Relational algebra is the formal language of the relational model. It defines a set of closed operations over relations, that is, the result of each operation is a new relation. Relational algebra inherits many operators from set algebra. Relational algebra operations can be categorized into two groups:
-
The first one is a group of operations that are inherited from set theory such as UNION, intersection, set difference, and Cartesian product, also known as cross product.
-
The second is a group of operations that are specific to the relational model such as SELECT and PROJECT. Relational algebra operations could also be classified as binary and unary operations.
The primitive operators are as follows:
- SELECT (σ): A unary operation written as σϕR where ϕ is a predicate. The selection retrieves the tuples in R, where ϕ holds.
- PROJECT (π): A unary operation used to slice the relation in a vertical dimension, that is, attributes. This operation is written as πa1,a2,…,an R(), where a1, a2, ..., an are a set of attribute names.
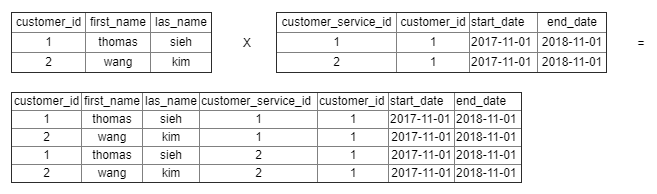
- Cartesian product (×): A binary operation used to generate a more complex relation by joining each tuple of its operands together. Let's assume that R and S are two relations, then R×S = (r1, r2, ..., rn, s1, s2, ..., sn) where (r1, r2,...,rn) ∈ R and (s1, s2, ..., sn) ∈ S.
- UNION (∪): Appends two relations together; note that the relations should be UNION-compatible, that is, they should have the same set of ordered attributes. Formally, R∪S = (r1,r2,...rn) ∪ (s1,s2,...,sn) where (r1, r2,...,rn) ∈ R and (s1, s2, ..., sn) ∈ S.
- Difference (-): A binary operation in which the operands should be UNION-compatible. Difference creates a new relation from the tuples, which exist in one relation but not in the other. The set difference for the relation R and S can be given as R-S = (r1,r2,...rn) where (r1,r2,...rn) ∈ R and (r1,r2,...rn) ∉ S.
- RENAME (ρ): A unary operation that works on attributes. This operator is mainly used to distinguish the attributes with the same names but in different relation when joined together, or it is used to give a more user-friendly name for the attribute for presentation purposes. RENAME is expressed as ρa/bR, where a and b are attribute names and b is an attribute of R.
In addition to the primitive operators, there are aggregation functions such as sum, count, min, max, and avg aggregates. Primitive operators can be used to define other relation operators such as left-join, right-join, equi-join, and intersection. Relational algebra is very important due to its expressive power in optimizing and rewriting queries. For example, the selection is commutative, so σaσbR = σbσaR. A cascaded selection may also be replaced by a single selection with a conjunction of all the predicates, that is, σaσbR = σa AND b R.