






















































Defining microservices principles will allow us to build scalable, easy-to-maintain enterprise applications. We will focus on benefits and downsides when we review them. We understand that sometimes there could be some disagreement in some of them; however, we encourage you to review them all. Finally, we know that there are probably dozens or more principles that could be included, but we chose the ones that made most sense in the context of this book.
Microservices principles
Defining design principles
We need to choose a set of principles when we design microservices; each of them will have their own advantage that will be reviewed later on in this chapter, but defining them will also allow us to have a consistent approach for different kinds of problems, and will help others understand our architecture.
The key principles that we are going to define are:
- Modelled around business capabilities
- Loosely couple
- Single responsibility
- Hiding implementation
- Isolation
- Independently deployable
- Build for failure
- Scalability
- Automation
Modelled around business capabilities
A well-designed microservice should be modeled around the business capabilities that are meant to be implemented. Designing software has a component of abstraction and we are used to getting requirements and implementing them, but we must consider how everyone, including us, will understand the solution, now and in the future.
When we need to update, or even modify our microservices, we need to abstract back to the original concept that defined it. In that process, we could realize that something was not as we originally understood, or that our design could not evolve. We may even discover that we have to break the boundaries of our business domain and we don't implement the original capability anymore, or that actually it is implemented across a set of different non-related microservices. We could end up coupling our microservices together, and that is something that we want to avoid.
The domain experts of these business capabilities have a clear understanding of how they operate and how those capabilities are combined and used. Working with them could make our microservices understandable for everyone, including our future selves, and will move our services to become not just an abstraction, but a mapping of the original business capability.
Work as closely as you can with your domain experts, it will always benefit you.
We will deep dive more into this topic in the Domain-Driven Design section of this chapter.
Loosely couple
No microservice exists on its own, as any system needs to interact with others, including other microservices, but we need to do it as loosely coupled as we can. Let's say that we are designing a microservice that returns the available offers for a giving customer, we may need a relation to our customer, for example, a customer ID, and that should be the maximum coupling that we may accept.
Imagine a scenario that for a component that uses our offers, the microservice needs to display the customer name when it displays those offers. We could modify our implementation to use the customer microservice to add that information to our response, but in doing so, we are coupling with the customer microservice. In that case, if the customer name field changes, for example, to become not just a name but is separated into surname and forename, we need to change the output of our microservice. That type of coupling needs to be avoided; our microservices should just return what information that is really under their domain.
Remember that our domain experts could help us in understanding if a business capability owns a function; probably the experts in customer offers will know that the customer name is something that is a handle in another business capability.
We need to take care of how we are coupling, not only between microservices, but with everything in our architecture, including external systems. That is one of the reasons why every microservice should own its own data, this including even a database where the data is persisted.
Single responsibility
Every microservice should have responsibility over a single part of the functionality provided by the application, and that responsibility should be entirely encapsulated by the microservice. The design of the microservice should be narrowly aligned with that responsibility.
We could adopt Robert C. Martin's definition of the principle applied to OOP that said: "A class should have only one reason to change"; for this principle, we can say: a microservice should have only one reason to change.
If we realize that when we need to change a business function within our application, it modifies several microservices, or that a change cascades into non-related microservices, it is time that we reconsider how we design them.
This does not mean that we get to make microservices that do only one operation. Probably it is a good idea to have a microservice that handles the customer operations, like create, find, delete, but probably shouldn't handle operations like adding offers to a customer.
Hiding implementation
Microservices usually have a clear and easy to understand interface that must hide the implementation details. We shouldn't expose the internal details, neither technical implementation nor the business rules that drive it.
Applying this principle, we reduce the coupling to others, and that any change in our details affect them. We will prevent the technical changes or improvements that impact the overall architecture. We should always be able to change when needed, from where we persist our business model, to the programming languages or frameworks that we use.
But we also need to be able to modify our logic and rules, to adapt to any change within our domain without affecting the overall application. Helping to handle change is one of the benefits of a well-designed microservice architecture.
Isolation
A microservice should be physically and/or logically isolated from the infrastructure that uses the systems that it depends on. If we use a database, it must be our database, if we are running in a server, it should be in our server, and so on. With this, we guarantee that nothing external is affecting us and neither are we affecting anything external.
This will help from deployments to performance or monitoring, or even in building our continuous delivery pipeline. It will facilitate how we can be controlled and scaled independently, and will help the ops functions within our team to manage our microservices.
We should move away from the days when a failure in some parts of the architecture was affecting others. Containers are one of the key architectures to effectively archive this principle. We will learn more about this in the Cloud Native microservices section of this chapter.
Independently deployable
Microservices should be independently deployable; if not, it probably means that there is some kind of coupling within our architecture that needs to be solved. If we could meet other principles but we fail at this, we are probably decrementing the benefits of this architecture.
Having the ability to deliver constantly is one of the advantages of the microservices architecture; any constraints should be removed, as much as we remove bugs from our applications.
We should take care of deployments from the beginning of the design of our microservices and architecture; finding a constraint on this area at late stages could have a big impact on the overall application.
Build for failure
It doesn't matter how many tests we do in our microservice, how many controls are in place, how many alerts could be triggered; if our microservice is going to fail, we need to design for that failure, to handle it as gracefully as possible, and define how we could recover from it.
"Anything that can go wrong will go wrong."
– Murphy
When we approach the initial design of a microservice, we need to start working on the more basic errors that we need to handle. As the design grows, we should think of all the edge scenarios, and finally what could go really wrong. Then, we need to assess how we are going to notify, monitor, and control those situations, how we could recover, and if we have the right information and tools for solving them.
Think of these areas when you design a microservice:
- Upstream
- Downstream
- Logging
- Monitoring
- Alerting
- Recovery
- Fallbacks
Upstream
Upstream is understanding how we are going to, or if we are not going to, notify errors to our consumers, but remembering always to avoid coupling.
Downstream
Downstream refers to how we are going to handle, if something that we depend on fails, as another microservice, or even a system, like a database.
Logging
Logging is about taking care of how we are going to log any failure, thinking if we are doing it too often or too infrequently, the amount of information, and how this can be accessed. We should take special care about sensitive information and performance implications.
Monitoring
Monitoring needs to be designed thoughtfully. It is a very problematic situation to handle a failure without the right information in the monitoring systems; we should consider what elements of the application have meaningful information.
Alerting
Alerting is to understand what the signals are that could indicate that something is going wrong, its link to our monitoring and probably to our logging, but for any good design application, it is not enough to just alert on anything strange. We require a deeper analysis on the signals and how they are related.
Recovery
Recovery is designing how we are going to act on those failures to get back to a normal state. Automatic recovery should be our target, but manual recovery should not be avoided since automatic recovery could fail.
Fallbacks
Think about how, even if our microservices are failing, we can still respond to whoever uses them. For example, if we design a microservice that retrieves the offers from a customer but encounters a problem acceding to the data layer, maybe it could return a default set of offers that allows the application to at least have some meaningful information. In the same way, if we consume an external service, we may have a fallback mechanism if that service is not available.
Fallbacks are a common pattern to prevent a problem within your architecture affecting other parts of the system. If we have a good fallback, our application could work until that problem is fixed.
Scalability
Microservices should be designed to be independently scalable. If we need to increase how many requests we can handle or how many records we can hold, we should do it in isolation. We should avoid that, due to a coupling on the architecture; the only way to scale our application is scaling several components together or through the system as a whole.
Let's go back to the original SoA application example and handle a scenario where we need to scale our offers capability:

Example of scaling a coupled SoA application
Even if what we need to scale is our offer capability, due to the coupling of the system, we need to do it as whole. We will increase how many instances of the presentation and business layer we have, and we increase our database either with more instances or with a bigger database. Probably, we may need to also update some of those servers as the resources that they require will increase. In a microservices architecture, we could just scale the elements that are needed. Let's view how we could scale the same application using microservices:
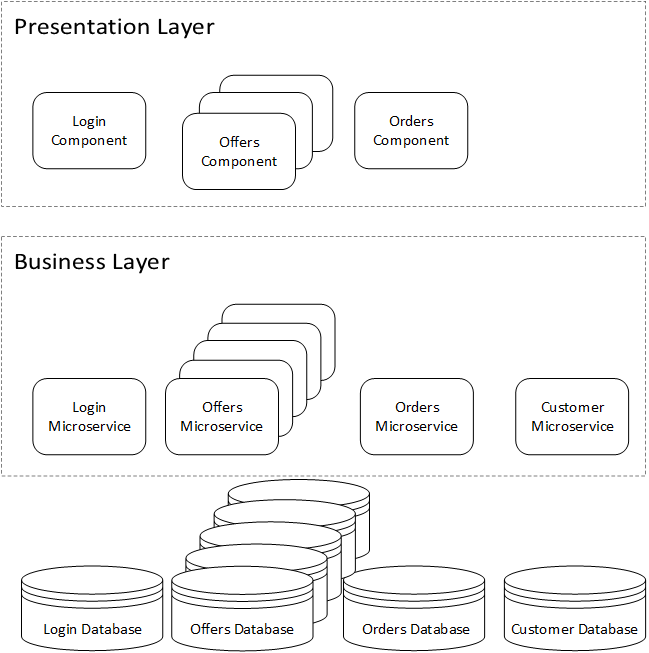
Example of scaling a microservice application
We have just increased what was required for the offers' capability and to keep the rest of the architecture intact, we need to consider that in microservices, those servers are smaller and don't need as many resources due to their limited scope.
In a well-designed microservice architecture, we could effectively have more capacity with less infrastructure since it could be optimized for more accurate use and be scaled independently.
We will review more about this topic in the Cloud Native microservices section of this chapter.
Automation
Our microservices should be designed with automization in mind, from building or testing to deployment and monitoring. Since our services are going to be small and they are isolated, the cost to automatize them should be low and the benefits should be high.
With this principle, we benefit the agility of our application and we prevent unnecessary manual tasks having an impact on the system. For those reasons, Continuous Integration and Continuous Delivery should be designed from the beginning of our architecture.







