






















































Chapter 13. Performance Monitoring
In this chapter, we will cover the following recipes:
- Monitoring the CPU
- Monitoring memory and swap
- Monitoring the network
- Monitoring storage
- Setting performance benchmarks
Introduction
When starting a new server, we tend to use stock images of the Ubuntu server and default installation process. The focus is on developing and improving the application code. The base operating system is not given much attention until we hit some performance issues. Once you reach the tip of application level optimizations and have collected all low-hanging fruit, the next obvious target is system monitoring and resource optimization. In this chapter, we will focus on various performance monitoring tools. We will learn to use various tools to track down the bottlenecks and then briefly look at possible solutions.
The chapter is separated in various recipes, and each covers the monitoring of a single system resource, such as the CPU and memory. At the end of the chapter, we will learn how to set up a performance baseline and use it to compare different configurations of system parameters.
Monitoring the CPU
Modern CPUs generally do not become bottlenecks for performance. The processing power is still far ahead of the data transfer speeds of I/O devices and networks. Generally, the CPU spends a big part of processing time waiting for synchronous IO to fetch data from the disk or from a network device. Tracking exact CPU usage is quite a confusing task. Most of the time, you will find higher CPU use, but in reality, the CPU is waiting for data to become available.
In this recipe, we will focus on tracking CPU performance. We will look at some common tools used to get CPU usage details.
Getting ready
You may need sudo privileges to execute some commands.
How to do it…
Let's start with the most commonly used monitoring command that is top command. The top command shows a summarized view of various resource utilization metrics. This includes CPU usage, memory and swap utilization, running processes, and their respective resource consumption, and so on. All metrics are updated at a predefined interval of three seconds.
Follow these steps to monitor the CPU:
- To start top, simply type in
topin your command prompt and press Enter:$ top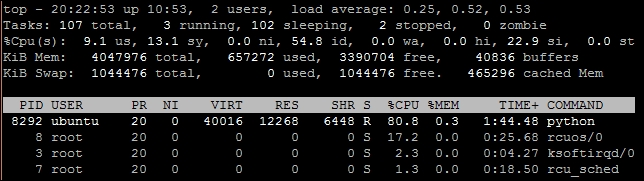
- As you can see in the preceding screenshot, a single Python process is using 80% of CPU time. The CPU is still underutilized, with 58% time in idle processes:
Optionally, you can use the
htopcommand. This is the same process monitor as top, but a little easier to use, and it provides text graphs for CPU and memory utilization. You will need to install htop separately:$ sudo apt-get install htop # one time command $ htop

- While top is used to get an overview of all running processes, the command
pidstatcan be used to monitor CPU utilization by an individual process or program. Use the following command to monitor CPU consumed by MySQL (or any other task name):$ pidstat -C mysql
- With
pidstat, you can also query statistics for a specific process by its process ID or PID, as follows:$ pidstat -p 1134 - The other useful command is
vmstat. This is primarily used to get details on virtual memory usages but also includes some CPU metrics similar to thetopcommand:
- Another command for getting processor statistics is
mpstat. This returns the same statistics astoporvmstatbut is limited to CPU statistics. Mpstat is not a part of the default Ubuntu installation; you need to install thesysstatpackage to use thempstatcommand:$ sudo apt-get install sysstat -y - By default,
mpstatreturns combined averaged stats for all CPUs. Flag-Pcan be used to get details of specific CPUs. The following command will display statistics for processor one (0) and processor two (1), and update at an interval of3seconds:$ mpstat -P 0,1 3
- One more command,
sar(System Activity Reporter), gives details of system performance.The following command will extract the CPU metrics recorded by
sar. Flag-uwill limit details to CPU only and-Pwill display data for all available CPUs separately. By default, thesarcommand will limit the output to CPU details only:$ sar -u -p ALL
- To get current CPU utilization using
sar, specify the interval, and optionally, counter values. The following command will output5records at an interval of2seconds:$ sar -u 2 5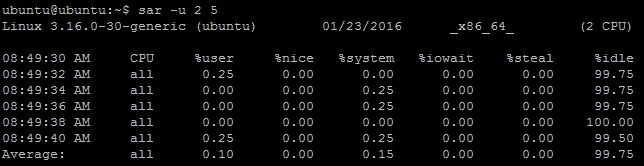
- All this data can be stored in a file specified by the (
-o) flag. The following command will create a file namedsarReportin your current directory, with details of CPU utilization:$ sar -u -o sarReport 3 5
Other options include flag –u, to limit the counter to CPU, and flag A, to get system-wide counters that include network, disk, interrupts, and many more. Check sar manual (man sar) to get specific flags for your desired counters.
How it works…
This recipe covers some well known CPU monitoring tools, starting with the very commonly used command, top, to the background metric logging tool SAR.
In the preceding example, we used top to get a quick summarized view of the current state of the system. By default, top shows the average CPU usage. It is listed in the third row of top output. If you have more than one CPU, their usage is combined and displayed in one single column. You can press 1 when top is running to get details of all available CPUs. This should expand the CPU row to list all CPUs. The following screenshot shows two CPUs available on my virtual machine:
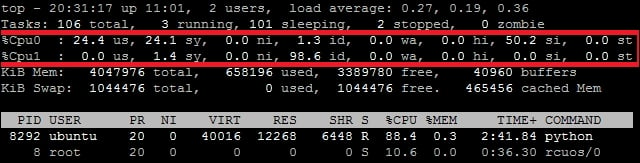
The CPU row shows various different categories of CPU utilization, and the following is a list of their brief descriptions:
us: Time spent in running user space processes. This reflects the CPU consumption by your application.sy: Time taken by system processes. A higher number here can indicate too many processes, and the CPU is spending more time process scheduling.ni: Time spent with user space processes that are assigned with execution priority (nice value).id: Indicates the time spent in idle mode, where the CPU is doing nothing.wa: Waiting for IO. A higher value here means your CPU is spending too much time handling IO operations. Try improving IO performance or reducing IO at application level.hi/si: Time spent in hardware interrupts or software interrupts.st: Stolen CPU cycles. The hypervisor assigned these CPU cycles to another virtual machine. If you see a higher number in this field, try reducing the number of virtual machines from the host. If you are using a cloud service, try to get a new server, or change your service provider.
The second metric shown is the process level CPU utilization. This is listed in a tabular format under the column head, %CPU. This is the percentage of CPU utilization by each process. By default, the top output is automatically sorted in descending order of CPU utilization. Processes that are using higher CPU get listed at top. Another column, named TIME+, displays total CPU time used by each process. Check the processes section on the screen, which should be similar to the following screenshot:
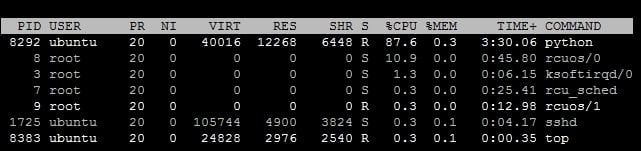
If you have noticed the processes listed by top you should see that top itself is listed in the process list. Top is considered as a separate running process and also consumes CPU cycles.
Note
To get help on the top screen, press H; this will show you various key combinations to modify top output. For additional details, check out the manual pages with the command, man top. When you are done with top, press Q, to exit or use the exit combination, Ctrl + C.
With top, you can get a list of processes or tasks that are consuming most of the CPU time. To get more details of these tasks, you can use the command, pidstat. By default, pidstat shows CPU statistics. It can be used with a process name or process ID (pid). With pidstat
, you can also query memory usages, IO statistics, child processes, and various other process related details. Check the manual page for pidstat using the command man pidstat.
Both commands, top as well as pidstat, give a summarized view of CPU utilization. Top output is refreshed at a specific interval and you cannot extract utilization details over a specific time period. Here comes the other handy command that is vmstat. When run without any parameters, vmstat outputs a single line with memory and CPU utilization, but you can ask vmstat to run infinitely and update the latest metrics at specific intervals using the delay parameter. All the output lines are preserved and can be used to compare the system stats for a given period. The following command will render updated metrics every 5 seconds:
$ vmstat 5
Optionally, specify the count after delay parameter to close vmstat after specific repetitions. The following command will update the stats 5 times at 1 second intervals and then exit:
$ vmstat 1 5
The details provided by vmstat are quite useful for real-time monitoring. The tool sar helps you to store all this data in log files and then extract specific details whenever needed. Sar collects data from various internal counters maintained by the Linux kernel. It collects data over a period of time which can be extracted when required. Using sar without any parameters will show you the data extracted from the previously saved file. The data is collected in a binary format and is located at the /var/log/sysstat directory. You may need to enable data collection in the /etc/default/sysstat file. When the stats collection is enabled, sar automatically collects data every 10 minutes. Sar is again available from the package sysstat. Along with the sar package, sysstat combines two utilities: command sa1 to record daily system activity data in a binary format, and command sa2 to extract that data to a human readable format. All data collected by sar can be extracted in a human readable format using the sa2 command. Check the manual pages for both commands to get more details.
There's more…
Similar to sar, one more well-known tool is collectd. It gathers and stores system statistics, which can later be used to plot graphs.
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
Getting ready
You may need sudo privileges to execute some commands.
How to do it…
Let's start with the most commonly used monitoring command that is top command. The top command shows a summarized view of various resource utilization metrics. This includes CPU usage, memory and swap utilization, running processes, and their respective resource consumption, and so on. All metrics are updated at a predefined interval of three seconds.
Follow these steps to monitor the CPU:
- To start top, simply type in
topin your command prompt and press Enter:$ top - As you can see in the preceding screenshot, a single Python process is using 80% of CPU time. The CPU is still underutilized, with 58% time in idle processes:
Optionally, you can use the
htopcommand. This is the same process monitor as top, but a little easier to use, and it provides text graphs for CPU and memory utilization. You will need to install htop separately:$ sudo apt-get install htop # one time command $ htop
- While top is used to get an overview of all running processes, the command
pidstatcan be used to monitor CPU utilization by an individual process or program. Use the following command to monitor CPU consumed by MySQL (or any other task name):$ pidstat -C mysql - With
pidstat, you can also query statistics for a specific process by its process ID or PID, as follows:$ pidstat -p 1134 - The other useful command is
vmstat. This is primarily used to get details on virtual memory usages but also includes some CPU metrics similar to thetopcommand: - Another command for getting processor statistics is
mpstat. This returns the same statistics astoporvmstatbut is limited to CPU statistics. Mpstat is not a part of the default Ubuntu installation; you need to install thesysstatpackage to use thempstatcommand:$ sudo apt-get install sysstat -y - By default,
mpstatreturns combined averaged stats for all CPUs. Flag-Pcan be used to get details of specific CPUs. The following command will display statistics for processor one (0) and processor two (1), and update at an interval of3seconds:$ mpstat -P 0,1 3 - One more command,
sar(System Activity Reporter), gives details of system performance.The following command will extract the CPU metrics recorded by
sar. Flag-uwill limit details to CPU only and-Pwill display data for all available CPUs separately. By default, thesarcommand will limit the output to CPU details only:$ sar -u -p ALL - To get current CPU utilization using
sar, specify the interval, and optionally, counter values. The following command will output5records at an interval of2seconds:$ sar -u 2 5 - All this data can be stored in a file specified by the (
-o) flag. The following command will create a file namedsarReportin your current directory, with details of CPU utilization:$ sar -u -o sarReport 3 5
Other options include flag –u, to limit the counter to CPU, and flag A, to get system-wide counters that include network, disk, interrupts, and many more. Check sar manual (man sar) to get specific flags for your desired counters.
How it works…
This recipe covers some well known CPU monitoring tools, starting with the very commonly used command, top, to the background metric logging tool SAR.
In the preceding example, we used top to get a quick summarized view of the current state of the system. By default, top shows the average CPU usage. It is listed in the third row of top output. If you have more than one CPU, their usage is combined and displayed in one single column. You can press 1 when top is running to get details of all available CPUs. This should expand the CPU row to list all CPUs. The following screenshot shows two CPUs available on my virtual machine:
The CPU row shows various different categories of CPU utilization, and the following is a list of their brief descriptions:
us: Time spent in running user space processes. This reflects the CPU consumption by your application.sy: Time taken by system processes. A higher number here can indicate too many processes, and the CPU is spending more time process scheduling.ni: Time spent with user space processes that are assigned with execution priority (nice value).id: Indicates the time spent in idle mode, where the CPU is doing nothing.wa: Waiting for IO. A higher value here means your CPU is spending too much time handling IO operations. Try improving IO performance or reducing IO at application level.hi/si: Time spent in hardware interrupts or software interrupts.st: Stolen CPU cycles. The hypervisor assigned these CPU cycles to another virtual machine. If you see a higher number in this field, try reducing the number of virtual machines from the host. If you are using a cloud service, try to get a new server, or change your service provider.
The second metric shown is the process level CPU utilization. This is listed in a tabular format under the column head, %CPU. This is the percentage of CPU utilization by each process. By default, the top output is automatically sorted in descending order of CPU utilization. Processes that are using higher CPU get listed at top. Another column, named TIME+, displays total CPU time used by each process. Check the processes section on the screen, which should be similar to the following screenshot:
If you have noticed the processes listed by top you should see that top itself is listed in the process list. Top is considered as a separate running process and also consumes CPU cycles.
Note
To get help on the top screen, press H; this will show you various key combinations to modify top output. For additional details, check out the manual pages with the command, man top. When you are done with top, press Q, to exit or use the exit combination, Ctrl + C.
With top, you can get a list of processes or tasks that are consuming most of the CPU time. To get more details of these tasks, you can use the command, pidstat. By default, pidstat shows CPU statistics. It can be used with a process name or process ID (pid). With pidstat
, you can also query memory usages, IO statistics, child processes, and various other process related details. Check the manual page for pidstat using the command man pidstat.
Both commands, top as well as pidstat, give a summarized view of CPU utilization. Top output is refreshed at a specific interval and you cannot extract utilization details over a specific time period. Here comes the other handy command that is vmstat. When run without any parameters, vmstat outputs a single line with memory and CPU utilization, but you can ask vmstat to run infinitely and update the latest metrics at specific intervals using the delay parameter. All the output lines are preserved and can be used to compare the system stats for a given period. The following command will render updated metrics every 5 seconds:
$ vmstat 5
Optionally, specify the count after delay parameter to close vmstat after specific repetitions. The following command will update the stats 5 times at 1 second intervals and then exit:
$ vmstat 1 5
The details provided by vmstat are quite useful for real-time monitoring. The tool sar helps you to store all this data in log files and then extract specific details whenever needed. Sar collects data from various internal counters maintained by the Linux kernel. It collects data over a period of time which can be extracted when required. Using sar without any parameters will show you the data extracted from the previously saved file. The data is collected in a binary format and is located at the /var/log/sysstat directory. You may need to enable data collection in the /etc/default/sysstat file. When the stats collection is enabled, sar automatically collects data every 10 minutes. Sar is again available from the package sysstat. Along with the sar package, sysstat combines two utilities: command sa1 to record daily system activity data in a binary format, and command sa2 to extract that data to a human readable format. All data collected by sar can be extracted in a human readable format using the sa2 command. Check the manual pages for both commands to get more details.
There's more…
Similar to sar, one more well-known tool is collectd. It gathers and stores system statistics, which can later be used to plot graphs.
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
How to do it…
Let's start with the most commonly used monitoring command that is top command. The top command shows a summarized view of various resource utilization metrics. This includes CPU usage, memory and swap utilization, running processes, and their respective resource consumption, and so on. All metrics are updated at a predefined interval of three seconds.
Follow these steps to monitor the CPU:
- To start top, simply type in
topin your command prompt and press Enter:$ top - As you can see in the preceding screenshot, a single Python process is using 80% of CPU time. The CPU is still underutilized, with 58% time in idle processes:
Optionally, you can use the
htopcommand. This is the same process monitor as top, but a little easier to use, and it provides text graphs for CPU and memory utilization. You will need to install htop separately:$ sudo apt-get install htop # one time command $ htop
- While top is used to get an overview of all running processes, the command
pidstatcan be used to monitor CPU utilization by an individual process or program. Use the following command to monitor CPU consumed by MySQL (or any other task name):$ pidstat -C mysql - With
pidstat, you can also query statistics for a specific process by its process ID or PID, as follows:$ pidstat -p 1134 - The other useful command is
vmstat. This is primarily used to get details on virtual memory usages but also includes some CPU metrics similar to thetopcommand: - Another command for getting processor statistics is
mpstat. This returns the same statistics astoporvmstatbut is limited to CPU statistics. Mpstat is not a part of the default Ubuntu installation; you need to install thesysstatpackage to use thempstatcommand:$ sudo apt-get install sysstat -y - By default,
mpstatreturns combined averaged stats for all CPUs. Flag-Pcan be used to get details of specific CPUs. The following command will display statistics for processor one (0) and processor two (1), and update at an interval of3seconds:$ mpstat -P 0,1 3 - One more command,
sar(System Activity Reporter), gives details of system performance.The following command will extract the CPU metrics recorded by
sar. Flag-uwill limit details to CPU only and-Pwill display data for all available CPUs separately. By default, thesarcommand will limit the output to CPU details only:$ sar -u -p ALL - To get current CPU utilization using
sar, specify the interval, and optionally, counter values. The following command will output5records at an interval of2seconds:$ sar -u 2 5 - All this data can be stored in a file specified by the (
-o) flag. The following command will create a file namedsarReportin your current directory, with details of CPU utilization:$ sar -u -o sarReport 3 5
Other options include flag –u, to limit the counter to CPU, and flag A, to get system-wide counters that include network, disk, interrupts, and many more. Check sar manual (man sar) to get specific flags for your desired counters.
How it works…
This recipe covers some well known CPU monitoring tools, starting with the very commonly used command, top, to the background metric logging tool SAR.
In the preceding example, we used top to get a quick summarized view of the current state of the system. By default, top shows the average CPU usage. It is listed in the third row of top output. If you have more than one CPU, their usage is combined and displayed in one single column. You can press 1 when top is running to get details of all available CPUs. This should expand the CPU row to list all CPUs. The following screenshot shows two CPUs available on my virtual machine:
The CPU row shows various different categories of CPU utilization, and the following is a list of their brief descriptions:
us: Time spent in running user space processes. This reflects the CPU consumption by your application.sy: Time taken by system processes. A higher number here can indicate too many processes, and the CPU is spending more time process scheduling.ni: Time spent with user space processes that are assigned with execution priority (nice value).id: Indicates the time spent in idle mode, where the CPU is doing nothing.wa: Waiting for IO. A higher value here means your CPU is spending too much time handling IO operations. Try improving IO performance or reducing IO at application level.hi/si: Time spent in hardware interrupts or software interrupts.st: Stolen CPU cycles. The hypervisor assigned these CPU cycles to another virtual machine. If you see a higher number in this field, try reducing the number of virtual machines from the host. If you are using a cloud service, try to get a new server, or change your service provider.
The second metric shown is the process level CPU utilization. This is listed in a tabular format under the column head, %CPU. This is the percentage of CPU utilization by each process. By default, the top output is automatically sorted in descending order of CPU utilization. Processes that are using higher CPU get listed at top. Another column, named TIME+, displays total CPU time used by each process. Check the processes section on the screen, which should be similar to the following screenshot:
If you have noticed the processes listed by top you should see that top itself is listed in the process list. Top is considered as a separate running process and also consumes CPU cycles.
Note
To get help on the top screen, press H; this will show you various key combinations to modify top output. For additional details, check out the manual pages with the command, man top. When you are done with top, press Q, to exit or use the exit combination, Ctrl + C.
With top, you can get a list of processes or tasks that are consuming most of the CPU time. To get more details of these tasks, you can use the command, pidstat. By default, pidstat shows CPU statistics. It can be used with a process name or process ID (pid). With pidstat
, you can also query memory usages, IO statistics, child processes, and various other process related details. Check the manual page for pidstat using the command man pidstat.
Both commands, top as well as pidstat, give a summarized view of CPU utilization. Top output is refreshed at a specific interval and you cannot extract utilization details over a specific time period. Here comes the other handy command that is vmstat. When run without any parameters, vmstat outputs a single line with memory and CPU utilization, but you can ask vmstat to run infinitely and update the latest metrics at specific intervals using the delay parameter. All the output lines are preserved and can be used to compare the system stats for a given period. The following command will render updated metrics every 5 seconds:
$ vmstat 5
Optionally, specify the count after delay parameter to close vmstat after specific repetitions. The following command will update the stats 5 times at 1 second intervals and then exit:
$ vmstat 1 5
The details provided by vmstat are quite useful for real-time monitoring. The tool sar helps you to store all this data in log files and then extract specific details whenever needed. Sar collects data from various internal counters maintained by the Linux kernel. It collects data over a period of time which can be extracted when required. Using sar without any parameters will show you the data extracted from the previously saved file. The data is collected in a binary format and is located at the /var/log/sysstat directory. You may need to enable data collection in the /etc/default/sysstat file. When the stats collection is enabled, sar automatically collects data every 10 minutes. Sar is again available from the package sysstat. Along with the sar package, sysstat combines two utilities: command sa1 to record daily system activity data in a binary format, and command sa2 to extract that data to a human readable format. All data collected by sar can be extracted in a human readable format using the sa2 command. Check the manual pages for both commands to get more details.
There's more…
Similar to sar, one more well-known tool is collectd. It gathers and stores system statistics, which can later be used to plot graphs.
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
How it works…
This recipe covers some well known CPU monitoring tools, starting with the very commonly used command, top, to the background metric logging tool SAR.
In the preceding example, we used top to get a quick summarized view of the current state of the system. By default, top shows the average CPU usage. It is listed in the third row of top output. If you have more than one CPU, their usage is combined and displayed in one single column. You can press 1 when top is running to get details of all available CPUs. This should expand the CPU row to list all CPUs. The following screenshot shows two CPUs available on my virtual machine:
The CPU row shows various different categories of CPU utilization, and the following is a list of their brief descriptions:
us: Time spent in running user space processes. This reflects the CPU consumption by your application.sy: Time taken by system processes. A higher number here can indicate too many processes, and the CPU is spending more time process scheduling.ni: Time spent with user space processes that are assigned with execution priority (nice value).id: Indicates the time spent in idle mode, where the CPU is doing nothing.wa: Waiting for IO. A higher value here means your CPU is spending too much time handling IO operations. Try improving IO performance or reducing IO at application level.hi/si: Time spent in hardware interrupts or software interrupts.st: Stolen CPU cycles. The hypervisor assigned these CPU cycles to another virtual machine. If you see a higher number in this field, try reducing the number of virtual machines from the host. If you are using a cloud service, try to get a new server, or change your service provider.
The second metric shown is the process level CPU utilization. This is listed in a tabular format under the column head, %CPU. This is the percentage of CPU utilization by each process. By default, the top output is automatically sorted in descending order of CPU utilization. Processes that are using higher CPU get listed at top. Another column, named TIME+, displays total CPU time used by each process. Check the processes section on the screen, which should be similar to the following screenshot:
If you have noticed the processes listed by top you should see that top itself is listed in the process list. Top is considered as a separate running process and also consumes CPU cycles.
Note
To get help on the top screen, press H; this will show you various key combinations to modify top output. For additional details, check out the manual pages with the command, man top. When you are done with top, press Q, to exit or use the exit combination, Ctrl + C.
With top, you can get a list of processes or tasks that are consuming most of the CPU time. To get more details of these tasks, you can use the command, pidstat. By default, pidstat shows CPU statistics. It can be used with a process name or process ID (pid). With pidstat
, you can also query memory usages, IO statistics, child processes, and various other process related details. Check the manual page for pidstat using the command man pidstat.
Both commands, top as well as pidstat, give a summarized view of CPU utilization. Top output is refreshed at a specific interval and you cannot extract utilization details over a specific time period. Here comes the other handy command that is vmstat. When run without any parameters, vmstat outputs a single line with memory and CPU utilization, but you can ask vmstat to run infinitely and update the latest metrics at specific intervals using the delay parameter. All the output lines are preserved and can be used to compare the system stats for a given period. The following command will render updated metrics every 5 seconds:
$ vmstat 5
Optionally, specify the count after delay parameter to close vmstat after specific repetitions. The following command will update the stats 5 times at 1 second intervals and then exit:
$ vmstat 1 5
The details provided by vmstat are quite useful for real-time monitoring. The tool sar helps you to store all this data in log files and then extract specific details whenever needed. Sar collects data from various internal counters maintained by the Linux kernel. It collects data over a period of time which can be extracted when required. Using sar without any parameters will show you the data extracted from the previously saved file. The data is collected in a binary format and is located at the /var/log/sysstat directory. You may need to enable data collection in the /etc/default/sysstat file. When the stats collection is enabled, sar automatically collects data every 10 minutes. Sar is again available from the package sysstat. Along with the sar package, sysstat combines two utilities: command sa1 to record daily system activity data in a binary format, and command sa2 to extract that data to a human readable format. All data collected by sar can be extracted in a human readable format using the sa2 command. Check the manual pages for both commands to get more details.
There's more…
Similar to sar, one more well-known tool is collectd. It gathers and stores system statistics, which can later be used to plot graphs.
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
There's more…
Similar to sar, one more well-known tool is collectd. It gathers and stores system statistics, which can later be used to plot graphs.
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
See also
- Get information on your system CPU with the following command:
$ less /proc/cpuinfo - Details on
/procfile system: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
Monitoring memory and swap
Memory is another important component of system performance. All files and data that are currently being used are kept in the system main memory for faster access. The CPU performance also depends on the availability of enough memory. Swap, on the other hand, is an extension to main memory. Swap is part of persistent storage, such as hard drives or solid state drives. It is utilized only when the system is low on main memory.
In this chapter, we will learn how to monitor system memory and swap utilization.
Getting ready
You may need sudo privileges for some commands.
How to do it…
In the last recipe, we used commands top and vmstat to monitor CPU utilization. These commands also provided details of memory usage. Let's start with the top command again:
- Run the
topcommand and check for theMemandSwaprows:
- The memory line displays the size of total available memory, size of used memory, free memory, and the memory used for buffers and the file system cache. Similarly, swap row should display the allocated size of the swap if you have enabled the swapping. Along with these two lines,
topshows per process memory utilization as well. The columnsVIRT,RES,SHR, and%MEMall show different memory allocation for each process:
- Similar to the
topcommand, you can query memory statistics for a specific PID or program by using thepidstatcommand. By default,pidstatdisplays only CPU statistics for a given process. Use flag-rto query memory utilization and page faults:$ pidstat -C mysql -r - Next, we will go through the
vmstatcommand. This is an abbreviation of virtual memory statistics. Enter the commandvmstatin your console and you should see output similar to the following screenshot:
Using
vmstatwithout any option returns a single line report ofmemory,swap,io, and CPU utilization. Under thememorycolumn, it shows the amount of swap, free memory, and the memory used for cache and buffers. It also display a separateswapcolumn with Swap In (si) and Swap Out (so) details. - To get detailed statistics of memory and event counters, use flag
-s. This should display a table, as follows:$ vmstat -s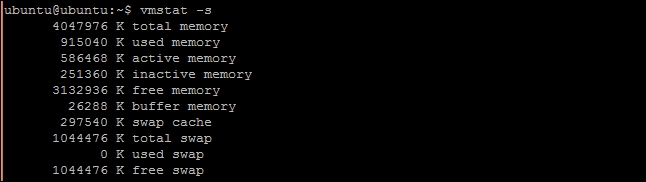
- Another handy command is
free, which displays the amount of used and available memory in the system. Use it as follows, with the-hflag to get human-friendly units:$ free -h
- Finally, command
sarcan give you periodic reports of memory utilization. Simply enablesarto collect all reports and then extract memory reports from it or set a specific command to log only memory and swap details. - Finally, use
sarto monitor current memory and swap utilizations. The following command will query the current memory (-r) and swap (-S) utilization:$ sar -rS 1 5
- For more details on using
sar, check Monitoring the CPU recipe or read the manual pages using theman sarcommand. The commandsaris available in the packagesysstat; you will need to install it separately if not already installed. - All these tools show process-level memory statistics. If you are interested in memory allocation inside a particular process, then the command
pmapcan help you. It reports the memory mapping of a process, including details of any shared libraries in use and any program extensions with their respective memory consumptions. Usepmapalong with the PID you want to monitor as follows:$ sudo pmap -x 1322Note
All information displayed by
pmapis read from a file namedmapslocated in the/proc/ filesystem. You can directly read the file as follows:$ sudo cat /proc/1322/maps
How it works…
System memory is the primary storage for processes in execution. It is the fastest available storage medium, but is volatile and limited in storage space. The limited storage is generally extended with the help of slower, disk-based Swap files. Processes that are not being actively executed are swapped to disk so that active processes get more space in the faster main memory. Similar to other operating systems, Ubuntu provides various tools to monitor system-wide memory utilization as well as memory uses by process. Commonly used tools include top, vmstat, and free.
We have used the top command to monitor CPU uses and know that top provides a summarized view of system resource utilization. Along with a CPU summary, top also provides the memory statistics. This includes overall memory utilization plus per process usage. The summary section in the top output displays the total available and used memory. It also contains a separate row for swap. By default, all Ubuntu systems enable the swap partition with nearly the same size as main memory. Some cloud service providers disable the cache for performance reasons.
The details section of top shows per process memory usage separated into multiple columns:
- Column
VIRTshows the virtual memory assigned to a task or process; this includes memory assigned for program code, data, and shared libraries, plus memory that is assigned but not used. - Column
RESshows the non-swapped physical memory used by processes. Whereas columnSHRshows the amount of shared memory, this is the memory that can be shared with other processes through shared libraries. - The column
%MEMshows the percentage of main memory assigned to a specific process. This is a percentage ofRESmemory available to task out of total available memory. - By default, all memory values are shown in the lowest units, KB. This can be changed using the key combination, Shift + E for summary rows and E for process columns.
Similar to top, the command ps lists running processes but without refreshing the list. Without any options, ps shows the list of processes owned by the current user. Use it as follows to get a list of all running processes:
$ ps aux
Tip
Sometimes it is useful to monitor a specific process over a period of time. Top shows you a list of all running processes and ps gives you a one-time list. The following command will help you monitor a single program within top:
$ top -p $(pgrep process-name | head -20 | tr "\\n" "," | sed 's/,$//')
The command vmstat gives you overall detail regarding memory and swap utilization. The memory column shows the amount of available memory. Next to the memory column, the swap column indicates the amount of memory read from disk (si) or written to disk (so) per second. Any activity in the si and so columns indicates active swap utilization. In that case, you should either increase the physical memory of the system or reduce the number of processes running. Large numbers under the swap column may also indicate higher CPU utilization, where the CPU waits for IO operations (wa) to complete. As seen before, you can specify the delay and interval options to repeatedly query vmstat reports.
One more command, named free, shows the current state of system memory. This shows overall memory utilization in the first row and swap utilization in the second row. You may get confused by looking at the lower values in the free column and assume higher memory uses. Part of free memory is being used by Linux to improve file system performance by caching frequently used files. The memory used for file caching is reflected in the buff/cache column and is available to other programs when required. Check the last column, named available, for the actual free memory.
Note
If you are on Ubuntu 14.04 or lower, the output of the free command will contain three rows, with overall memory utilization in the first row, actual memory utilization with cache and buffer adjustments in the second, and swap listed in the third row.
The second row of free output displays the swap utilization. You may see swap being used under the used column. This is the amount of swap allocated but not effectively used. To check if your system is effectively swapping, use the command vmstat 1 and monitor si/so columns for any swap activity.
System swapping behavior also depends on the value of the kernel parameter named vm.swappiness. Its value can range between 0 to 100, where 0 configures the kernel to avoid swapping as much as possible and 100 sets it to swap aggressively. You can read the current swappiness value using the following command:
$ sudo sysctl vm.swappiness vm.swappiness = 60
To modify the swappiness value for the current session, use the sysctl command with a new value, as follows. It is a good idea to use lower values and avoid swapping as much as possible:
$ sudo sysctl vm.swappiness=10 vm.swappiness = 10
To permanently set swappiness, you need to edit the /etc/sysctl.conf file and add or uncomment vm.swappiness=10 to it. Once the file is updated, use the following command to read and set a new value from the configuration file:
$ sudo sysctl -p
Check the swapon and swapoff commands if you need to enable swapping or disable it.
There's more…
Most of these statistics are read from the /proc partition. The two main files listing details of memory and swap are /proc/meminfo and /proc/swaps.
The command lshw (list hardware) can give you the details of actual hardware. This includes the physical memory configuration, the firmware version, CPU details, such as clock speed, the cache, and various other hardware information. Use lshw as follows:
$ sudo lshw
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
Getting ready
You may need sudo privileges for some commands.
How to do it…
In the last recipe, we used commands top and vmstat to monitor CPU utilization. These commands also provided details of memory usage. Let's start with the top command again:
- Run the
topcommand and check for theMemandSwaprows: - The memory line displays the size of total available memory, size of used memory, free memory, and the memory used for buffers and the file system cache. Similarly, swap row should display the allocated size of the swap if you have enabled the swapping. Along with these two lines,
topshows per process memory utilization as well. The columnsVIRT,RES,SHR, and%MEMall show different memory allocation for each process: - Similar to the
topcommand, you can query memory statistics for a specific PID or program by using thepidstatcommand. By default,pidstatdisplays only CPU statistics for a given process. Use flag-rto query memory utilization and page faults:$ pidstat -C mysql -r - Next, we will go through the
vmstatcommand. This is an abbreviation of virtual memory statistics. Enter the commandvmstatin your console and you should see output similar to the following screenshot:Using
vmstatwithout any option returns a single line report ofmemory,swap,io, and CPU utilization. Under thememorycolumn, it shows the amount of swap, free memory, and the memory used for cache and buffers. It also display a separateswapcolumn with Swap In (si) and Swap Out (so) details. - To get detailed statistics of memory and event counters, use flag
-s. This should display a table, as follows:$ vmstat -s - Another handy command is
free, which displays the amount of used and available memory in the system. Use it as follows, with the-hflag to get human-friendly units:$ free -h - Finally, command
sarcan give you periodic reports of memory utilization. Simply enablesarto collect all reports and then extract memory reports from it or set a specific command to log only memory and swap details. - Finally, use
sarto monitor current memory and swap utilizations. The following command will query the current memory (-r) and swap (-S) utilization:$ sar -rS 1 5 - For more details on using
sar, check Monitoring the CPU recipe or read the manual pages using theman sarcommand. The commandsaris available in the packagesysstat; you will need to install it separately if not already installed. - All these tools show process-level memory statistics. If you are interested in memory allocation inside a particular process, then the command
pmapcan help you. It reports the memory mapping of a process, including details of any shared libraries in use and any program extensions with their respective memory consumptions. Usepmapalong with the PID you want to monitor as follows:$ sudo pmap -x 1322Note
All information displayed by
pmapis read from a file namedmapslocated in the/proc/ filesystem. You can directly read the file as follows:$ sudo cat /proc/1322/maps
How it works…
System memory is the primary storage for processes in execution. It is the fastest available storage medium, but is volatile and limited in storage space. The limited storage is generally extended with the help of slower, disk-based Swap files. Processes that are not being actively executed are swapped to disk so that active processes get more space in the faster main memory. Similar to other operating systems, Ubuntu provides various tools to monitor system-wide memory utilization as well as memory uses by process. Commonly used tools include top, vmstat, and free.
We have used the top command to monitor CPU uses and know that top provides a summarized view of system resource utilization. Along with a CPU summary, top also provides the memory statistics. This includes overall memory utilization plus per process usage. The summary section in the top output displays the total available and used memory. It also contains a separate row for swap. By default, all Ubuntu systems enable the swap partition with nearly the same size as main memory. Some cloud service providers disable the cache for performance reasons.
The details section of top shows per process memory usage separated into multiple columns:
- Column
VIRTshows the virtual memory assigned to a task or process; this includes memory assigned for program code, data, and shared libraries, plus memory that is assigned but not used. - Column
RESshows the non-swapped physical memory used by processes. Whereas columnSHRshows the amount of shared memory, this is the memory that can be shared with other processes through shared libraries. - The column
%MEMshows the percentage of main memory assigned to a specific process. This is a percentage ofRESmemory available to task out of total available memory. - By default, all memory values are shown in the lowest units, KB. This can be changed using the key combination, Shift + E for summary rows and E for process columns.
Similar to top, the command ps lists running processes but without refreshing the list. Without any options, ps shows the list of processes owned by the current user. Use it as follows to get a list of all running processes:
$ ps aux
Tip
Sometimes it is useful to monitor a specific process over a period of time. Top shows you a list of all running processes and ps gives you a one-time list. The following command will help you monitor a single program within top:
$ top -p $(pgrep process-name | head -20 | tr "\\n" "," | sed 's/,$//')
The command vmstat gives you overall detail regarding memory and swap utilization. The memory column shows the amount of available memory. Next to the memory column, the swap column indicates the amount of memory read from disk (si) or written to disk (so) per second. Any activity in the si and so columns indicates active swap utilization. In that case, you should either increase the physical memory of the system or reduce the number of processes running. Large numbers under the swap column may also indicate higher CPU utilization, where the CPU waits for IO operations (wa) to complete. As seen before, you can specify the delay and interval options to repeatedly query vmstat reports.
One more command, named free, shows the current state of system memory. This shows overall memory utilization in the first row and swap utilization in the second row. You may get confused by looking at the lower values in the free column and assume higher memory uses. Part of free memory is being used by Linux to improve file system performance by caching frequently used files. The memory used for file caching is reflected in the buff/cache column and is available to other programs when required. Check the last column, named available, for the actual free memory.
Note
If you are on Ubuntu 14.04 or lower, the output of the free command will contain three rows, with overall memory utilization in the first row, actual memory utilization with cache and buffer adjustments in the second, and swap listed in the third row.
The second row of free output displays the swap utilization. You may see swap being used under the used column. This is the amount of swap allocated but not effectively used. To check if your system is effectively swapping, use the command vmstat 1 and monitor si/so columns for any swap activity.
System swapping behavior also depends on the value of the kernel parameter named vm.swappiness. Its value can range between 0 to 100, where 0 configures the kernel to avoid swapping as much as possible and 100 sets it to swap aggressively. You can read the current swappiness value using the following command:
$ sudo sysctl vm.swappiness vm.swappiness = 60
To modify the swappiness value for the current session, use the sysctl command with a new value, as follows. It is a good idea to use lower values and avoid swapping as much as possible:
$ sudo sysctl vm.swappiness=10 vm.swappiness = 10
To permanently set swappiness, you need to edit the /etc/sysctl.conf file and add or uncomment vm.swappiness=10 to it. Once the file is updated, use the following command to read and set a new value from the configuration file:
$ sudo sysctl -p
Check the swapon and swapoff commands if you need to enable swapping or disable it.
There's more…
Most of these statistics are read from the /proc partition. The two main files listing details of memory and swap are /proc/meminfo and /proc/swaps.
The command lshw (list hardware) can give you the details of actual hardware. This includes the physical memory configuration, the firmware version, CPU details, such as clock speed, the cache, and various other hardware information. Use lshw as follows:
$ sudo lshw
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
How to do it…
In the last recipe, we used commands top and vmstat to monitor CPU utilization. These commands also provided details of memory usage. Let's start with the top command again:
- Run the
topcommand and check for theMemandSwaprows: - The memory line displays the size of total available memory, size of used memory, free memory, and the memory used for buffers and the file system cache. Similarly, swap row should display the allocated size of the swap if you have enabled the swapping. Along with these two lines,
topshows per process memory utilization as well. The columnsVIRT,RES,SHR, and%MEMall show different memory allocation for each process: - Similar to the
topcommand, you can query memory statistics for a specific PID or program by using thepidstatcommand. By default,pidstatdisplays only CPU statistics for a given process. Use flag-rto query memory utilization and page faults:$ pidstat -C mysql -r - Next, we will go through the
vmstatcommand. This is an abbreviation of virtual memory statistics. Enter the commandvmstatin your console and you should see output similar to the following screenshot:Using
vmstatwithout any option returns a single line report ofmemory,swap,io, and CPU utilization. Under thememorycolumn, it shows the amount of swap, free memory, and the memory used for cache and buffers. It also display a separateswapcolumn with Swap In (si) and Swap Out (so) details. - To get detailed statistics of memory and event counters, use flag
-s. This should display a table, as follows:$ vmstat -s - Another handy command is
free, which displays the amount of used and available memory in the system. Use it as follows, with the-hflag to get human-friendly units:$ free -h - Finally, command
sarcan give you periodic reports of memory utilization. Simply enablesarto collect all reports and then extract memory reports from it or set a specific command to log only memory and swap details. - Finally, use
sarto monitor current memory and swap utilizations. The following command will query the current memory (-r) and swap (-S) utilization:$ sar -rS 1 5 - For more details on using
sar, check Monitoring the CPU recipe or read the manual pages using theman sarcommand. The commandsaris available in the packagesysstat; you will need to install it separately if not already installed. - All these tools show process-level memory statistics. If you are interested in memory allocation inside a particular process, then the command
pmapcan help you. It reports the memory mapping of a process, including details of any shared libraries in use and any program extensions with their respective memory consumptions. Usepmapalong with the PID you want to monitor as follows:$ sudo pmap -x 1322Note
All information displayed by
pmapis read from a file namedmapslocated in the/proc/ filesystem. You can directly read the file as follows:$ sudo cat /proc/1322/maps
How it works…
System memory is the primary storage for processes in execution. It is the fastest available storage medium, but is volatile and limited in storage space. The limited storage is generally extended with the help of slower, disk-based Swap files. Processes that are not being actively executed are swapped to disk so that active processes get more space in the faster main memory. Similar to other operating systems, Ubuntu provides various tools to monitor system-wide memory utilization as well as memory uses by process. Commonly used tools include top, vmstat, and free.
We have used the top command to monitor CPU uses and know that top provides a summarized view of system resource utilization. Along with a CPU summary, top also provides the memory statistics. This includes overall memory utilization plus per process usage. The summary section in the top output displays the total available and used memory. It also contains a separate row for swap. By default, all Ubuntu systems enable the swap partition with nearly the same size as main memory. Some cloud service providers disable the cache for performance reasons.
The details section of top shows per process memory usage separated into multiple columns:
- Column
VIRTshows the virtual memory assigned to a task or process; this includes memory assigned for program code, data, and shared libraries, plus memory that is assigned but not used. - Column
RESshows the non-swapped physical memory used by processes. Whereas columnSHRshows the amount of shared memory, this is the memory that can be shared with other processes through shared libraries. - The column
%MEMshows the percentage of main memory assigned to a specific process. This is a percentage ofRESmemory available to task out of total available memory. - By default, all memory values are shown in the lowest units, KB. This can be changed using the key combination, Shift + E for summary rows and E for process columns.
Similar to top, the command ps lists running processes but without refreshing the list. Without any options, ps shows the list of processes owned by the current user. Use it as follows to get a list of all running processes:
$ ps aux
Tip
Sometimes it is useful to monitor a specific process over a period of time. Top shows you a list of all running processes and ps gives you a one-time list. The following command will help you monitor a single program within top:
$ top -p $(pgrep process-name | head -20 | tr "\\n" "," | sed 's/,$//')
The command vmstat gives you overall detail regarding memory and swap utilization. The memory column shows the amount of available memory. Next to the memory column, the swap column indicates the amount of memory read from disk (si) or written to disk (so) per second. Any activity in the si and so columns indicates active swap utilization. In that case, you should either increase the physical memory of the system or reduce the number of processes running. Large numbers under the swap column may also indicate higher CPU utilization, where the CPU waits for IO operations (wa) to complete. As seen before, you can specify the delay and interval options to repeatedly query vmstat reports.
One more command, named free, shows the current state of system memory. This shows overall memory utilization in the first row and swap utilization in the second row. You may get confused by looking at the lower values in the free column and assume higher memory uses. Part of free memory is being used by Linux to improve file system performance by caching frequently used files. The memory used for file caching is reflected in the buff/cache column and is available to other programs when required. Check the last column, named available, for the actual free memory.
Note
If you are on Ubuntu 14.04 or lower, the output of the free command will contain three rows, with overall memory utilization in the first row, actual memory utilization with cache and buffer adjustments in the second, and swap listed in the third row.
The second row of free output displays the swap utilization. You may see swap being used under the used column. This is the amount of swap allocated but not effectively used. To check if your system is effectively swapping, use the command vmstat 1 and monitor si/so columns for any swap activity.
System swapping behavior also depends on the value of the kernel parameter named vm.swappiness. Its value can range between 0 to 100, where 0 configures the kernel to avoid swapping as much as possible and 100 sets it to swap aggressively. You can read the current swappiness value using the following command:
$ sudo sysctl vm.swappiness vm.swappiness = 60
To modify the swappiness value for the current session, use the sysctl command with a new value, as follows. It is a good idea to use lower values and avoid swapping as much as possible:
$ sudo sysctl vm.swappiness=10 vm.swappiness = 10
To permanently set swappiness, you need to edit the /etc/sysctl.conf file and add or uncomment vm.swappiness=10 to it. Once the file is updated, use the following command to read and set a new value from the configuration file:
$ sudo sysctl -p
Check the swapon and swapoff commands if you need to enable swapping or disable it.
There's more…
Most of these statistics are read from the /proc partition. The two main files listing details of memory and swap are /proc/meminfo and /proc/swaps.
The command lshw (list hardware) can give you the details of actual hardware. This includes the physical memory configuration, the firmware version, CPU details, such as clock speed, the cache, and various other hardware information. Use lshw as follows:
$ sudo lshw
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
How it works…
System memory is the primary storage for processes in execution. It is the fastest available storage medium, but is volatile and limited in storage space. The limited storage is generally extended with the help of slower, disk-based Swap files. Processes that are not being actively executed are swapped to disk so that active processes get more space in the faster main memory. Similar to other operating systems, Ubuntu provides various tools to monitor system-wide memory utilization as well as memory uses by process. Commonly used tools include top, vmstat, and free.
We have used the top command to monitor CPU uses and know that top provides a summarized view of system resource utilization. Along with a CPU summary, top also provides the memory statistics. This includes overall memory utilization plus per process usage. The summary section in the top output displays the total available and used memory. It also contains a separate row for swap. By default, all Ubuntu systems enable the swap partition with nearly the same size as main memory. Some cloud service providers disable the cache for performance reasons.
The details section of top shows per process memory usage separated into multiple columns:
- Column
VIRTshows the virtual memory assigned to a task or process; this includes memory assigned for program code, data, and shared libraries, plus memory that is assigned but not used. - Column
RESshows the non-swapped physical memory used by processes. Whereas columnSHRshows the amount of shared memory, this is the memory that can be shared with other processes through shared libraries. - The column
%MEMshows the percentage of main memory assigned to a specific process. This is a percentage ofRESmemory available to task out of total available memory. - By default, all memory values are shown in the lowest units, KB. This can be changed using the key combination, Shift + E for summary rows and E for process columns.
Similar to top, the command ps lists running processes but without refreshing the list. Without any options, ps shows the list of processes owned by the current user. Use it as follows to get a list of all running processes:
$ ps aux
Tip
Sometimes it is useful to monitor a specific process over a period of time. Top shows you a list of all running processes and ps gives you a one-time list. The following command will help you monitor a single program within top:
$ top -p $(pgrep process-name | head -20 | tr "\\n" "," | sed 's/,$//')
The command vmstat gives you overall detail regarding memory and swap utilization. The memory column shows the amount of available memory. Next to the memory column, the swap column indicates the amount of memory read from disk (si) or written to disk (so) per second. Any activity in the si and so columns indicates active swap utilization. In that case, you should either increase the physical memory of the system or reduce the number of processes running. Large numbers under the swap column may also indicate higher CPU utilization, where the CPU waits for IO operations (wa) to complete. As seen before, you can specify the delay and interval options to repeatedly query vmstat reports.
One more command, named free, shows the current state of system memory. This shows overall memory utilization in the first row and swap utilization in the second row. You may get confused by looking at the lower values in the free column and assume higher memory uses. Part of free memory is being used by Linux to improve file system performance by caching frequently used files. The memory used for file caching is reflected in the buff/cache column and is available to other programs when required. Check the last column, named available, for the actual free memory.
Note
If you are on Ubuntu 14.04 or lower, the output of the free command will contain three rows, with overall memory utilization in the first row, actual memory utilization with cache and buffer adjustments in the second, and swap listed in the third row.
The second row of free output displays the swap utilization. You may see swap being used under the used column. This is the amount of swap allocated but not effectively used. To check if your system is effectively swapping, use the command vmstat 1 and monitor si/so columns for any swap activity.
System swapping behavior also depends on the value of the kernel parameter named vm.swappiness. Its value can range between 0 to 100, where 0 configures the kernel to avoid swapping as much as possible and 100 sets it to swap aggressively. You can read the current swappiness value using the following command:
$ sudo sysctl vm.swappiness vm.swappiness = 60
To modify the swappiness value for the current session, use the sysctl command with a new value, as follows. It is a good idea to use lower values and avoid swapping as much as possible:
$ sudo sysctl vm.swappiness=10 vm.swappiness = 10
To permanently set swappiness, you need to edit the /etc/sysctl.conf file and add or uncomment vm.swappiness=10 to it. Once the file is updated, use the following command to read and set a new value from the configuration file:
$ sudo sysctl -p
Check the swapon and swapoff commands if you need to enable swapping or disable it.
There's more…
Most of these statistics are read from the /proc partition. The two main files listing details of memory and swap are /proc/meminfo and /proc/swaps.
The command lshw (list hardware) can give you the details of actual hardware. This includes the physical memory configuration, the firmware version, CPU details, such as clock speed, the cache, and various other hardware information. Use lshw as follows:
$ sudo lshw
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
There's more…
Most of these statistics are read from the /proc partition. The two main files listing details of memory and swap are /proc/meminfo and /proc/swaps.
The command lshw (list hardware) can give you the details of actual hardware. This includes the physical memory configuration, the firmware version, CPU details, such as clock speed, the cache, and various other hardware information. Use lshw as follows:
$ sudo lshw
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
See also
- Check the
swaponandswapoffcommands to enable or disable swap files:$ man swapon $ man swapoff
Monitoring the network
When we are talking about a server, its network is the most important resource. Especially in the cloud network, when it is the only communication channel to access the server and connect with other servers in the network. The network comes under an Input/Output device category. Networks are generally slow in performance and are an unreliable communication channel. You may lose some data while in transit, data may be exposed to external entities, or a malicious guy can update original data before it reaches you.
The Ubuntu server, as well as Linux in general, provides tons of utilities to ease network monitoring and administration. This recipe covers some inbuilt tools to monitor network traffic and its performance. We will also look at a few additional tools that are worth a space on your system.
Getting ready
Some commands may need sudo access.
You may need to install a few tools.
How to do it…
- We will start with a commonly used command, that is,
ifconfig. We mostly use this command to read the network configuration details such as the IP address. When called without any parameters,ifconfigdisplays details of all active network interfaces as follows:
- These details contain the IP address assigned to each network interface, its hardware address, the maximum packet size (
MTU) and basic statistics of received (RX) and transmitted (TX) packets, and the count of errors or dropped packets, and so on. - If you are only interested in quick network statistics, use
ifconfigwith flag-s, as follows:
- If you do not see a specific network interface listed in the active list, then query for all available interfaces with the
-aoption toifconfig. - Another commonly used command is
ping. It sends ICMP requests to a specified host and waits for the reply. If you query for a host name,pingwill get its IP address from DNS. This also gives you confirmation that the DNS is working properly. Ping also gives you the latency of your network interface. Check for thetimevalues in the output of thepingcommand:
- Next, comes
netstat. It is mainly used to check network connections and routing tables on the system. The commonly used syntax is as follows:$ sudo netstat -plutn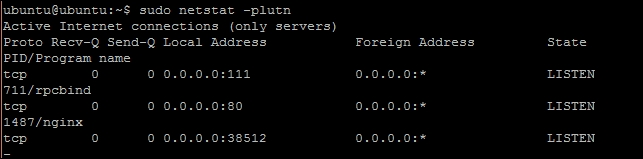
- The preceding command should list all TCP (
-t) / UDP (-u) connections, plus any ports that are actively listening (-l) for connection. The flag,-p, queries the program name responsible for a specified connection. Note that flag-prequires sudo privileges. Also check flag-ato get all listening as well as non-listening sockets, or query the routing table information with flag-ras follows:$ netstat -r
- You can also get protocol level network statistics using the
netstatcommand as follows:$ netstat -s
- One more utility very similar to
netstatisss. It displays detailed TCP socket information. Usesswithout any parameters to get a list of all the sockets with a state established. - Another command,
lsof, gives you a list of all open files. It includes the files used for network connections or sockets. Use with flag-ito list all network files, as follows:$ sudo lsof -i
- To filter output, use flag
-swith protocol andstateas filter options:$ sudo lsof -iTCP -sTCP:LISTEN - Next, we will look at a well-known tool,
tcpdump. It collects network traffic and displays it to a standard output or dump in a file system. You can dump the content of the packets for any network interface. When no interface is specified,tcpdumpdefaults to the first configured interface, which is generallyeth0. Use it as follows to get a description of packets exchanged overeth0:$ sudo tcpdump -i eth0 - To log raw packets to a file, use flag
-w. These logged packets can later be read with the-rflag. The following command will log100packets from the interfaceeth0to the filetcpdump.log:$ sudo tcpdump -i eth0 -w tcpdump.log -c 100 $ tcpdump -r tcpdump.log
- Next, to get statistics of network traffic, use the command
sar. We have already usedsarto get CPU and memory statistics. To simply extract all network statistics, usesaras follows:$ sar -n ALL 1 5
- This will log all network statistics at an interval of
1second. You can also enable periodic logging in the file/etc/default/sysstat. For network specific usage ofsar, check flag-nin the man pages. - There is one more utility named
collectlwhich is similar tosar. In the same way assar, you will need to separately install this command as well:$ sudo apt-get install collectl - Once installed, use
collectlwith the-sflag and valuesnto get statistics about the network. Using it without any parameters gives you statistics for the CPU, disk, and network:
How it works…
This recipe covers various network monitoring commands including the commonly used ifconfig and ping, netstat, tcpdump, and collectl.
If you have been working with Linux systems for a while, you should have already used the basic network commands, ifconfig and ping. Ifconfig is commonly used to read network configuration and get details of network interfaces. Apart from its basic use, ifconfig can also be used to configure the network interface. See Chapter 2, Networking, to get more details on network configuration. With netstat, you can get a list of all network sockets and their respective processes using those socket connections. With various parameters, you can easily separate active or listening connections and even separate connections with the protocol being used by the socket. Additionally, netstat provides details of routing table information and network statistics as well. The command ss provides similar details to netstat and adds some more information. You can use ss to get memory usages of socket (-m) and the process using that particular socket (-p). It also provides various filtering options to get the desired output. Check the manual pages of ss with the command, man ss.
There's more…
Following are some more commands that can be useful when monitoring network data. With a limit on page count, it is not possible to cover them all, so I am simply listing the relevant commands:
Tip
Many of these commands need to be installed separately. Simply type in the command if it's not available, and Ubuntu will help you with a command to install the respective package.
nethogs: Monitors per process bandwidth utilizationntop / iftop: Top for network monitoringiptraf: Monitors network interface activityvnstat: Network traffic monitoring with loggingethtool: Queries and configures network interfacesnicstat / ifstat / nstat: Network interface statisticstracepath: Traces a network route to destination host
Getting ready
Some commands may need sudo access.
You may need to install a few tools.
How to do it…
- We will start with a commonly used command, that is,
ifconfig. We mostly use this command to read the network configuration details such as the IP address. When called without any parameters,ifconfigdisplays details of all active network interfaces as follows: - These details contain the IP address assigned to each network interface, its hardware address, the maximum packet size (
MTU) and basic statistics of received (RX) and transmitted (TX) packets, and the count of errors or dropped packets, and so on. - If you are only interested in quick network statistics, use
ifconfigwith flag-s, as follows: - If you do not see a specific network interface listed in the active list, then query for all available interfaces with the
-aoption toifconfig. - Another commonly used command is
ping. It sends ICMP requests to a specified host and waits for the reply. If you query for a host name,pingwill get its IP address from DNS. This also gives you confirmation that the DNS is working properly. Ping also gives you the latency of your network interface. Check for thetimevalues in the output of thepingcommand: - Next, comes
netstat. It is mainly used to check network connections and routing tables on the system. The commonly used syntax is as follows:$ sudo netstat -plutn - The preceding command should list all TCP (
-t) / UDP (-u) connections, plus any ports that are actively listening (-l) for connection. The flag,-p, queries the program name responsible for a specified connection. Note that flag-prequires sudo privileges. Also check flag-ato get all listening as well as non-listening sockets, or query the routing table information with flag-ras follows:$ netstat -r - You can also get protocol level network statistics using the
netstatcommand as follows:$ netstat -s - One more utility very similar to
netstatisss. It displays detailed TCP socket information. Usesswithout any parameters to get a list of all the sockets with a state established. - Another command,
lsof, gives you a list of all open files. It includes the files used for network connections or sockets. Use with flag-ito list all network files, as follows:$ sudo lsof -i - To filter output, use flag
-swith protocol andstateas filter options:$ sudo lsof -iTCP -sTCP:LISTEN - Next, we will look at a well-known tool,
tcpdump. It collects network traffic and displays it to a standard output or dump in a file system. You can dump the content of the packets for any network interface. When no interface is specified,tcpdumpdefaults to the first configured interface, which is generallyeth0. Use it as follows to get a description of packets exchanged overeth0:$ sudo tcpdump -i eth0 - To log raw packets to a file, use flag
-w. These logged packets can later be read with the-rflag. The following command will log100packets from the interfaceeth0to the filetcpdump.log:$ sudo tcpdump -i eth0 -w tcpdump.log -c 100 $ tcpdump -r tcpdump.log
- Next, to get statistics of network traffic, use the command
sar. We have already usedsarto get CPU and memory statistics. To simply extract all network statistics, usesaras follows:$ sar -n ALL 1 5 - This will log all network statistics at an interval of
1second. You can also enable periodic logging in the file/etc/default/sysstat. For network specific usage ofsar, check flag-nin the man pages. - There is one more utility named
collectlwhich is similar tosar. In the same way assar, you will need to separately install this command as well:$ sudo apt-get install collectl - Once installed, use
collectlwith the-sflag and valuesnto get statistics about the network. Using it without any parameters gives you statistics for the CPU, disk, and network:
How it works…
This recipe covers various network monitoring commands including the commonly used ifconfig and ping, netstat, tcpdump, and collectl.
If you have been working with Linux systems for a while, you should have already used the basic network commands, ifconfig and ping. Ifconfig is commonly used to read network configuration and get details of network interfaces. Apart from its basic use, ifconfig can also be used to configure the network interface. See Chapter 2, Networking, to get more details on network configuration. With netstat, you can get a list of all network sockets and their respective processes using those socket connections. With various parameters, you can easily separate active or listening connections and even separate connections with the protocol being used by the socket. Additionally, netstat provides details of routing table information and network statistics as well. The command ss provides similar details to netstat and adds some more information. You can use ss to get memory usages of socket (-m) and the process using that particular socket (-p). It also provides various filtering options to get the desired output. Check the manual pages of ss with the command, man ss.
There's more…
Following are some more commands that can be useful when monitoring network data. With a limit on page count, it is not possible to cover them all, so I am simply listing the relevant commands:
Tip
Many of these commands need to be installed separately. Simply type in the command if it's not available, and Ubuntu will help you with a command to install the respective package.
nethogs: Monitors per process bandwidth utilizationntop / iftop: Top for network monitoringiptraf: Monitors network interface activityvnstat: Network traffic monitoring with loggingethtool: Queries and configures network interfacesnicstat / ifstat / nstat: Network interface statisticstracepath: Traces a network route to destination host
How to do it…
- We will start with a commonly used command, that is,
ifconfig. We mostly use this command to read the network configuration details such as the IP address. When called without any parameters,ifconfigdisplays details of all active network interfaces as follows: - These details contain the IP address assigned to each network interface, its hardware address, the maximum packet size (
MTU) and basic statistics of received (RX) and transmitted (TX) packets, and the count of errors or dropped packets, and so on. - If you are only interested in quick network statistics, use
ifconfigwith flag-s, as follows: - If you do not see a specific network interface listed in the active list, then query for all available interfaces with the
-aoption toifconfig. - Another commonly used command is
ping. It sends ICMP requests to a specified host and waits for the reply. If you query for a host name,pingwill get its IP address from DNS. This also gives you confirmation that the DNS is working properly. Ping also gives you the latency of your network interface. Check for thetimevalues in the output of thepingcommand: - Next, comes
netstat. It is mainly used to check network connections and routing tables on the system. The commonly used syntax is as follows:$ sudo netstat -plutn - The preceding command should list all TCP (
-t) / UDP (-u) connections, plus any ports that are actively listening (-l) for connection. The flag,-p, queries the program name responsible for a specified connection. Note that flag-prequires sudo privileges. Also check flag-ato get all listening as well as non-listening sockets, or query the routing table information with flag-ras follows:$ netstat -r - You can also get protocol level network statistics using the
netstatcommand as follows:$ netstat -s - One more utility very similar to
netstatisss. It displays detailed TCP socket information. Usesswithout any parameters to get a list of all the sockets with a state established. - Another command,
lsof, gives you a list of all open files. It includes the files used for network connections or sockets. Use with flag-ito list all network files, as follows:$ sudo lsof -i - To filter output, use flag
-swith protocol andstateas filter options:$ sudo lsof -iTCP -sTCP:LISTEN - Next, we will look at a well-known tool,
tcpdump. It collects network traffic and displays it to a standard output or dump in a file system. You can dump the content of the packets for any network interface. When no interface is specified,tcpdumpdefaults to the first configured interface, which is generallyeth0. Use it as follows to get a description of packets exchanged overeth0:$ sudo tcpdump -i eth0 - To log raw packets to a file, use flag
-w. These logged packets can later be read with the-rflag. The following command will log100packets from the interfaceeth0to the filetcpdump.log:$ sudo tcpdump -i eth0 -w tcpdump.log -c 100 $ tcpdump -r tcpdump.log
- Next, to get statistics of network traffic, use the command
sar. We have already usedsarto get CPU and memory statistics. To simply extract all network statistics, usesaras follows:$ sar -n ALL 1 5 - This will log all network statistics at an interval of
1second. You can also enable periodic logging in the file/etc/default/sysstat. For network specific usage ofsar, check flag-nin the man pages. - There is one more utility named
collectlwhich is similar tosar. In the same way assar, you will need to separately install this command as well:$ sudo apt-get install collectl - Once installed, use
collectlwith the-sflag and valuesnto get statistics about the network. Using it without any parameters gives you statistics for the CPU, disk, and network:
How it works…
This recipe covers various network monitoring commands including the commonly used ifconfig and ping, netstat, tcpdump, and collectl.
If you have been working with Linux systems for a while, you should have already used the basic network commands, ifconfig and ping. Ifconfig is commonly used to read network configuration and get details of network interfaces. Apart from its basic use, ifconfig can also be used to configure the network interface. See Chapter 2, Networking, to get more details on network configuration. With netstat, you can get a list of all network sockets and their respective processes using those socket connections. With various parameters, you can easily separate active or listening connections and even separate connections with the protocol being used by the socket. Additionally, netstat provides details of routing table information and network statistics as well. The command ss provides similar details to netstat and adds some more information. You can use ss to get memory usages of socket (-m) and the process using that particular socket (-p). It also provides various filtering options to get the desired output. Check the manual pages of ss with the command, man ss.
There's more…
Following are some more commands that can be useful when monitoring network data. With a limit on page count, it is not possible to cover them all, so I am simply listing the relevant commands:
Tip
Many of these commands need to be installed separately. Simply type in the command if it's not available, and Ubuntu will help you with a command to install the respective package.
nethogs: Monitors per process bandwidth utilizationntop / iftop: Top for network monitoringiptraf: Monitors network interface activityvnstat: Network traffic monitoring with loggingethtool: Queries and configures network interfacesnicstat / ifstat / nstat: Network interface statisticstracepath: Traces a network route to destination host
How it works…
This recipe covers various network monitoring commands including the commonly used ifconfig and ping, netstat, tcpdump, and collectl.
If you have been working with Linux systems for a while, you should have already used the basic network commands, ifconfig and ping. Ifconfig is commonly used to read network configuration and get details of network interfaces. Apart from its basic use, ifconfig can also be used to configure the network interface. See Chapter 2, Networking, to get more details on network configuration. With netstat, you can get a list of all network sockets and their respective processes using those socket connections. With various parameters, you can easily separate active or listening connections and even separate connections with the protocol being used by the socket. Additionally, netstat provides details of routing table information and network statistics as well. The command ss provides similar details to netstat and adds some more information. You can use ss to get memory usages of socket (-m) and the process using that particular socket (-p). It also provides various filtering options to get the desired output. Check the manual pages of ss with the command, man ss.
There's more…
Following are some more commands that can be useful when monitoring network data. With a limit on page count, it is not possible to cover them all, so I am simply listing the relevant commands:
Tip
Many of these commands need to be installed separately. Simply type in the command if it's not available, and Ubuntu will help you with a command to install the respective package.
nethogs: Monitors per process bandwidth utilizationntop / iftop: Top for network monitoringiptraf: Monitors network interface activityvnstat: Network traffic monitoring with loggingethtool: Queries and configures network interfacesnicstat / ifstat / nstat: Network interface statisticstracepath: Traces a network route to destination host
There's more…
Following are some more commands that can be useful when monitoring network data. With a limit on page count, it is not possible to cover them all, so I am simply listing the relevant commands:
Tip
Many of these commands need to be installed separately. Simply type in the command if it's not available, and Ubuntu will help you with a command to install the respective package.
nethogs: Monitors per process bandwidth utilizationntop / iftop: Top for network monitoringiptraf: Monitors network interface activityvnstat: Network traffic monitoring with loggingethtool: Queries and configures network interfacesnicstat / ifstat / nstat: Network interface statisticstracepath: Traces a network route to destination host
Monitoring storage
Storage is one of the slowest components in a server's system, but is still the most important component. Storage is mainly used as a persistence mechanism to store a large amount of processed/unprocessed data. A slow storage device generally results in heavy utilization of read write buffers and higher memory consumption. You will see higher CPU usage, but most of the CPU time is spent waiting for I/O requests.
The recent developments of the flash storage medium have vastly improved storage performance. Still, it's one of the slowest performing components and needs proper planning— I/O planning in the application code, plus enough main memory for read write buffers.
In this recipe, we will learn to monitor storage performance. The main focus will be on local storage devices rather than network storage.
Getting ready
As always, you will need sudo access for some commands.
Some of the commands many not be available by default. Using them will prompt you if the command is not available, along with the process necessary to install the required package.
Install the sysstat package as follows. We have already used it in previous recipes:
$ sudo apt get install sysstat
How to do it…
- The first command we will look at is
vmstat. Usingvmstatwithout any option displays aniocolumn with two sub entries: bytes in (bi) and bytes out (bo). Bytes in represents the number of bytes read in per second from the disk and bytes out represents the bytes written to the disk:
- Vmstat also provides two flags,
-dand-D, to get disk statistics. Flag-ddisplays disk statistics and flag-Ddisplays a summary view of disk activity:
- There's one more option,
-p, that displays partition-specific disk statistics. Use the commandlsblkto get a list of available partitions and then use thevmstat -ppartition:
- Another command,
dstat, is a nice replacement forvmstat, especially for disk statistics reporting. Use it with flag-dto get disk read writes per seconds. If you have multiple disks, you can usedstatto list their stats separately:$ dstat -d -D total,sda - Next, we will look at the command
iostat. When used without any options, this command displays basic CPU utilization, along with read write statistics for each storage device:
- The column
tpsspecifies the I/O requests sent to a device per second, andkb_read/sandkb_wrtn/sspecifies per second blocks read and blocks written respectively.kb_readandkb_wrtnshows the total number of blocks read and written. - Some common options for
iostatinclude–d, that displays disk only statistics,-gthat displays statistics for a group of devices, flag-pto display partition specific stats, and-xto get extended statistics. Do not forget to check the manual entries foriostatto get more details. - You can also use the command
iotop, which is very similar to thetopcommand but it displays disk utilization and relevant processes. - The command
lsofcan display the list of all open files and respective processes using that file. Uselsofwith the process name to get files opened by that process:$ lsof -c sshd
- To get a list of files opened by a specific pid, use the following command:
$ lsof -p 1134.Or, to get a list of files opened by a specific user, use the$ lsof -u ubuntucommand.All these commands provide details on the read write performance of a storage device. Another important detail to know is the availability of free space. To get details of space utilization, you can use command
df -h. This will list a partition-level summary of disk space utilization:
- Finally, you can use the
sarcommand to track disk performance over a period of time. To get real-time disk activity, usesarwith the-doption, as follows:$ sar -d 1
- Use flag
-Fto get details on file system utilization and flag-Sto display swap utilization. You can also enable sar logging and then extract details from those logs. Check the previous recipes in this chapter for how to enable sar logging. Also check manual entries for sar to get details of various options.
Getting ready
As always, you will need sudo access for some commands.
Some of the commands many not be available by default. Using them will prompt you if the command is not available, along with the process necessary to install the required package.
Install the sysstat package as follows. We have already used it in previous recipes:
$ sudo apt get install sysstat
How to do it…
- The first command we will look at is
vmstat. Usingvmstatwithout any option displays aniocolumn with two sub entries: bytes in (bi) and bytes out (bo). Bytes in represents the number of bytes read in per second from the disk and bytes out represents the bytes written to the disk: - Vmstat also provides two flags,
-dand-D, to get disk statistics. Flag-ddisplays disk statistics and flag-Ddisplays a summary view of disk activity: - There's one more option,
-p, that displays partition-specific disk statistics. Use the commandlsblkto get a list of available partitions and then use thevmstat -ppartition: - Another command,
dstat, is a nice replacement forvmstat, especially for disk statistics reporting. Use it with flag-dto get disk read writes per seconds. If you have multiple disks, you can usedstatto list their stats separately:$ dstat -d -D total,sda - Next, we will look at the command
iostat. When used without any options, this command displays basic CPU utilization, along with read write statistics for each storage device: - The column
tpsspecifies the I/O requests sent to a device per second, andkb_read/sandkb_wrtn/sspecifies per second blocks read and blocks written respectively.kb_readandkb_wrtnshows the total number of blocks read and written. - Some common options for
iostatinclude–d, that displays disk only statistics,-gthat displays statistics for a group of devices, flag-pto display partition specific stats, and-xto get extended statistics. Do not forget to check the manual entries foriostatto get more details. - You can also use the command
iotop, which is very similar to thetopcommand but it displays disk utilization and relevant processes. - The command
lsofcan display the list of all open files and respective processes using that file. Uselsofwith the process name to get files opened by that process:$ lsof -c sshd - To get a list of files opened by a specific pid, use the following command:
$ lsof -p 1134.Or, to get a list of files opened by a specific user, use the$ lsof -u ubuntucommand.All these commands provide details on the read write performance of a storage device. Another important detail to know is the availability of free space. To get details of space utilization, you can use command
df -h. This will list a partition-level summary of disk space utilization: - Finally, you can use the
sarcommand to track disk performance over a period of time. To get real-time disk activity, usesarwith the-doption, as follows:$ sar -d 1 - Use flag
-Fto get details on file system utilization and flag-Sto display swap utilization. You can also enable sar logging and then extract details from those logs. Check the previous recipes in this chapter for how to enable sar logging. Also check manual entries for sar to get details of various options.
How to do it…
- The first command we will look at is
vmstat. Usingvmstatwithout any option displays aniocolumn with two sub entries: bytes in (bi) and bytes out (bo). Bytes in represents the number of bytes read in per second from the disk and bytes out represents the bytes written to the disk: - Vmstat also provides two flags,
-dand-D, to get disk statistics. Flag-ddisplays disk statistics and flag-Ddisplays a summary view of disk activity: - There's one more option,
-p, that displays partition-specific disk statistics. Use the commandlsblkto get a list of available partitions and then use thevmstat -ppartition: - Another command,
dstat, is a nice replacement forvmstat, especially for disk statistics reporting. Use it with flag-dto get disk read writes per seconds. If you have multiple disks, you can usedstatto list their stats separately:$ dstat -d -D total,sda - Next, we will look at the command
iostat. When used without any options, this command displays basic CPU utilization, along with read write statistics for each storage device: - The column
tpsspecifies the I/O requests sent to a device per second, andkb_read/sandkb_wrtn/sspecifies per second blocks read and blocks written respectively.kb_readandkb_wrtnshows the total number of blocks read and written. - Some common options for
iostatinclude–d, that displays disk only statistics,-gthat displays statistics for a group of devices, flag-pto display partition specific stats, and-xto get extended statistics. Do not forget to check the manual entries foriostatto get more details. - You can also use the command
iotop, which is very similar to thetopcommand but it displays disk utilization and relevant processes. - The command
lsofcan display the list of all open files and respective processes using that file. Uselsofwith the process name to get files opened by that process:$ lsof -c sshd - To get a list of files opened by a specific pid, use the following command:
$ lsof -p 1134.Or, to get a list of files opened by a specific user, use the$ lsof -u ubuntucommand.All these commands provide details on the read write performance of a storage device. Another important detail to know is the availability of free space. To get details of space utilization, you can use command
df -h. This will list a partition-level summary of disk space utilization: - Finally, you can use the
sarcommand to track disk performance over a period of time. To get real-time disk activity, usesarwith the-doption, as follows:$ sar -d 1 - Use flag
-Fto get details on file system utilization and flag-Sto display swap utilization. You can also enable sar logging and then extract details from those logs. Check the previous recipes in this chapter for how to enable sar logging. Also check manual entries for sar to get details of various options.
Setting performance benchmarks
Until now, in this chapter we have learned about various performance monitoring tools and commands. This recipe covers a well-known performance benchmarking tool: Sysbench. The purpose of performance benchmarking is to get a sense of system configuration and the resulting performance. Sysbench is generally used to evaluate the performance of heavy load systems. If you read the Sysbench introduction, it says that Sysbench is a benchmarking tool to evaluate a system running database under intensive load. It is also being used as a tool to evaluate the performance of multiple cloud service providers.
The current version of Sysbench supports various benchmark tests including CPU, memory, IO system, and OLTP systems. We will primarily focus on CPU, memory, and IO benchmarks.
Getting ready
Before using Sysbench, we will need to install it. Sysbench is available in the Ubuntu package repository with a little older (0.4.12) version. We will use the latest version (0.5) from Percona Systems, available in their repo.
To install Sysbench from the Percona repo, we need to add the repo to our installation sources. Following are the entries for Ubuntu 14.04 (trusty). Create a new file under /etc/apt/source.list.d and add the following lines to it:
$ sudo vi /etc/apt/sources.list.d/percona.list deb http://repo.percona.com/apt trusty main deb-src http://repo.percona.com/apt trusty main
Next, add the PGP key for the preceding repo:
$ sudo apt-key adv --keyserver keys.gnupg.net --recv-keys 1C4CBDCDCD2EFD2A
Now we are ready to install the latest version of Sysbench from the Percona repo. Remember to update the apt cache before installation:
$ sudo apt-get update $ sudo apt-get install sysbench
Once installed, you can check the installed version with the --version flag to sysbench:
$ sysbench --version sysbench 0.5
How to do it…
Now that we have Sysbench installed, let's start with performance testing our system:
- Sysbench provides a prime number generation test for CPU. You can set the number of primes to be generated with the option
--cpu-max-prime. Also set the limit on threads with the--num-threadsoption. Set the number of threads equal to the amount of CPU cores available:$ sysbench --test=cpu --num-threads=4 \ --cpu-max-prime=20000 run
- The test should show output similar to the following screenshot:

- Following are the extracted parts of the result from multiple tests with a different thread count on a system with a dual core CPU. It is clear that using two threads give better results:
Threads
1
2
3
4
Total time
33.0697s
15.4335s
15.6258s
15.7778s
- Next, we will run a test for main memory. The memory tests provides multiple options, such as block-size, total data transfer, type of memory operations, and access modes. Use the following command to run memory tests:
$ sysbench --test=memory --memory-block-size=1M \ --num-threads=2 \ --memory-total-size=100G --memory-oper=read run
- Following is part of the output from the memory test:
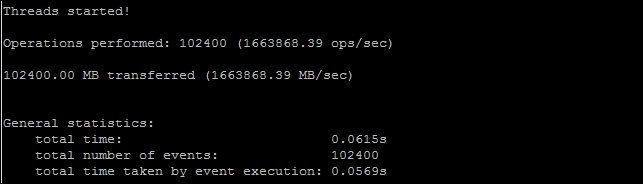
- If you have enabled huge page support, set the memory test support allocation from the huge page pool with the parameter,
--memory-hugetlb. By default, it's set to off. - Next comes the storage performance test. This test also provides you with a number of options to test disk read write speeds. Depending on your requirements, you can set parameters like block-size, random or sequential read writes, synchronous or asynchronous IO operations, and many more.
- For the
fileiotest we need a few sample files to test with. Use thesysbenchpreparecommand to create test files. Make sure to set a total file size greater than the size of memory to avoid caching effects. I am using a small 1GBnode with 20G disk space, so I am using 15 files of 1G each:$ sysbench --test=fileio --file-total-size=15G \ --file-num=15 prepare

- Once the test preparation is complete, you can run the
fileiotest with different options, depending on what you want to test. The following command will perform random write operations for60seconds:$ sysbench --test=fileio --file-total-size=15G \ --file-test-mode=rndwr --max-time=60 \ --file-block-size=4K --file-num=15 --num-threads=1 run

- To perform random read operations, change
--file-test-modetorndrd, or to perform sequential read operations, useseqrd. You can also combine read write operations withrndrworseqrewr. Check the help menu for more options.Tip
To get a full list of available options, enter the
sysbenchcommand without any parameter. You can also query details of a specific test withsysbench --test=<name> help. For example, to get help with I/O tests, use:$ sysbench --test=fileio help - When you are done with the
fileiotest, execute thecleanupcommand to delete all sample files:$ sysbench --test=fileio cleanup - Once you have gathered various performance details, you can try updating various performance tuning parameters to boost performance. Make sure you repeat related tests after each change in parameter. Comparing results from multiple tests will help you to choose the required combination for best performance and a stable system.
There's more…
Sysbench also supports testing MySQL performance with various tests. In the same way as the fileio test, Sysbench takes care of setting a test environment by creating tables with data. When using Sysbench from the Percona repo, all OLTP test scripts are located at /usr/share/doc/sysbench/tests/db/. You will need to specify the full path when using these scripts. For example:
$ sysbench --test=oltp
The preceding command will change to the following:
$ sysbench --test=/usr/share/doc/sysbench/tests/db/ol1tp.lua
Graphing tools
Sysbench output can be hard to analyze and compare, especially with multiple runs. This is where graphs come in handy. You can try to set up your own graphing mechanism, or simply use prebuilt scripts to create graphs for you. A quick Google search gave me two good, looking options:
- A Python script to extract data from Sysbench logs: https://github.com/tsuna/sysbench-tools
- A shell script to extract Sysbench data to a CSV file, which can be converted to graphs: http://openlife.cc/blogs/2011/august/one-liner-condensing-sysbench-output-csv-file
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
See also
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
Getting ready
Before using Sysbench, we will need to install it. Sysbench is available in the Ubuntu package repository with a little older (0.4.12) version. We will use the latest version (0.5) from Percona Systems, available in their repo.
To install Sysbench from the Percona repo, we need to add the repo to our installation sources. Following are the entries for Ubuntu 14.04 (trusty). Create a new file under /etc/apt/source.list.d and add the following lines to it:
$ sudo vi /etc/apt/sources.list.d/percona.list deb http://repo.percona.com/apt trusty main deb-src http://repo.percona.com/apt trusty main
Next, add the PGP key for the preceding repo:
$ sudo apt-key adv --keyserver keys.gnupg.net --recv-keys 1C4CBDCDCD2EFD2A
Now we are ready to install the latest version of Sysbench from the Percona repo. Remember to update the apt cache before installation:
$ sudo apt-get update $ sudo apt-get install sysbench
Once installed, you can check the installed version with the --version flag to sysbench:
$ sysbench --version sysbench 0.5
How to do it…
Now that we have Sysbench installed, let's start with performance testing our system:
- Sysbench provides a prime number generation test for CPU. You can set the number of primes to be generated with the option
--cpu-max-prime. Also set the limit on threads with the--num-threadsoption. Set the number of threads equal to the amount of CPU cores available:$ sysbench --test=cpu --num-threads=4 \ --cpu-max-prime=20000 run
- The test should show output similar to the following screenshot:
- Following are the extracted parts of the result from multiple tests with a different thread count on a system with a dual core CPU. It is clear that using two threads give better results:
Threads
1
2
3
4
Total time
33.0697s
15.4335s
15.6258s
15.7778s
- Next, we will run a test for main memory. The memory tests provides multiple options, such as block-size, total data transfer, type of memory operations, and access modes. Use the following command to run memory tests:
$ sysbench --test=memory --memory-block-size=1M \ --num-threads=2 \ --memory-total-size=100G --memory-oper=read run
- Following is part of the output from the memory test:
- If you have enabled huge page support, set the memory test support allocation from the huge page pool with the parameter,
--memory-hugetlb. By default, it's set to off. - Next comes the storage performance test. This test also provides you with a number of options to test disk read write speeds. Depending on your requirements, you can set parameters like block-size, random or sequential read writes, synchronous or asynchronous IO operations, and many more.
- For the
fileiotest we need a few sample files to test with. Use thesysbenchpreparecommand to create test files. Make sure to set a total file size greater than the size of memory to avoid caching effects. I am using a small 1GBnode with 20G disk space, so I am using 15 files of 1G each:$ sysbench --test=fileio --file-total-size=15G \ --file-num=15 prepare
- Once the test preparation is complete, you can run the
fileiotest with different options, depending on what you want to test. The following command will perform random write operations for60seconds:$ sysbench --test=fileio --file-total-size=15G \ --file-test-mode=rndwr --max-time=60 \ --file-block-size=4K --file-num=15 --num-threads=1 run
- To perform random read operations, change
--file-test-modetorndrd, or to perform sequential read operations, useseqrd. You can also combine read write operations withrndrworseqrewr. Check the help menu for more options.Tip
To get a full list of available options, enter the
sysbenchcommand without any parameter. You can also query details of a specific test withsysbench --test=<name> help. For example, to get help with I/O tests, use:$ sysbench --test=fileio help - When you are done with the
fileiotest, execute thecleanupcommand to delete all sample files:$ sysbench --test=fileio cleanup - Once you have gathered various performance details, you can try updating various performance tuning parameters to boost performance. Make sure you repeat related tests after each change in parameter. Comparing results from multiple tests will help you to choose the required combination for best performance and a stable system.
There's more…
Sysbench also supports testing MySQL performance with various tests. In the same way as the fileio test, Sysbench takes care of setting a test environment by creating tables with data. When using Sysbench from the Percona repo, all OLTP test scripts are located at /usr/share/doc/sysbench/tests/db/. You will need to specify the full path when using these scripts. For example:
$ sysbench --test=oltp
The preceding command will change to the following:
$ sysbench --test=/usr/share/doc/sysbench/tests/db/ol1tp.lua
Graphing tools
Sysbench output can be hard to analyze and compare, especially with multiple runs. This is where graphs come in handy. You can try to set up your own graphing mechanism, or simply use prebuilt scripts to create graphs for you. A quick Google search gave me two good, looking options:
- A Python script to extract data from Sysbench logs: https://github.com/tsuna/sysbench-tools
- A shell script to extract Sysbench data to a CSV file, which can be converted to graphs: http://openlife.cc/blogs/2011/august/one-liner-condensing-sysbench-output-csv-file
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
See also
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
How to do it…
Now that we have Sysbench installed, let's start with performance testing our system:
- Sysbench provides a prime number generation test for CPU. You can set the number of primes to be generated with the option
--cpu-max-prime. Also set the limit on threads with the--num-threadsoption. Set the number of threads equal to the amount of CPU cores available:$ sysbench --test=cpu --num-threads=4 \ --cpu-max-prime=20000 run
- The test should show output similar to the following screenshot:
- Following are the extracted parts of the result from multiple tests with a different thread count on a system with a dual core CPU. It is clear that using two threads give better results:
Threads
1
2
3
4
Total time
33.0697s
15.4335s
15.6258s
15.7778s
- Next, we will run a test for main memory. The memory tests provides multiple options, such as block-size, total data transfer, type of memory operations, and access modes. Use the following command to run memory tests:
$ sysbench --test=memory --memory-block-size=1M \ --num-threads=2 \ --memory-total-size=100G --memory-oper=read run
- Following is part of the output from the memory test:
- If you have enabled huge page support, set the memory test support allocation from the huge page pool with the parameter,
--memory-hugetlb. By default, it's set to off. - Next comes the storage performance test. This test also provides you with a number of options to test disk read write speeds. Depending on your requirements, you can set parameters like block-size, random or sequential read writes, synchronous or asynchronous IO operations, and many more.
- For the
fileiotest we need a few sample files to test with. Use thesysbenchpreparecommand to create test files. Make sure to set a total file size greater than the size of memory to avoid caching effects. I am using a small 1GBnode with 20G disk space, so I am using 15 files of 1G each:$ sysbench --test=fileio --file-total-size=15G \ --file-num=15 prepare
- Once the test preparation is complete, you can run the
fileiotest with different options, depending on what you want to test. The following command will perform random write operations for60seconds:$ sysbench --test=fileio --file-total-size=15G \ --file-test-mode=rndwr --max-time=60 \ --file-block-size=4K --file-num=15 --num-threads=1 run
- To perform random read operations, change
--file-test-modetorndrd, or to perform sequential read operations, useseqrd. You can also combine read write operations withrndrworseqrewr. Check the help menu for more options.Tip
To get a full list of available options, enter the
sysbenchcommand without any parameter. You can also query details of a specific test withsysbench --test=<name> help. For example, to get help with I/O tests, use:$ sysbench --test=fileio help - When you are done with the
fileiotest, execute thecleanupcommand to delete all sample files:$ sysbench --test=fileio cleanup - Once you have gathered various performance details, you can try updating various performance tuning parameters to boost performance. Make sure you repeat related tests after each change in parameter. Comparing results from multiple tests will help you to choose the required combination for best performance and a stable system.
There's more…
Sysbench also supports testing MySQL performance with various tests. In the same way as the fileio test, Sysbench takes care of setting a test environment by creating tables with data. When using Sysbench from the Percona repo, all OLTP test scripts are located at /usr/share/doc/sysbench/tests/db/. You will need to specify the full path when using these scripts. For example:
$ sysbench --test=oltp
The preceding command will change to the following:
$ sysbench --test=/usr/share/doc/sysbench/tests/db/ol1tp.lua
Graphing tools
Sysbench output can be hard to analyze and compare, especially with multiple runs. This is where graphs come in handy. You can try to set up your own graphing mechanism, or simply use prebuilt scripts to create graphs for you. A quick Google search gave me two good, looking options:
- A Python script to extract data from Sysbench logs: https://github.com/tsuna/sysbench-tools
- A shell script to extract Sysbench data to a CSV file, which can be converted to graphs: http://openlife.cc/blogs/2011/august/one-liner-condensing-sysbench-output-csv-file
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
See also
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
There's more…
Sysbench also supports testing MySQL performance with various tests. In the same way as the fileio test, Sysbench takes care of setting a test environment by creating tables with data. When using Sysbench from the Percona repo, all OLTP test scripts are located at /usr/share/doc/sysbench/tests/db/. You will need to specify the full path when using these scripts. For example:
$ sysbench --test=oltp
The preceding command will change to the following:
$ sysbench --test=/usr/share/doc/sysbench/tests/db/ol1tp.lua
Graphing tools
Sysbench output can be hard to analyze and compare, especially with multiple runs. This is where graphs come in handy. You can try to set up your own graphing mechanism, or simply use prebuilt scripts to create graphs for you. A quick Google search gave me two good, looking options:
- A Python script to extract data from Sysbench logs: https://github.com/tsuna/sysbench-tools
- A shell script to extract Sysbench data to a CSV file, which can be converted to graphs: http://openlife.cc/blogs/2011/august/one-liner-condensing-sysbench-output-csv-file
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
See also
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
Graphing tools
Sysbench output can be hard to analyze and compare, especially with multiple runs. This is where graphs come in handy. You can try to set up your own graphing mechanism, or simply use prebuilt scripts to create graphs for you. A quick Google search gave me two good, looking options:
- A Python script to extract data from Sysbench logs: https://github.com/tsuna/sysbench-tools
- A shell script to extract Sysbench data to a CSV file, which can be converted to graphs: http://openlife.cc/blogs/2011/august/one-liner-condensing-sysbench-output-csv-file
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
More options
There are various other performance testing frameworks available. Phoronix Test Suite, Unixbench, and Perfkit by Google are some popular names. Phoronix Test Suite focuses on hardware performance and provides a wide range of performance analysis options, whereas Unixbench provides an option to test various Linux systems. Google open-sourced their performance toolkit with a benchmarker and explorer to evaluate various cloud systems.
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
See also
- Get more details on benchmarking with Sysbench at https://wiki.mikejung.biz/Benchmarking
- Sysbench documentation at http://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
- A sample script to run batch run multiple Sysbench tests at https://gist.github.com/chetan/712484
- Sysbench GitHub repo at https://github.com/akopytov/sysbench
- Linux performance analysis in 60 seconds. A good read for what to check when you are debugging a performance issue at http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html










