






















































If you're a newbie to deep learning, you may be wondering how exactly it is differs from machine learning; or is it the same? Deep learning is a subset of the larger domain of machine learning. Let's think about this in the context of an automobile image classification problem:
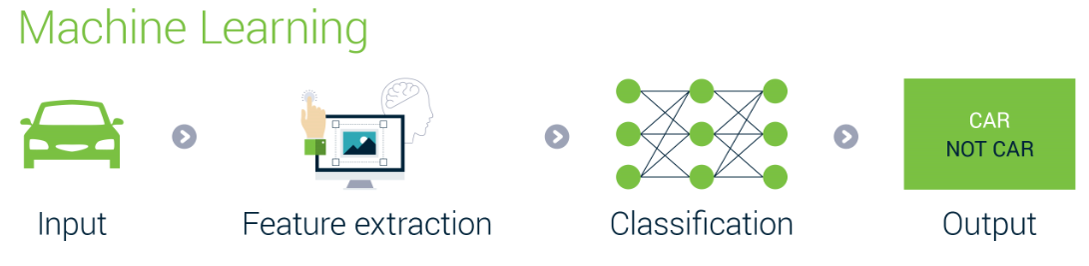
As you can see in the preceding diagram, we need to perform feature extraction ourselves as legacy machine learning algorithms cannot do that on their own. They might be super-efficient with accurate results, but they cannot learn signals from data. In fact, they don't learn on their own and still rely on human effort:
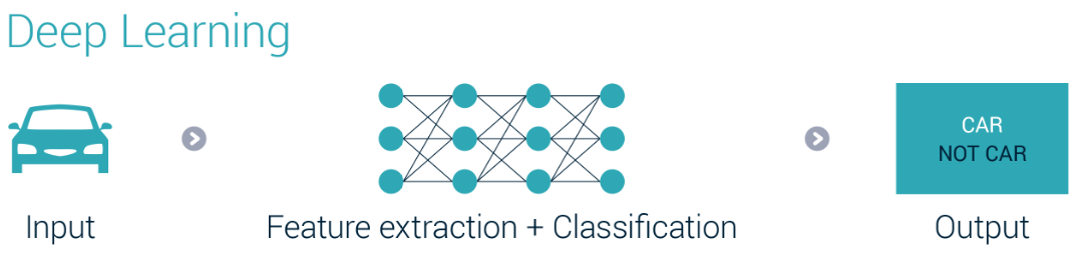
On the other hand, deep learning algorithms learn to perform tasks on their own. Neural networks under the hood are based on the concept of deep learning and it trains on their own to optimize the results. However, the final decision process is hidden and cannot be tracked. The intent of deep learning is to imitate the functioning of a human brain.








