementation strategy for sharding is to try to avoid it for as long as possible. Sharding requires additional maintenance efforts on the operations side and the use of proxy software to hide sharding from an application, or to make your application itself sharding aware. Sharding also adds limitations on queries that require access to the entire table. You will need to create cross-server joins or process data in the application layer.
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
See also
- The MySQL optimization guide at https://dev.mysql.com/doc/refman/5.6/en/optimization.html
- MySQL query execution plan information at https://dev.mysql.com/doc/refman/5.6/en/execution-plan-information.html
- InnoDB storage engine at https://dev.mysql.com/doc/refman/5.6/en/innodb-storage-engine.html
- Other storage engines available in MySQL at https://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- Table maintenance statements at http://dev.mysql.com/doc/refman/5.6/en/table-maintenance-sql.html
- MySQL test database at https://github.com/datacharmer/test_db
Optimizing MySQL performance – configuration
MySQL has hundreds of settings that can be configured. Version 5.7 ships with many improvements in default configuration values and requires far fewer changes. In this recipe, we will look at some of the most important parameters for tuning MySQL performance.
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need access to a root account on the MySQL server.
How to do it…
Follow these steps to improve MySQL configuration:
- First, create a backup of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Now open
my.cnffor changes:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf - Adjust the following settings for your InnoDB tables:
innodb_buffer_pool_size = 512M # around 70% of total ram innodb_log_file_size = 64M innodb_file_per_table = 1 innodb_log_buffer_size = 4M
- If you are using MyISAM tables, set the key buffer size:
key_buffer_size = 64M - Enable the slow query log:
slow_query_log = 1 slow_query_log_file = /var/lib/mysql/mysql-slow.log long_query_time = 2
- Disable the query cache:
query_cache_size = 0 - Set the maximum connections as per your requirements:
max_connections = 300 - Increase the temporary table size:
tmp_table_size = 32M - Increase
max_allowed_packetto increase the maximum packet size:max_allowed_packet = 32M - Enable binary logging for easy recovery and replication:
log_bin = /var/log/mysql/mysql-bin.log - Additionally, you can use
mysqltuner.pl, which gives general recommendations about the MySQL best practices:$ wget http://mysqltuner.pl/ -O mysqltuner.pl $ perl mysqltuner.pl
How it works…
The preceding example shows some important settings for MySQL performance tuning. Ensure that you change one setting at a time and assess its results. There is no silver bullet that works for all, and similarly, some of these settings may or may not work for you. Secondly, most settings can be changed at runtime with a SET statement. You can test settings in runtime and easily reverse them if they do not work as expected. Once you are sure that settings work as expected, you can move them to the configuration file.
The following are details on the preceding settings:
innodb_buffer_pool_size: the size of the cache where InnoDB data and indexes are cached. The larger the buffer pool, the more data can be cached in it. You can set this to around 70% of available physical memory as MySQL uses extra memory beyond this buffer. It is assumed that MySQL is the only service running on server.log_file_size: the size of the redo logs. These logs are helpful in faster writes and crash recovery.innodb_file_per_table: This determines whether to use shared table space or separate files for each table. MySQL 5.7 defaults this setting to ON.key_buffer_size: determines the key buffer for MyISAM tables.slow_query_logandlong_query_timeenable slow query logging and set slow query time respectively. Slow query logging can be useful for identifying repeated slow queries.Query_cache_sizecaches the result of a query. It is identified as a bottleneck for concurrent queries and MySQL 5.6 disables it by default.max_connectionssets the number of maximum concurrent connections allowed. Set this value as per your application's requirements. Higher values may result in higher memory consumption and an unresponsive server. Use connection pooling in the application if possible.max_allowed_packetsets the size of the packet size that MySQL can send at a time. Increase this value if your server runs queries with large result sets.mysqldset it to16Mandmysqldumpset it to24M. You can also set this as a command-line parameter.log_binenables binary logging, which can be used for replication and also for crash recovery. Make sure that you set proper rotation values to avoid large dump files.
There’s more…
MySQL performance tuning primer script: This script takes information from show status and show variables statements. It gives recommendations for various settings such as slow query log, max connections, query cache, key buffers, and many others. This shell script is available at http://day32.com/MySQL.
You can download and use this script as follows:
$ wget http://day32.com/MySQL/tuning-primer.sh $ sh tuning-primer.sh
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need access to a root account on the MySQL server.
How to do it…
Follow these steps to improve MySQL configuration:
- First, create a backup of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Now open
my.cnffor changes:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf - Adjust the following settings for your InnoDB tables:
innodb_buffer_pool_size = 512M # around 70% of total ram innodb_log_file_size = 64M innodb_file_per_table = 1 innodb_log_buffer_size = 4M
- If you are using MyISAM tables, set the key buffer size:
key_buffer_size = 64M - Enable the slow query log:
slow_query_log = 1 slow_query_log_file = /var/lib/mysql/mysql-slow.log long_query_time = 2
- Disable the query cache:
query_cache_size = 0 - Set the maximum connections as per your requirements:
max_connections = 300 - Increase the temporary table size:
tmp_table_size = 32M - Increase
max_allowed_packetto increase the maximum packet size:max_allowed_packet = 32M - Enable binary logging for easy recovery and replication:
log_bin = /var/log/mysql/mysql-bin.log - Additionally, you can use
mysqltuner.pl, which gives general recommendations about the MySQL best practices:$ wget http://mysqltuner.pl/ -O mysqltuner.pl $ perl mysqltuner.pl
How it works…
The preceding example shows some important settings for MySQL performance tuning. Ensure that you change one setting at a time and assess its results. There is no silver bullet that works for all, and similarly, some of these settings may or may not work for you. Secondly, most settings can be changed at runtime with a SET statement. You can test settings in runtime and easily reverse them if they do not work as expected. Once you are sure that settings work as expected, you can move them to the configuration file.
The following are details on the preceding settings:
innodb_buffer_pool_size: the size of the cache where InnoDB data and indexes are cached. The larger the buffer pool, the more data can be cached in it. You can set this to around 70% of available physical memory as MySQL uses extra memory beyond this buffer. It is assumed that MySQL is the only service running on server.log_file_size: the size of the redo logs. These logs are helpful in faster writes and crash recovery.innodb_file_per_table: This determines whether to use shared table space or separate files for each table. MySQL 5.7 defaults this setting to ON.key_buffer_size: determines the key buffer for MyISAM tables.slow_query_logandlong_query_timeenable slow query logging and set slow query time respectively. Slow query logging can be useful for identifying repeated slow queries.Query_cache_sizecaches the result of a query. It is identified as a bottleneck for concurrent queries and MySQL 5.6 disables it by default.max_connectionssets the number of maximum concurrent connections allowed. Set this value as per your application's requirements. Higher values may result in higher memory consumption and an unresponsive server. Use connection pooling in the application if possible.max_allowed_packetsets the size of the packet size that MySQL can send at a time. Increase this value if your server runs queries with large result sets.mysqldset it to16Mandmysqldumpset it to24M. You can also set this as a command-line parameter.log_binenables binary logging, which can be used for replication and also for crash recovery. Make sure that you set proper rotation values to avoid large dump files.
There’s more…
MySQL performance tuning primer script: This script takes information from show status and show variables statements. It gives recommendations for various settings such as slow query log, max connections, query cache, key buffers, and many others. This shell script is available at http://day32.com/MySQL.
You can download and use this script as follows:
$ wget http://day32.com/MySQL/tuning-primer.sh $ sh tuning-primer.sh
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
How to do it…
Follow these steps to improve MySQL configuration:
- First, create a backup of the original configuration file:
$ cd /etc/mysql/mysql.conf.d $ sudo cp mysqld.cnf mysqld.cnf.bkp
- Now open
my.cnffor changes:$ sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf - Adjust the following settings for your InnoDB tables:
innodb_buffer_pool_size = 512M # around 70% of total ram innodb_log_file_size = 64M innodb_file_per_table = 1 innodb_log_buffer_size = 4M
- If you are using MyISAM tables, set the key buffer size:
key_buffer_size = 64M - Enable the slow query log:
slow_query_log = 1 slow_query_log_file = /var/lib/mysql/mysql-slow.log long_query_time = 2
- Disable the query cache:
query_cache_size = 0 - Set the maximum connections as per your requirements:
max_connections = 300 - Increase the temporary table size:
tmp_table_size = 32M - Increase
max_allowed_packetto increase the maximum packet size:max_allowed_packet = 32M - Enable binary logging for easy recovery and replication:
log_bin = /var/log/mysql/mysql-bin.log - Additionally, you can use
mysqltuner.pl, which gives general recommendations about the MySQL best practices:$ wget http://mysqltuner.pl/ -O mysqltuner.pl $ perl mysqltuner.pl
How it works…
The preceding example shows some important settings for MySQL performance tuning. Ensure that you change one setting at a time and assess its results. There is no silver bullet that works for all, and similarly, some of these settings may or may not work for you. Secondly, most settings can be changed at runtime with a SET statement. You can test settings in runtime and easily reverse them if they do not work as expected. Once you are sure that settings work as expected, you can move them to the configuration file.
The following are details on the preceding settings:
innodb_buffer_pool_size: the size of the cache where InnoDB data and indexes are cached. The larger the buffer pool, the more data can be cached in it. You can set this to around 70% of available physical memory as MySQL uses extra memory beyond this buffer. It is assumed that MySQL is the only service running on server.log_file_size: the size of the redo logs. These logs are helpful in faster writes and crash recovery.innodb_file_per_table: This determines whether to use shared table space or separate files for each table. MySQL 5.7 defaults this setting to ON.key_buffer_size: determines the key buffer for MyISAM tables.slow_query_logandlong_query_timeenable slow query logging and set slow query time respectively. Slow query logging can be useful for identifying repeated slow queries.Query_cache_sizecaches the result of a query. It is identified as a bottleneck for concurrent queries and MySQL 5.6 disables it by default.max_connectionssets the number of maximum concurrent connections allowed. Set this value as per your application's requirements. Higher values may result in higher memory consumption and an unresponsive server. Use connection pooling in the application if possible.max_allowed_packetsets the size of the packet size that MySQL can send at a time. Increase this value if your server runs queries with large result sets.mysqldset it to16Mandmysqldumpset it to24M. You can also set this as a command-line parameter.log_binenables binary logging, which can be used for replication and also for crash recovery. Make sure that you set proper rotation values to avoid large dump files.
There’s more…
MySQL performance tuning primer script: This script takes information from show status and show variables statements. It gives recommendations for various settings such as slow query log, max connections, query cache, key buffers, and many others. This shell script is available at http://day32.com/MySQL.
You can download and use this script as follows:
$ wget http://day32.com/MySQL/tuning-primer.sh $ sh tuning-primer.sh
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
How it works…
The preceding example shows some important settings for MySQL performance tuning. Ensure that you change one setting at a time and assess its results. There is no silver bullet that works for all, and similarly, some of these settings may or may not work for you. Secondly, most settings can be changed at runtime with a SET statement. You can test settings in runtime and easily reverse them if they do not work as expected. Once you are sure that settings work as expected, you can move them to the configuration file.
The following are details on the preceding settings:
innodb_buffer_pool_size: the size of the cache where InnoDB data and indexes are cached. The larger the buffer pool, the more data can be cached in it. You can set this to around 70% of available physical memory as MySQL uses extra memory beyond this buffer. It is assumed that MySQL is the only service running on server.log_file_size: the size of the redo logs. These logs are helpful in faster writes and crash recovery.innodb_file_per_table: This determines whether to use shared table space or separate files for each table. MySQL 5.7 defaults this setting to ON.key_buffer_size: determines the key buffer for MyISAM tables.slow_query_logandlong_query_timeenable slow query logging and set slow query time respectively. Slow query logging can be useful for identifying repeated slow queries.Query_cache_sizecaches the result of a query. It is identified as a bottleneck for concurrent queries and MySQL 5.6 disables it by default.max_connectionssets the number of maximum concurrent connections allowed. Set this value as per your application's requirements. Higher values may result in higher memory consumption and an unresponsive server. Use connection pooling in the application if possible.max_allowed_packetsets the size of the packet size that MySQL can send at a time. Increase this value if your server runs queries with large result sets.mysqldset it to16Mandmysqldumpset it to24M. You can also set this as a command-line parameter.log_binenables binary logging, which can be used for replication and also for crash recovery. Make sure that you set proper rotation values to avoid large dump files.
There’s more…
MySQL performance tuning primer script: This script takes information from show status and show variables statements. It gives recommendations for various settings such as slow query log, max connections, query cache, key buffers, and many others. This shell script is available at http://day32.com/MySQL.
You can download and use this script as follows:
$ wget http://day32.com/MySQL/tuning-primer.sh $ sh tuning-primer.sh
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
There’s more…
MySQL performance tuning primer script: This script takes information from show status and show variables statements. It gives recommendations for various settings such as slow query log, max connections, query cache, key buffers, and many others. This shell script is available at http://day32.com/MySQL.
You can download and use this script as follows:
$ wget http://day32.com/MySQL/tuning-primer.sh $ sh tuning-primer.sh
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
Percona configuration wizard
Percona systems provide a developer-friendly, web-based configuration wizard to create a configuration file for your MySQL server. The wizard is available at http://tools.percona.com
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
MySQL table compression
Depending on the type of data, you can opt for compressed tables. Compression is useful for tables with long textual contents and read-intensive workloads. Data and indexes are stored in a compressed format, resulting in reduced I/O and a smaller database size, though it needs more CPU cycles to compress and uncompress data. To enable compression, you need an InnoDB storage engine with innodb_file_per_table enabled and the file format set to Barracuda. Check MySQL documents for more details on InnoDB compression at https://dev.mysql.com/doc/innodb/1.1/en/innodb-compression.html.
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
See also
- MySQL tuner script at https://github.com/major/MySQLTuner-perl
- MySQL docs at https://dev.mysql.com/doc/refman/5.7/en/optimization.html
- InnoDB table compression at https://dev.mysql.com/doc/refman/5.7/en/innodb-table-compression.html
Creating MySQL replicas for scaling and high availability
When your application is small, you can use a single MySQL server for all your database needs. As your application becomes popular and you get more and more requests, the database starts becoming a bottleneck for application performance. With thousands of queries per second, the database write queue gets longer and read latency increases. To solve this problem, you can use multiple replicas of the same database and separate read and write queries between them.
In this recipe, we will learn how to set up replication with the MySQL server.
Getting ready
You will need two MySQL servers and access to administrative accounts on both.
Make sure that port 3306 is open and available on both servers.
How to do it…
Follow these steps to create MySQL replicas:
- Create the replication user on the Master server:
$ mysql -u root -p mysql> grant replication slave on *.* TO ‘slave_user’@’10.0.2.62’ identified by ‘password’; mysql> flush privileges; mysql> quit
- Edit the MySQL configuration on the Master server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.61 # your master server ip server-id = 1 log-bin = mysql-bin binlog-ignore-db = “mysql”
- Restart MySQL on the Master server:
$ sudo service mysql restart - Export MySQL databases on the Master server. Open the MySQL connection and lock the database to prevent any updates:
$ mysql -u root -p mysql> flush tables with read lock;
- Read the Master status on the Master server and take a note of it. This will be used shortly to configure the Slave server:
mysql> show master status;
- Open a separate terminal window and export the required databases. Add the names of all the databases you want to export:
$ mysqldump -u root -p --databases testdb > master_dump.sql - Now, unlock the tables after the database dump has completed:
mysql> UNLOCK TABLES; mysql> quit;
- Transfer the backup to the Slave server with any secure method:
$ scp master_backup.sql ubuntu@10.0.2.62:/home/ubuntu/master_backup.sql - Next, edit the configuration file on the Slave server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.62 server-id = 2 relay_log=relay-log
- Import the dump from the Master server. You may need to manually create a database before importing dumps:
$ mysqladmin -u admin -p create testdb $ mysql -u root -p < master_dump.sql
- Restart the MySQL server:
$ sudo service mysql restart - Now set the Master configuration on the Slave. Use the values we received from
show master statuscommand in step 5:$ mysql -u root -p mysql > change master to master_host=’10.0.2.61’, master_user=’slave_user’, master_password=’password’, master_log_file=’mysql-bin.000010’, master_log_pos=2214;
- Start the Slave:
mysql> start slave; - Check the Slave's status. You should see the message
Waiting for master to send eventunderSlave_IO_state:mysql> show slave status\G
Now you can test replication. Create a new database with a table and a few sample records on the Master server. You should see the database replicated on the Slave immediately.
How it works…
MySQL replication works with the help of binary logs generated on the Master server. MySQL logs any changes to the database to local binary logs with a lightweight buffered and sequential write process. These logs will then be read by the slave. When the slave connects to the Master, the Master creates a new thread for this replication connection and updates the slave with events in a binary log, notifying the slave about newly written events in binary logs.
On the slave side, two threads are started to handle replication. One is the IO thread, which connects to the Master and copies updates in binary logs to a local log file, relay_log. The other thread, which is known as the SQL thread, reads events stored on relay_log and applies them locally.
In the preceding recipe, we have configured Master-Slave replication. MySQL also supports Master-Master replication. In the case of Master-Slave configuration, the Master works as an active server, handling all writes to database. You can configure slaves to answer read queries, but most of the time, the slave server works as a passive backup server. If the Master fails, you manually need to promote the slave to take over as Master. This process may require downtime.
To overcome problems with Master - Slave replication, MySQL can be configured in Master-Master relation, where all servers act as a Master as well as a slave. Applications can read as well as write to all participating servers, and in case any Master goes down, other servers can still handle all application writes without any downtime. The problem with Master-Master configuration is that it’s quite difficult to set up and deploy. Additionally, maintaining data consistency across all servers is a challenge. This type of configuration is lazy and asynchronous and violates ACID properties.
In the preceding example, we configured the server-id variable in the my.cnf file. This needs to be unique on both servers. MySQL version 5.6 adds another UUID for the server, which is located at data_dir/auto.cnf. If you happen to copy data_dir from Master to host or are using a copy of a Master virtual machine as your starting point for a slave, you may get an error on the slave that reads something like master and slave have equal mysql server UUIDs. In this case, simply remove auto.cnf from the slave and restart the MySQL server.
There’s more…
You can set MySQL load balancing and configure your database for high availability with the help of a simple load balancer in front of MySQL. HAProxy is a well known load balancer that supports TCP load balancing and can be configured in a few steps, as follows:
- Set your MySQL servers to Master - Master replication mode.
- Log in to
mysqland create one user forhaproxyhealth checks and another for remote administration:mysql> create user ‘haproxy_admin’@’haproxy_ip’; mysql> grant all privileges on *.* to ‘haproxy_admin’@’haproxy_ip’ identified by ‘password’ with grant option; mysql> flush privileges;
- Next, install the MySQL client on the HAProxy server and try to log into the
mysqlserver with thehaproxy_adminaccount. - Install HAProxy and configure it to connect to
mysqlon the TCP port:listen mysql-cluster bind haproxy_ip:3306 mode tcp option mysql-check user haproxy_check balance roundrobin server mysql-1 mysql_srv_1_ip:3306 check server mysql-2 mysql_srv_2_ip:3306 check - Finally, start the
haproxyservice and try to connect to themysqlserver with thehaproxy_adminaccount:$ mysql -h haproxy_ip -u hapoxy_admin -p
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
Getting ready
You will need two MySQL servers and access to administrative accounts on both.
Make sure that port 3306 is open and available on both servers.
How to do it…
Follow these steps to create MySQL replicas:
- Create the replication user on the Master server:
$ mysql -u root -p mysql> grant replication slave on *.* TO ‘slave_user’@’10.0.2.62’ identified by ‘password’; mysql> flush privileges; mysql> quit
- Edit the MySQL configuration on the Master server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.61 # your master server ip server-id = 1 log-bin = mysql-bin binlog-ignore-db = “mysql”
- Restart MySQL on the Master server:
$ sudo service mysql restart - Export MySQL databases on the Master server. Open the MySQL connection and lock the database to prevent any updates:
$ mysql -u root -p mysql> flush tables with read lock;
- Read the Master status on the Master server and take a note of it. This will be used shortly to configure the Slave server:
mysql> show master status; - Open a separate terminal window and export the required databases. Add the names of all the databases you want to export:
$ mysqldump -u root -p --databases testdb > master_dump.sql - Now, unlock the tables after the database dump has completed:
mysql> UNLOCK TABLES; mysql> quit;
- Transfer the backup to the Slave server with any secure method:
$ scp master_backup.sql ubuntu@10.0.2.62:/home/ubuntu/master_backup.sql - Next, edit the configuration file on the Slave server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.62 server-id = 2 relay_log=relay-log
- Import the dump from the Master server. You may need to manually create a database before importing dumps:
$ mysqladmin -u admin -p create testdb $ mysql -u root -p < master_dump.sql
- Restart the MySQL server:
$ sudo service mysql restart - Now set the Master configuration on the Slave. Use the values we received from
show master statuscommand in step 5:$ mysql -u root -p mysql > change master to master_host=’10.0.2.61’, master_user=’slave_user’, master_password=’password’, master_log_file=’mysql-bin.000010’, master_log_pos=2214;
- Start the Slave:
mysql> start slave; - Check the Slave's status. You should see the message
Waiting for master to send eventunderSlave_IO_state:mysql> show slave status\G
Now you can test replication. Create a new database with a table and a few sample records on the Master server. You should see the database replicated on the Slave immediately.
How it works…
MySQL replication works with the help of binary logs generated on the Master server. MySQL logs any changes to the database to local binary logs with a lightweight buffered and sequential write process. These logs will then be read by the slave. When the slave connects to the Master, the Master creates a new thread for this replication connection and updates the slave with events in a binary log, notifying the slave about newly written events in binary logs.
On the slave side, two threads are started to handle replication. One is the IO thread, which connects to the Master and copies updates in binary logs to a local log file, relay_log. The other thread, which is known as the SQL thread, reads events stored on relay_log and applies them locally.
In the preceding recipe, we have configured Master-Slave replication. MySQL also supports Master-Master replication. In the case of Master-Slave configuration, the Master works as an active server, handling all writes to database. You can configure slaves to answer read queries, but most of the time, the slave server works as a passive backup server. If the Master fails, you manually need to promote the slave to take over as Master. This process may require downtime.
To overcome problems with Master - Slave replication, MySQL can be configured in Master-Master relation, where all servers act as a Master as well as a slave. Applications can read as well as write to all participating servers, and in case any Master goes down, other servers can still handle all application writes without any downtime. The problem with Master-Master configuration is that it’s quite difficult to set up and deploy. Additionally, maintaining data consistency across all servers is a challenge. This type of configuration is lazy and asynchronous and violates ACID properties.
In the preceding example, we configured the server-id variable in the my.cnf file. This needs to be unique on both servers. MySQL version 5.6 adds another UUID for the server, which is located at data_dir/auto.cnf. If you happen to copy data_dir from Master to host or are using a copy of a Master virtual machine as your starting point for a slave, you may get an error on the slave that reads something like master and slave have equal mysql server UUIDs. In this case, simply remove auto.cnf from the slave and restart the MySQL server.
There’s more…
You can set MySQL load balancing and configure your database for high availability with the help of a simple load balancer in front of MySQL. HAProxy is a well known load balancer that supports TCP load balancing and can be configured in a few steps, as follows:
- Set your MySQL servers to Master - Master replication mode.
- Log in to
mysqland create one user forhaproxyhealth checks and another for remote administration:mysql> create user ‘haproxy_admin’@’haproxy_ip’; mysql> grant all privileges on *.* to ‘haproxy_admin’@’haproxy_ip’ identified by ‘password’ with grant option; mysql> flush privileges;
- Next, install the MySQL client on the HAProxy server and try to log into the
mysqlserver with thehaproxy_adminaccount. - Install HAProxy and configure it to connect to
mysqlon the TCP port:listen mysql-cluster bind haproxy_ip:3306 mode tcp option mysql-check user haproxy_check balance roundrobin server mysql-1 mysql_srv_1_ip:3306 check server mysql-2 mysql_srv_2_ip:3306 check - Finally, start the
haproxyservice and try to connect to themysqlserver with thehaproxy_adminaccount:$ mysql -h haproxy_ip -u hapoxy_admin -p
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
How to do it…
Follow these steps to create MySQL replicas:
- Create the replication user on the Master server:
$ mysql -u root -p mysql> grant replication slave on *.* TO ‘slave_user’@’10.0.2.62’ identified by ‘password’; mysql> flush privileges; mysql> quit
- Edit the MySQL configuration on the Master server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.61 # your master server ip server-id = 1 log-bin = mysql-bin binlog-ignore-db = “mysql”
- Restart MySQL on the Master server:
$ sudo service mysql restart - Export MySQL databases on the Master server. Open the MySQL connection and lock the database to prevent any updates:
$ mysql -u root -p mysql> flush tables with read lock;
- Read the Master status on the Master server and take a note of it. This will be used shortly to configure the Slave server:
mysql> show master status; - Open a separate terminal window and export the required databases. Add the names of all the databases you want to export:
$ mysqldump -u root -p --databases testdb > master_dump.sql - Now, unlock the tables after the database dump has completed:
mysql> UNLOCK TABLES; mysql> quit;
- Transfer the backup to the Slave server with any secure method:
$ scp master_backup.sql ubuntu@10.0.2.62:/home/ubuntu/master_backup.sql - Next, edit the configuration file on the Slave server:
$ sudo nano /etc/mysql/my.cnf [mysqld] bind-address = 10.0.2.62 server-id = 2 relay_log=relay-log
- Import the dump from the Master server. You may need to manually create a database before importing dumps:
$ mysqladmin -u admin -p create testdb $ mysql -u root -p < master_dump.sql
- Restart the MySQL server:
$ sudo service mysql restart - Now set the Master configuration on the Slave. Use the values we received from
show master statuscommand in step 5:$ mysql -u root -p mysql > change master to master_host=’10.0.2.61’, master_user=’slave_user’, master_password=’password’, master_log_file=’mysql-bin.000010’, master_log_pos=2214;
- Start the Slave:
mysql> start slave; - Check the Slave's status. You should see the message
Waiting for master to send eventunderSlave_IO_state:mysql> show slave status\G
Now you can test replication. Create a new database with a table and a few sample records on the Master server. You should see the database replicated on the Slave immediately.
How it works…
MySQL replication works with the help of binary logs generated on the Master server. MySQL logs any changes to the database to local binary logs with a lightweight buffered and sequential write process. These logs will then be read by the slave. When the slave connects to the Master, the Master creates a new thread for this replication connection and updates the slave with events in a binary log, notifying the slave about newly written events in binary logs.
On the slave side, two threads are started to handle replication. One is the IO thread, which connects to the Master and copies updates in binary logs to a local log file, relay_log. The other thread, which is known as the SQL thread, reads events stored on relay_log and applies them locally.
In the preceding recipe, we have configured Master-Slave replication. MySQL also supports Master-Master replication. In the case of Master-Slave configuration, the Master works as an active server, handling all writes to database. You can configure slaves to answer read queries, but most of the time, the slave server works as a passive backup server. If the Master fails, you manually need to promote the slave to take over as Master. This process may require downtime.
To overcome problems with Master - Slave replication, MySQL can be configured in Master-Master relation, where all servers act as a Master as well as a slave. Applications can read as well as write to all participating servers, and in case any Master goes down, other servers can still handle all application writes without any downtime. The problem with Master-Master configuration is that it’s quite difficult to set up and deploy. Additionally, maintaining data consistency across all servers is a challenge. This type of configuration is lazy and asynchronous and violates ACID properties.
In the preceding example, we configured the server-id variable in the my.cnf file. This needs to be unique on both servers. MySQL version 5.6 adds another UUID for the server, which is located at data_dir/auto.cnf. If you happen to copy data_dir from Master to host or are using a copy of a Master virtual machine as your starting point for a slave, you may get an error on the slave that reads something like master and slave have equal mysql server UUIDs. In this case, simply remove auto.cnf from the slave and restart the MySQL server.
There’s more…
You can set MySQL load balancing and configure your database for high availability with the help of a simple load balancer in front of MySQL. HAProxy is a well known load balancer that supports TCP load balancing and can be configured in a few steps, as follows:
- Set your MySQL servers to Master - Master replication mode.
- Log in to
mysqland create one user forhaproxyhealth checks and another for remote administration:mysql> create user ‘haproxy_admin’@’haproxy_ip’; mysql> grant all privileges on *.* to ‘haproxy_admin’@’haproxy_ip’ identified by ‘password’ with grant option; mysql> flush privileges;
- Next, install the MySQL client on the HAProxy server and try to log into the
mysqlserver with thehaproxy_adminaccount. - Install HAProxy and configure it to connect to
mysqlon the TCP port:listen mysql-cluster bind haproxy_ip:3306 mode tcp option mysql-check user haproxy_check balance roundrobin server mysql-1 mysql_srv_1_ip:3306 check server mysql-2 mysql_srv_2_ip:3306 check - Finally, start the
haproxyservice and try to connect to themysqlserver with thehaproxy_adminaccount:$ mysql -h haproxy_ip -u hapoxy_admin -p
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
How it works…
MySQL replication works with the help of binary logs generated on the Master server. MySQL logs any changes to the database to local binary logs with a lightweight buffered and sequential write process. These logs will then be read by the slave. When the slave connects to the Master, the Master creates a new thread for this replication connection and updates the slave with events in a binary log, notifying the slave about newly written events in binary logs.
On the slave side, two threads are started to handle replication. One is the IO thread, which connects to the Master and copies updates in binary logs to a local log file, relay_log. The other thread, which is known as the SQL thread, reads events stored on relay_log and applies them locally.
In the preceding recipe, we have configured Master-Slave replication. MySQL also supports Master-Master replication. In the case of Master-Slave configuration, the Master works as an active server, handling all writes to database. You can configure slaves to answer read queries, but most of the time, the slave server works as a passive backup server. If the Master fails, you manually need to promote the slave to take over as Master. This process may require downtime.
To overcome problems with Master - Slave replication, MySQL can be configured in Master-Master relation, where all servers act as a Master as well as a slave. Applications can read as well as write to all participating servers, and in case any Master goes down, other servers can still handle all application writes without any downtime. The problem with Master-Master configuration is that it’s quite difficult to set up and deploy. Additionally, maintaining data consistency across all servers is a challenge. This type of configuration is lazy and asynchronous and violates ACID properties.
In the preceding example, we configured the server-id variable in the my.cnf file. This needs to be unique on both servers. MySQL version 5.6 adds another UUID for the server, which is located at data_dir/auto.cnf. If you happen to copy data_dir from Master to host or are using a copy of a Master virtual machine as your starting point for a slave, you may get an error on the slave that reads something like master and slave have equal mysql server UUIDs. In this case, simply remove auto.cnf from the slave and restart the MySQL server.
There’s more…
You can set MySQL load balancing and configure your database for high availability with the help of a simple load balancer in front of MySQL. HAProxy is a well known load balancer that supports TCP load balancing and can be configured in a few steps, as follows:
- Set your MySQL servers to Master - Master replication mode.
- Log in to
mysqland create one user forhaproxyhealth checks and another for remote administration:mysql> create user ‘haproxy_admin’@’haproxy_ip’; mysql> grant all privileges on *.* to ‘haproxy_admin’@’haproxy_ip’ identified by ‘password’ with grant option; mysql> flush privileges;
- Next, install the MySQL client on the HAProxy server and try to log into the
mysqlserver with thehaproxy_adminaccount. - Install HAProxy and configure it to connect to
mysqlon the TCP port:listen mysql-cluster bind haproxy_ip:3306 mode tcp option mysql-check user haproxy_check balance roundrobin server mysql-1 mysql_srv_1_ip:3306 check server mysql-2 mysql_srv_2_ip:3306 check - Finally, start the
haproxyservice and try to connect to themysqlserver with thehaproxy_adminaccount:$ mysql -h haproxy_ip -u hapoxy_admin -p
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
There’s more…
You can set MySQL load balancing and configure your database for high availability with the help of a simple load balancer in front of MySQL. HAProxy is a well known load balancer that supports TCP load balancing and can be configured in a few steps, as follows:
- Set your MySQL servers to Master - Master replication mode.
- Log in to
mysqland create one user forhaproxyhealth checks and another for remote administration:mysql> create user ‘haproxy_admin’@’haproxy_ip’; mysql> grant all privileges on *.* to ‘haproxy_admin’@’haproxy_ip’ identified by ‘password’ with grant option; mysql> flush privileges;
- Next, install the MySQL client on the HAProxy server and try to log into the
mysqlserver with thehaproxy_adminaccount. - Install HAProxy and configure it to connect to
mysqlon the TCP port:listen mysql-cluster bind haproxy_ip:3306 mode tcp option mysql-check user haproxy_check balance roundrobin server mysql-1 mysql_srv_1_ip:3306 check server mysql-2 mysql_srv_2_ip:3306 check - Finally, start the
haproxyservice and try to connect to themysqlserver with thehaproxy_adminaccount:$ mysql -h haproxy_ip -u hapoxy_admin -p
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
See also
- MySQL replication configuration at http://dev.mysql.com/doc/refman/5.6/en/replication.html
- How MySQL replication works at https://www.percona.com/blog/2013/01/09/how-does-mysql-replication-really-work/
- MySQL replication formats at http://dev.mysql.com/doc/refman/5.5/en/replication-formats.html
Troubleshooting MySQL
In this recipe, we will look at some common problems with MySQL and learn how to solve them.
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need administrative privileges on the MySQL server.
How to do it…
Follow these steps to troubleshoot MySQL:
- First, check if the MySQL server is running and listening for connections on the configured port:
$ sudo service mysql status $ sudo netstat -pltn
- Check MySQL logs for any error messages at
/var/log/mysql.logandmysql.err. - You can try to start the server in interactive mode with the
verboseflag set:$ which mysqld /usr/sbin/mysqld $ sudo /usr/sbin/mysqld --user=mysql --verbose
- If you are accessing MySQL from a remote system, make sure that the server is set to
listenon a public port. Check forbind-addressinmy.cnf:bind-address = 10.0.247.168 - For any access denied errors, check if you have a user account in place and if it is allowed to log in from a specific IP address:
mysql> select user, host, password from mysql.user where user = ‘username’; - Check the user has access to specified resources:
mysql > grant all privileges on databasename.* to ‘username’@’%’; - Check your firewall is not blocking connections to MySQL.
- If you get an error saying
mysql server has gone away, then increasewait_timeoutin the configuration file. Alternatively, you can re-initiate a connection on the client side after a specific timeout. - Use a
repair tablestatement to recover the crashed MyISAM table:$ mysql -u root -p mysql> repair table databasename.tablename;
- Alternatively, you can use the
mysqlcheckcommand to repair tables:$ mysqlcheck -u root -p --auto-repair \ --check --optimize databasename
See also
- InnoDB troubleshooting at https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting.html
Getting ready
You will need access to a root account or an account with sudo privileges.
You will need administrative privileges on the MySQL server.
How to do it…
Follow these steps to troubleshoot MySQL:
- First, check if the MySQL server is running and listening for connections on the configured port:
$ sudo service mysql status $ sudo netstat -pltn
- Check MySQL logs for any error messages at
/var/log/mysql.logandmysql.err. - You can try to start the server in interactive mode with the
verboseflag set:$ which mysqld /usr/sbin/mysqld $ sudo /usr/sbin/mysqld --user=mysql --verbose
- If you are accessing MySQL from a remote system, make sure that the server is set to
listenon a public port. Check forbind-addressinmy.cnf:bind-address = 10.0.247.168 - For any access denied errors, check if you have a user account in place and if it is allowed to log in from a specific IP address:
mysql> select user, host, password from mysql.user where user = ‘username’; - Check the user has access to specified resources:
mysql > grant all privileges on databasename.* to ‘username’@’%’; - Check your firewall is not blocking connections to MySQL.
- If you get an error saying
mysql server has gone away, then increasewait_timeoutin the configuration file. Alternatively, you can re-initiate a connection on the client side after a specific timeout. - Use a
repair tablestatement to recover the crashed MyISAM table:$ mysql -u root -p mysql> repair table databasename.tablename;
- Alternatively, you can use the
mysqlcheckcommand to repair tables:$ mysqlcheck -u root -p --auto-repair \ --check --optimize databasename
See also
- InnoDB troubleshooting at https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting.html
How to do it…
Follow these steps to troubleshoot MySQL:
- First, check if the MySQL server is running and listening for connections on the configured port:
$ sudo service mysql status $ sudo netstat -pltn
- Check MySQL logs for any error messages at
/var/log/mysql.logandmysql.err. - You can try to start the server in interactive mode with the
verboseflag set:$ which mysqld /usr/sbin/mysqld $ sudo /usr/sbin/mysqld --user=mysql --verbose
- If you are accessing MySQL from a remote system, make sure that the server is set to
listenon a public port. Check forbind-addressinmy.cnf:bind-address = 10.0.247.168 - For any access denied errors, check if you have a user account in place and if it is allowed to log in from a specific IP address:
mysql> select user, host, password from mysql.user where user = ‘username’; - Check the user has access to specified resources:
mysql > grant all privileges on databasename.* to ‘username’@’%’; - Check your firewall is not blocking connections to MySQL.
- If you get an error saying
mysql server has gone away, then increasewait_timeoutin the configuration file. Alternatively, you can re-initiate a connection on the client side after a specific timeout. - Use a
repair tablestatement to recover the crashed MyISAM table:$ mysql -u root -p mysql> repair table databasename.tablename;
- Alternatively, you can use the
mysqlcheckcommand to repair tables:$ mysqlcheck -u root -p --auto-repair \ --check --optimize databasename
See also
- InnoDB troubleshooting at https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting.html
See also
- InnoDB troubleshooting at https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting.html
Installing MongoDB
Until now, we have worked with the relational database server, MySQL. In this recipe, we will learn how to install and configure MongoDB, which is a not only SQL (NoSQL) document storage server.
Getting ready
You will need access to a root account or an account with sudo privileges.
How to do it…
To get the latest version of MongoDB, we need to add the MongoDB source to Ubuntu installation sources:
- First, import the MongoDB GPG public key:
$ sudo apt-key adv \ --keyserver hkp://keyserver.ubuntu.com:80 \ --recv 7F0CEB10
- Create a
listfile and add an install source to it:$ echo “deb http://repo.mongodb.org/apt/ubuntu “$(lsb_release -sc)”/mongodb-org/3.0 multiverse” | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list - Update the
aptrepository sources and install the MongoDB server:$ sudo apt-get update $ sudo apt-get install -y mongodb-org
- After installation completes, check the status of the MongoDB server:
$ sudo service mongod status - Now you can start using the MongoDB server. To access the Mongo shell, use the following command:
$ mongo
How it works…
We have installed the MongoDB server from the MongoDB official repository. The Ubuntu package repository includes the MongoDB package in it, but it is not up to date with the latest release of MongoDB. With GPG keys, Ubuntu ensures the authenticity of the packages being installed. After importing the GPG key, we have created a list file that contains the installation source of the MongoDB server.
After installation, the MongoDB service should start automatically. You can check logs at /var/log/mongodb/mongod.log.
See also
- MongoDB installation guide at http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
Getting ready
You will need access to a root account or an account with sudo privileges.
How to do it…
To get the latest version of MongoDB, we need to add the MongoDB source to Ubuntu installation sources:
- First, import the MongoDB GPG public key:
$ sudo apt-key adv \ --keyserver hkp://keyserver.ubuntu.com:80 \ --recv 7F0CEB10
- Create a
listfile and add an install source to it:$ echo “deb http://repo.mongodb.org/apt/ubuntu “$(lsb_release -sc)”/mongodb-org/3.0 multiverse” | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list - Update the
aptrepository sources and install the MongoDB server:$ sudo apt-get update $ sudo apt-get install -y mongodb-org
- After installation completes, check the status of the MongoDB server:
$ sudo service mongod status - Now you can start using the MongoDB server. To access the Mongo shell, use the following command:
$ mongo
How it works…
We have installed the MongoDB server from the MongoDB official repository. The Ubuntu package repository includes the MongoDB package in it, but it is not up to date with the latest release of MongoDB. With GPG keys, Ubuntu ensures the authenticity of the packages being installed. After importing the GPG key, we have created a list file that contains the installation source of the MongoDB server.
After installation, the MongoDB service should start automatically. You can check logs at /var/log/mongodb/mongod.log.
See also
- MongoDB installation guide at http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
How to do it…
To get the latest version of MongoDB, we need to add the MongoDB source to Ubuntu installation sources:
- First, import the MongoDB GPG public key:
$ sudo apt-key adv \ --keyserver hkp://keyserver.ubuntu.com:80 \ --recv 7F0CEB10
- Create a
listfile and add an install source to it:$ echo “deb http://repo.mongodb.org/apt/ubuntu “$(lsb_release -sc)”/mongodb-org/3.0 multiverse” | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list - Update the
aptrepository sources and install the MongoDB server:$ sudo apt-get update $ sudo apt-get install -y mongodb-org
- After installation completes, check the status of the MongoDB server:
$ sudo service mongod status - Now you can start using the MongoDB server. To access the Mongo shell, use the following command:
$ mongo
How it works…
We have installed the MongoDB server from the MongoDB official repository. The Ubuntu package repository includes the MongoDB package in it, but it is not up to date with the latest release of MongoDB. With GPG keys, Ubuntu ensures the authenticity of the packages being installed. After importing the GPG key, we have created a list file that contains the installation source of the MongoDB server.
After installation, the MongoDB service should start automatically. You can check logs at /var/log/mongodb/mongod.log.
See also
- MongoDB installation guide at http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
How it works…
We have installed the MongoDB server from the MongoDB official repository. The Ubuntu package repository includes the MongoDB package in it, but it is not up to date with the latest release of MongoDB. With GPG keys, Ubuntu ensures the authenticity of the packages being installed. After importing the GPG key, we have created a list file that contains the installation source of the MongoDB server.
After installation, the MongoDB service should start automatically. You can check logs at /var/log/mongodb/mongod.log.
See also
- MongoDB installation guide at http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
See also
- MongoDB installation guide at http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
Storing and retrieving data with MongoDB
In this recipe, we will look at basic CRUD operations with MongoDB. We will learn how to create databases, store, retrieve, and update stored data. This is a recipe to get started with MongoDB.
Getting ready
Make sure that you have installed and configured MongoDB. You can also use the MongoDB installation on a remote server.
How to do it…
Follow these steps to store and retrieve data with MongoDB:
- Open a shell to interact with the Mongo server:
$ mongo - To open a shell on a remote server, use the command given. Replace
server_ipandportwith the respective values:$ mongo server_ip:port/db - To create and start using a new database, type
use dbname. Since schemas in MongoDB are dynamic, you do not need to create a database before using it:> use testdb - You can type
helpin Mongo shell to get a list of available commands and help regarding a specific command:> help: Let’s insert our first document:> db.users.insert({‘name’:’ubuntu’,’uid’:1001})
- To view the created database and collection, use the following commands:
> show dbs
> show collections
- You can also insert multiple values for a key, for example, which groups a user belongs to:
> db.users.insert({‘name’:’root’,’uid’:1010, ‘gid’:[1010, 1000, 1111]}) - Check whether a document is successfully inserted:
> db.users.find()
- To get a single record, use
findOne():> db.users.findOne({uid:1010}) - To update an existing record, use the
updatecommand as follows:> db.users.update({name:’ubuntu’}, {$set:{uid:2222}}) - To remove a record, use the
removecommand. This will remove all records with anameequal toubuntu:> db.users.remove({‘name’:’ubuntu’}) - To drop an entire collection, use the
drop()command:> db.users.drop() - To drop a database, use the
dropDatabase()command:> db.users.dropDatabase()
How it works…
The preceding examples show very basic CRUD operations with the MongoDB shell interface. MongoDB shell is also a JavaScript shell. You can execute all JS commands in a MongoDB shell. You can also modify the shell with the configuration file, ~/.mongorc.js. Similar to shell, MongoDB provides language-specific drivers, for example, MongoDB PHP drivers to access MongoDB from PHP.
MongoDB works on the concept of collections and documents. A collection is similar to a table in MySQL and a document is a set of key value stores where a key is similar to a column in a MySQL table. MongoDB does not require any schema definitions and accepts any pair of keys and values in a document. Schemas are dynamically created. In addition, you do not need to explicitly create the collection. Simply type a collection name in a command and it will be created if it does not already exist. In the preceding example, users is a collection we used to store all data. To explicitly create a collection, use the following command:
> use testdb > db.createCollection(‘users’)
You may be missing the where clause in MySQL queries. We have already used that with the findOne() command:
> db.users.findOne({uid:1010})
You can use $lt for less than, $lte for less than or equal to, $gt for greater than, $gte for greater than or equal to, and $ne for not equal:
> db.users.findOne({uid:{$gt:1000}})
In the preceding example, we have used the where clause with the equality condition uid=1010. You can add one more condition as follows:
> db.users.findOne({uid:1010, name:’root’})
To use the or condition, you need to modify the command as follows:
> db.users.find ({$or:[{name:’ubuntu’}, {name:’root’}]})
You can also extract a single key (column) from the entire document. The find command accepts a second optional parameter where you can specify a select criteria. You can use values 1 or 0. Use 1 to extract a specific key and 0 otherwise:
> db.users.findOne({uid:1010}, {name:1})

> db.users.findOne({uid:1010}, {name:0})

There’s more…
You can install a web interface to manage the MongoDB installation. There are various open source web interfaces listed on Mongo documentation at http://docs.mongodb.org/ecosystem/tools/administration-interfaces/.
When you start a mongo shell for the first time, you may see a warning message regarding transperent_hugepage and defrag. To remove those warnings, add the following lines to /etc/init/mongod.conf, below the $DAEMONUSER /var/run/mongodb.pid line:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
Find more details on this Stack Overflow post at http://stackoverflow.com/questions/28911634/how-to-avoid-transparent-hugepage-defrag-warning-from-mongodb
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/
Getting ready
Make sure that you have installed and configured MongoDB. You can also use the MongoDB installation on a remote server.
How to do it…
Follow these steps to store and retrieve data with MongoDB:
- Open a shell to interact with the Mongo server:
$ mongo - To open a shell on a remote server, use the command given. Replace
server_ipandportwith the respective values:$ mongo server_ip:port/db - To create and start using a new database, type
use dbname. Since schemas in MongoDB are dynamic, you do not need to create a database before using it:> use testdb - You can type
helpin Mongo shell to get a list of available commands and help regarding a specific command:> help: Let’s insert our first document:> db.users.insert({‘name’:’ubuntu’,’uid’:1001}) - To view the created database and collection, use the following commands:
> show dbs> show collections - You can also insert multiple values for a key, for example, which groups a user belongs to:
> db.users.insert({‘name’:’root’,’uid’:1010, ‘gid’:[1010, 1000, 1111]}) - Check whether a document is successfully inserted:
> db.users.find() - To get a single record, use
findOne():> db.users.findOne({uid:1010}) - To update an existing record, use the
updatecommand as follows:> db.users.update({name:’ubuntu’}, {$set:{uid:2222}}) - To remove a record, use the
removecommand. This will remove all records with anameequal toubuntu:> db.users.remove({‘name’:’ubuntu’}) - To drop an entire collection, use the
drop()command:> db.users.drop() - To drop a database, use the
dropDatabase()command:> db.users.dropDatabase()
How it works…
The preceding examples show very basic CRUD operations with the MongoDB shell interface. MongoDB shell is also a JavaScript shell. You can execute all JS commands in a MongoDB shell. You can also modify the shell with the configuration file, ~/.mongorc.js. Similar to shell, MongoDB provides language-specific drivers, for example, MongoDB PHP drivers to access MongoDB from PHP.
MongoDB works on the concept of collections and documents. A collection is similar to a table in MySQL and a document is a set of key value stores where a key is similar to a column in a MySQL table. MongoDB does not require any schema definitions and accepts any pair of keys and values in a document. Schemas are dynamically created. In addition, you do not need to explicitly create the collection. Simply type a collection name in a command and it will be created if it does not already exist. In the preceding example, users is a collection we used to store all data. To explicitly create a collection, use the following command:
> use testdb > db.createCollection(‘users’)
You may be missing the where clause in MySQL queries. We have already used that with the findOne() command:
> db.users.findOne({uid:1010})
You can use $lt for less than, $lte for less than or equal to, $gt for greater than, $gte for greater than or equal to, and $ne for not equal:
> db.users.findOne({uid:{$gt:1000}})
In the preceding example, we have used the where clause with the equality condition uid=1010. You can add one more condition as follows:
> db.users.findOne({uid:1010, name:’root’})
To use the or condition, you need to modify the command as follows:
> db.users.find ({$or:[{name:’ubuntu’}, {name:’root’}]})
You can also extract a single key (column) from the entire document. The find command accepts a second optional parameter where you can specify a select criteria. You can use values 1 or 0. Use 1 to extract a specific key and 0 otherwise:
> db.users.findOne({uid:1010}, {name:1})
> db.users.findOne({uid:1010}, {name:0})
There’s more…
You can install a web interface to manage the MongoDB installation. There are various open source web interfaces listed on Mongo documentation at http://docs.mongodb.org/ecosystem/tools/administration-interfaces/.
When you start a mongo shell for the first time, you may see a warning message regarding transperent_hugepage and defrag. To remove those warnings, add the following lines to /etc/init/mongod.conf, below the $DAEMONUSER /var/run/mongodb.pid line:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
Find more details on this Stack Overflow post at http://stackoverflow.com/questions/28911634/how-to-avoid-transparent-hugepage-defrag-warning-from-mongodb
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/
How to do it…
Follow these steps to store and retrieve data with MongoDB:
- Open a shell to interact with the Mongo server:
$ mongo - To open a shell on a remote server, use the command given. Replace
server_ipandportwith the respective values:$ mongo server_ip:port/db - To create and start using a new database, type
use dbname. Since schemas in MongoDB are dynamic, you do not need to create a database before using it:> use testdb - You can type
helpin Mongo shell to get a list of available commands and help regarding a specific command:> help: Let’s insert our first document:> db.users.insert({‘name’:’ubuntu’,’uid’:1001}) - To view the created database and collection, use the following commands:
> show dbs> show collections - You can also insert multiple values for a key, for example, which groups a user belongs to:
> db.users.insert({‘name’:’root’,’uid’:1010, ‘gid’:[1010, 1000, 1111]}) - Check whether a document is successfully inserted:
> db.users.find() - To get a single record, use
findOne():> db.users.findOne({uid:1010}) - To update an existing record, use the
updatecommand as follows:> db.users.update({name:’ubuntu’}, {$set:{uid:2222}}) - To remove a record, use the
removecommand. This will remove all records with anameequal toubuntu:> db.users.remove({‘name’:’ubuntu’}) - To drop an entire collection, use the
drop()command:> db.users.drop() - To drop a database, use the
dropDatabase()command:> db.users.dropDatabase()
How it works…
The preceding examples show very basic CRUD operations with the MongoDB shell interface. MongoDB shell is also a JavaScript shell. You can execute all JS commands in a MongoDB shell. You can also modify the shell with the configuration file, ~/.mongorc.js. Similar to shell, MongoDB provides language-specific drivers, for example, MongoDB PHP drivers to access MongoDB from PHP.
MongoDB works on the concept of collections and documents. A collection is similar to a table in MySQL and a document is a set of key value stores where a key is similar to a column in a MySQL table. MongoDB does not require any schema definitions and accepts any pair of keys and values in a document. Schemas are dynamically created. In addition, you do not need to explicitly create the collection. Simply type a collection name in a command and it will be created if it does not already exist. In the preceding example, users is a collection we used to store all data. To explicitly create a collection, use the following command:
> use testdb > db.createCollection(‘users’)
You may be missing the where clause in MySQL queries. We have already used that with the findOne() command:
> db.users.findOne({uid:1010})
You can use $lt for less than, $lte for less than or equal to, $gt for greater than, $gte for greater than or equal to, and $ne for not equal:
> db.users.findOne({uid:{$gt:1000}})
In the preceding example, we have used the where clause with the equality condition uid=1010. You can add one more condition as follows:
> db.users.findOne({uid:1010, name:’root’})
To use the or condition, you need to modify the command as follows:
> db.users.find ({$or:[{name:’ubuntu’}, {name:’root’}]})
You can also extract a single key (column) from the entire document. The find command accepts a second optional parameter where you can specify a select criteria. You can use values 1 or 0. Use 1 to extract a specific key and 0 otherwise:
> db.users.findOne({uid:1010}, {name:1})
> db.users.findOne({uid:1010}, {name:0})
There’s more…
You can install a web interface to manage the MongoDB installation. There are various open source web interfaces listed on Mongo documentation at http://docs.mongodb.org/ecosystem/tools/administration-interfaces/.
When you start a mongo shell for the first time, you may see a warning message regarding transperent_hugepage and defrag. To remove those warnings, add the following lines to /etc/init/mongod.conf, below the $DAEMONUSER /var/run/mongodb.pid line:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
Find more details on this Stack Overflow post at http://stackoverflow.com/questions/28911634/how-to-avoid-transparent-hugepage-defrag-warning-from-mongodb
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/
How it works…
The preceding examples show very basic CRUD operations with the MongoDB shell interface. MongoDB shell is also a JavaScript shell. You can execute all JS commands in a MongoDB shell. You can also modify the shell with the configuration file, ~/.mongorc.js. Similar to shell, MongoDB provides language-specific drivers, for example, MongoDB PHP drivers to access MongoDB from PHP.
MongoDB works on the concept of collections and documents. A collection is similar to a table in MySQL and a document is a set of key value stores where a key is similar to a column in a MySQL table. MongoDB does not require any schema definitions and accepts any pair of keys and values in a document. Schemas are dynamically created. In addition, you do not need to explicitly create the collection. Simply type a collection name in a command and it will be created if it does not already exist. In the preceding example, users is a collection we used to store all data. To explicitly create a collection, use the following command:
> use testdb > db.createCollection(‘users’)
You may be missing the where clause in MySQL queries. We have already used that with the findOne() command:
> db.users.findOne({uid:1010})
You can use $lt for less than, $lte for less than or equal to, $gt for greater than, $gte for greater than or equal to, and $ne for not equal:
> db.users.findOne({uid:{$gt:1000}})
In the preceding example, we have used the where clause with the equality condition uid=1010. You can add one more condition as follows:
> db.users.findOne({uid:1010, name:’root’})
To use the or condition, you need to modify the command as follows:
> db.users.find ({$or:[{name:’ubuntu’}, {name:’root’}]})
You can also extract a single key (column) from the entire document. The find command accepts a second optional parameter where you can specify a select criteria. You can use values 1 or 0. Use 1 to extract a specific key and 0 otherwise:
> db.users.findOne({uid:1010}, {name:1})
> db.users.findOne({uid:1010}, {name:0})
There’s more…
You can install a web interface to manage the MongoDB installation. There are various open source web interfaces listed on Mongo documentation at http://docs.mongodb.org/ecosystem/tools/administration-interfaces/.
When you start a mongo shell for the first time, you may see a warning message regarding transperent_hugepage and defrag. To remove those warnings, add the following lines to /etc/init/mongod.conf, below the $DAEMONUSER /var/run/mongodb.pid line:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
Find more details on this Stack Overflow post at http://stackoverflow.com/questions/28911634/how-to-avoid-transparent-hugepage-defrag-warning-from-mongodb
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/
There’s more…
You can install a web interface to manage the MongoDB installation. There are various open source web interfaces listed on Mongo documentation at http://docs.mongodb.org/ecosystem/tools/administration-interfaces/.
When you start a mongo shell for the first time, you may see a warning message regarding transperent_hugepage and defrag. To remove those warnings, add the following lines to /etc/init/mongod.conf, below the $DAEMONUSER /var/run/mongodb.pid line:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
Find more details on this Stack Overflow post at http://stackoverflow.com/questions/28911634/how-to-avoid-transparent-hugepage-defrag-warning-from-mongodb
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/
See also
- Mongo CRUD tutorial at https://docs.mongodb.org/manual/applications/crud/
- MongoDB query documents at https://docs.mongodb.org/manual/tutorial/query-documents/










