






















































Top tips for developing and implementing resilient and scalable applications
Having presented some of the fundamentals of programming in the cloud, it is important to now address one of the topics that is probably the most mentioned but least understood: microservices. In this section, we briefly introduce the microservices ecosystem and explain how to correctly manage user sessions, create traceability logs in order to detect and solve errors, implement retries in order to make our solution reliable, support consumption peaks through autoscaling, and reduce server consumption through information caching.
Microservice ecosystems
Microservices are an architectural design pattern that allows the separation of responsibilities into smaller applications, which can be programmed in different programming languages, can be independent of each other, and have the possibility of scaling both vertically (increasing CPU and memory) and horizontally (creating more instances) independently in order to optimize the cluster resources.
Although microservices have been widely accepted by both start-ups and established organizations, on account of their great advantages, such as decoupling business logic and better code intelligibility, they also have their disadvantages, which are mostly focused on problems of communication management, networking, and observability.
It is therefore important to decide whether the use of a microservices pattern is really necessary. The size of the solution and clarity in the separation of responsibilities are fundamental factors when making this decision. For simpler or smaller solutions, it is perfectly acceptable to use a monolithic-type architecture pattern, where instead of having many small, orchestrated applications, you have just one large application with full responsibility for the solution.
In Chapter 3, Application Modernization using Google Cloud, we will go into greater detail on the technologies used in GCP in order to support an ecosystem of microservices, mitigating the disadvantages mentioned previously:
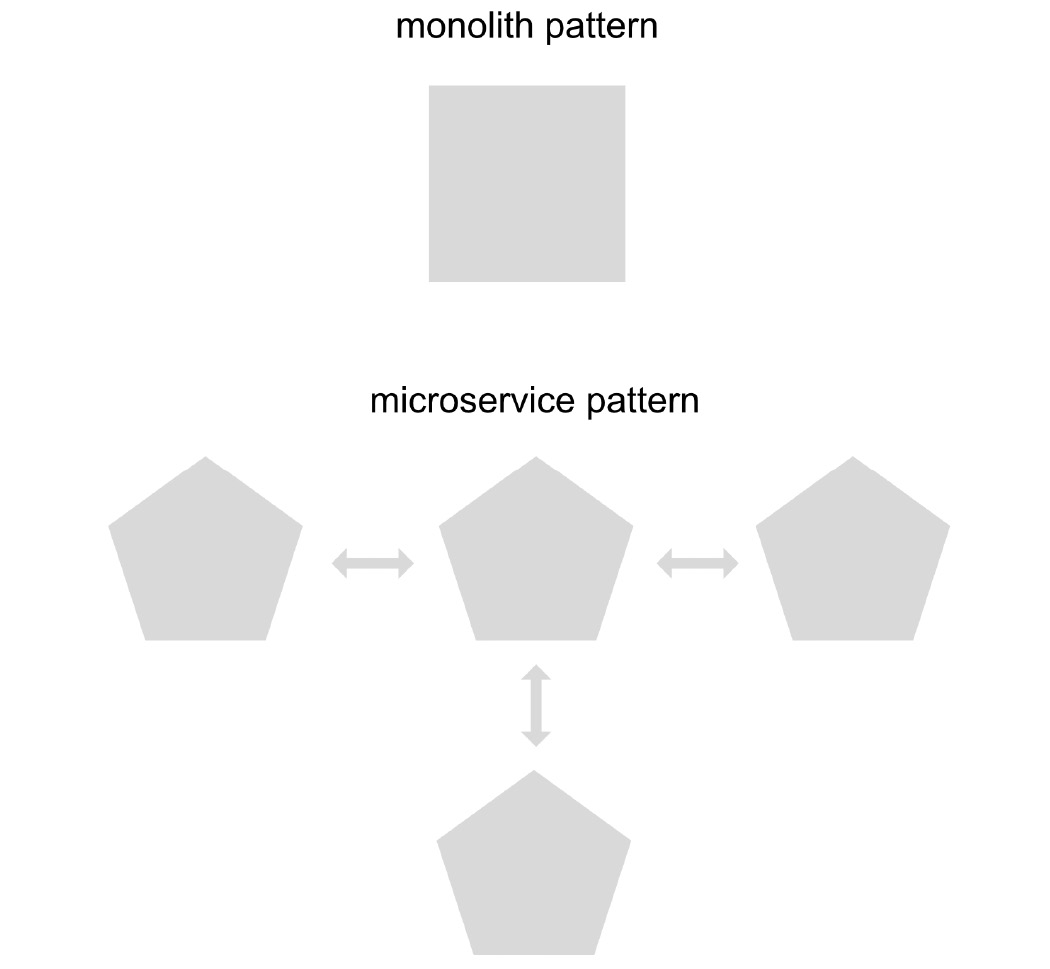
Figure 1.3 – Monolith versus microservice pattern
Handling user sessions and the importance of stateless applications in the autoscaling world
Probably, if you are a developer who comes from an old-school background, you will be familiar with managing user sessions on the server side. For a long time, this was how you knew whether or not a user was already authenticated in an application, consulting the server for this information. These types of applications are called stateful.
With the advent of the cloud and the ease of being able to create and destroy instances, horizontal autoscaling became very popular, but it also brought with it a big problem for applications that already existed and were based on querying the server status.
Horizontal scaling consists of the ability to create and destroy instances of our application to deal with high demand at peak times. One example of a trigger for horizontal scaling could be the number of calls received in a specific period of time.
Stateful applications don't work well using horizontal scaling because in this kind of application, the state information is stored in the instance itself, leaving all the other instances inside the horizontal scaling group without the state information. One example of this is when a user with a user session created and stored in one instance of the application accesses another instance of the group without the information from this user session.
To solve this problem, we can use access tokens, which enable session information to be maintained by the user, not by the server. Applications that store state information outside the instance itself are called stateless.
When a user logs in for the first time, an access token is generated, which is signed by an authorizing entity with a private key (which is only stored in that server or instance) and is verified in each of the other instances or servers with a public key, to verify that the access token has been effectively generated by our application and not by a third party:
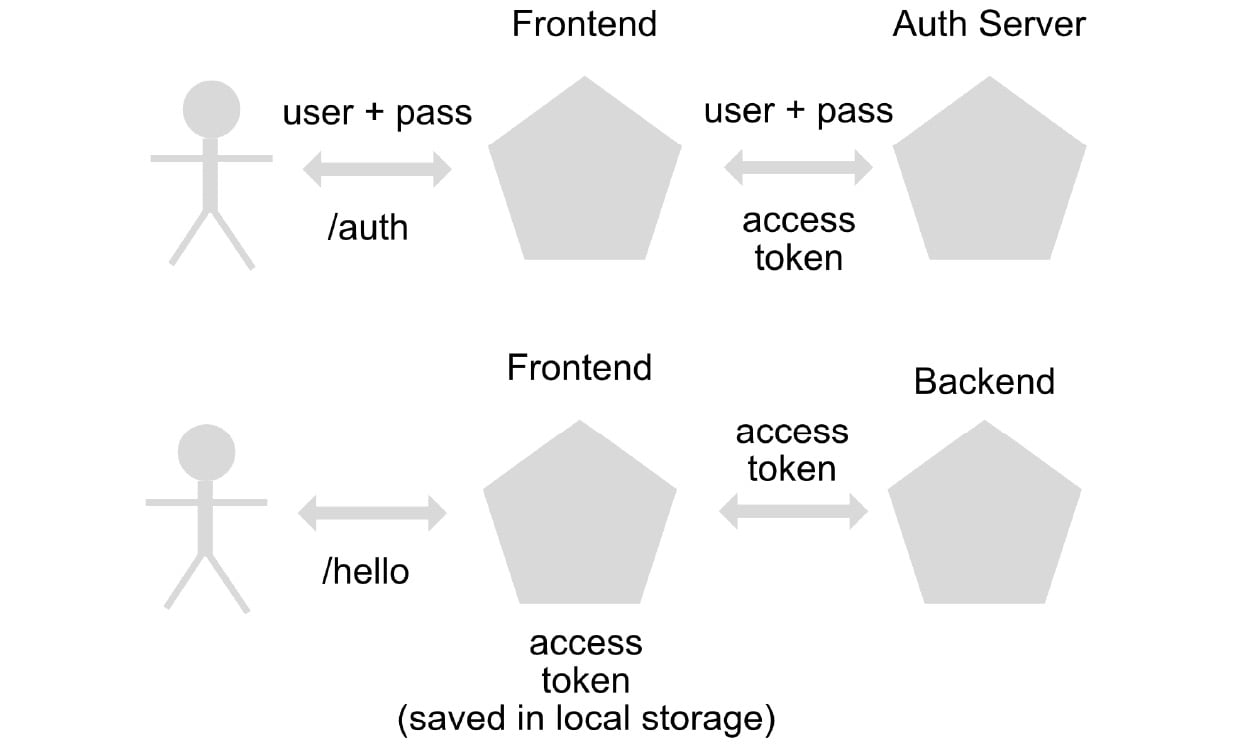
Figure 1.4 – Authentication flow
There are also access tokens of the JSON Web Token (JWT) type, which, in addition to having information about the signature of the token, can contain non-sensitive information such as the user's name, email, and roles, among other things.
In conclusion, although there are still applications that maintain their states based on the server, if an application requires horizontal scaling capabilities, it is necessary to adopt an authentication strategy using access tokens that are stored on the client side, using a stateless application solution.
Application logging, your best friend in error troubleshooting
Before the advent of microservices, there were only monolithic applications, in which the complete solution was kept in a single instance. This allowed application debugging and troubleshooting to be much simpler, since all the logs were stored in one place.
With the advent of microservices, solutions stopped relying on just one instance and this began to make debugging and troubleshooting activities more complex.
Now we need to be able to stream the logs generated by the various microservices to a centralized logging service in order to analyze all the information in one place, transforming our application to stateless.
We need also to revise the way in which logs are generated in our applications to facilitate debugging.
Now the logs have to not only indicate whether or not an error existed, but also somehow allow the generation of a trace from whichever service the call was initiated because an error now depends not only on a single instance but also on multiple actions executed on different servers.
Among the most common solutions to address these problems is the addition of custom headers to each of the calls that are generated between microservices, resulting in the traceability of the origin of the system and unique event codes:
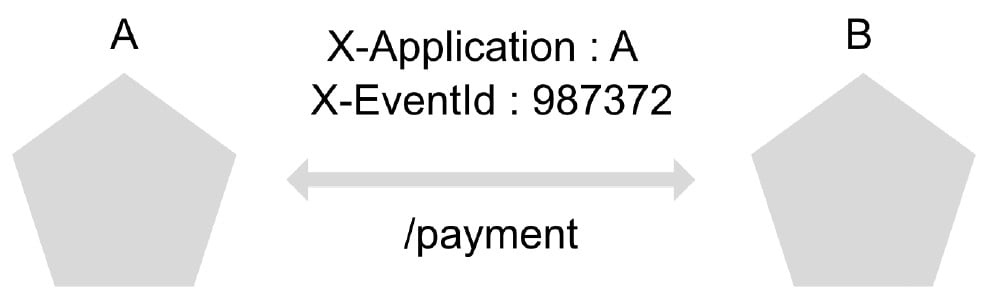
Figure 1.5 – Trace example
These options are an excellent element in microservices ecosystems to facilitate both the debugging and troubleshooting of applications.
Why should your microservices handle retries?
In any computer system, anything can fail and that is why our application has to be prepared to control these errors. In the world of microservices, this problem is even greater since, unlike an application built with the monolithic pattern, where all communications are generated in the same instance, each of the calls between microservices can fail. This makes it necessary to implement retry policies and error handling in each of the calls that are made.
When retrying a call to a microservice, there are some important factors to consider, such as the number of times we are going to retry the call and how long to wait between each retry.
In addition, it is necessary to allow the microservice to recover in the event that it is not available due to call saturation. In this case, the truncated exponential backoff strategy is used, which consists of increasing the time between each of the retry calls to the microservice in order to allow its recovery, with a maximum upper limit of growth of the time between calls.
Some service mesh solutions (a dedicated layer to handle service-to-service communications) such as Istio come with automatic retry functionality, so there is no need to code the retry logic. However, if your microservices ecosystem does not have a service mesh solution, you can use one of the available open source libraries, depending on which programming language you are using.
Understanding that service-to-service communication can sometimes fail, you should always consider implementing retries in applications that work with microservices ecosystems, along with the truncated exponential backoff algorithm, to make your solutions more reliable.
How to handle high traffic with autoscaling
Before the arrival of the cloud, it was necessary, when starting a computer project, to first evaluate the resources that would be required before buying the server on which the application would live. The problem with this was, and still is, that estimating the resources needed to run an application is very complex. Real load tests are generally necessary to effectively understand how many resources an application will use.
Furthermore, once the server was purchased, the resources could not be changed, meaning that in the event of an error in the initial estimate, or some increase in traffic due to a special event such as Cyber Day, the application could not obtain more resources. The result could be a bad experience for users and lost sales.
This is why most of the applications that are still deployed on on-premises servers have problems when high-traffic events arise. However, thanks to the arrival of the cloud, and the ease of creating and destroying instances, we have the arrival of autoscaling.
Autoscaling is the ability of an application under a load balancer to scale its instances horizontally depending on a particular metric. Among the most common metrics to manage autoscaling in an application are the number of calls made to the application and the percentage of CPU and RAM usage:
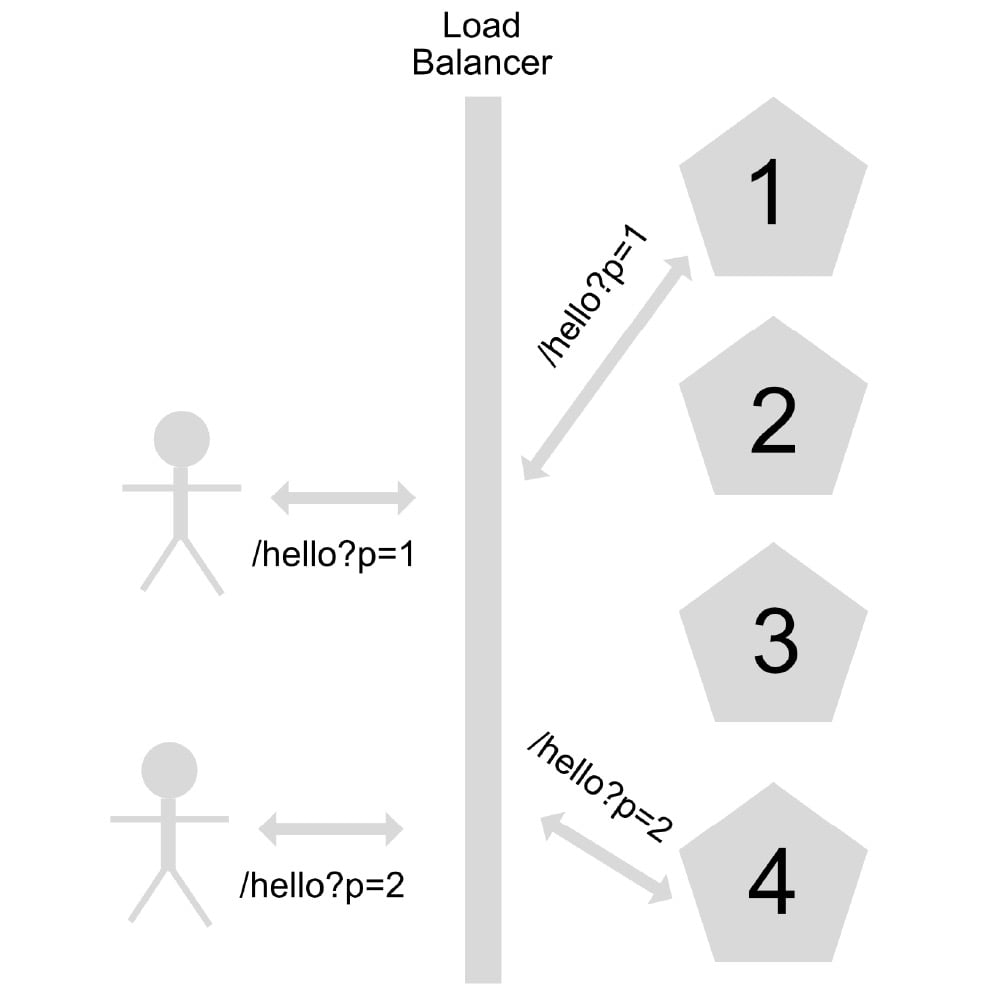
Figure 1.6 – Scaling out or horizontal scaling
For applications implemented in services of the IaaS or CaaS type, it is necessary to consider, for the correct management of the applications' autoscaling, the warm-up and cool-down time, in addition to application health checks.
Warm-up is the time it takes for the application to be available to receive post-deployment calls. This time must be configured to avoid an application receiving calls when it is not yet available.
Cool-down is the period of time where the rules defined in the autoscaling metrics are ignored. This configuration helps avoid the unwanted creation and destruction of instances due to short variations in defined metrics such as CPU, memory, and user concurrency calls.
For example, if you have a 60-second cool-down configuration, all the metrics received in that period of time, after the creation of new instances, will not be considered to trigger the autoscaling policy. If you don't have a cool-down configuration, the autoscaling policy could trigger the creation of new instances before the warm-up of the application in those first created instances, generating the unwanted triggering of the autoscaling policy.
The health check is a status verification used for determining whether a service is available to receive calls (it is related to warming up) so that the load balancer has the possibility of sending traffic only to instances that are able to receive traffic at that time.
For applications implemented as serverless-type services, no special configuration is required, since they support the ability to auto-scale automatically.
Depending on the services supported by the cloud provider you use to implement your application, it may be necessary to perform additional configuration steps to correctly control autoscaling policies.
Avoiding overload caching your data
Although it is possible to control an increase in traffic by autoscaling the application, this action is not free, since it means both the temporary creation of new instances to be able to support this load and, in the case of serverless services, an increase in costs for each call made.
To reduce costs and also increase the performance of the calls made, it is therefore necessary to use a data caching strategy:
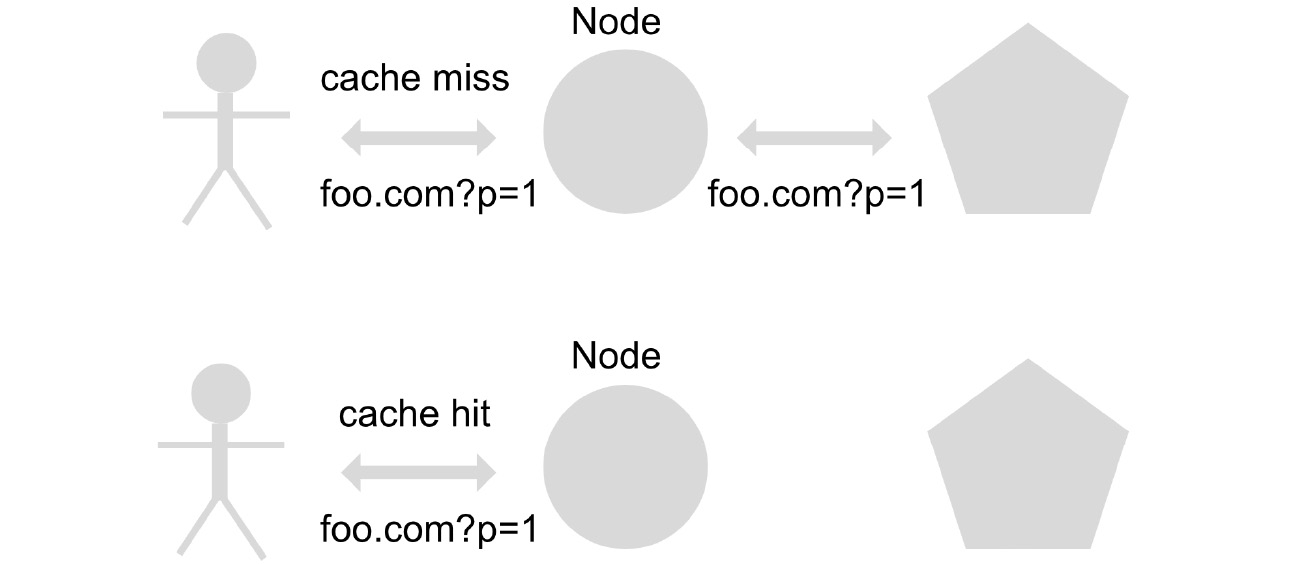
Figure 1.7 – Caching example
Implementing a caching strategy consists of saving in a database, in memory, queries that are made recurrently (using a key that corresponds to the query). To see whether a user returns to make a query that was made previously, it is saved in the database and thus there is no need to re-process the request, thereby reducing both response times and costs.
The first thing to do before implementing a caching strategy is to evaluate whether the scenario allows this strategy to be implemented. For this, it is necessary to identify the frequency with which changes are made to the data source that the application service consults. If the data change frequency of the source is 0 or very low, this is the ideal scenario to implement a caching strategy. Otherwise, if the data change frequency of the source is very high, it is recommended not to implement this caching strategy since the user could get outdated data.
Depending on the frequency with which the data changes in the source, it will be necessary to configure the lifetime of the cache. This is to avoid the data in the cache becoming outdated relative to the data in the source due to modification of the source, in which case users would get outdated information.
This strategy allows us to optimize our application to achieve better use of resources, increase responsiveness for users, and reduce the costs associated with both the use of resources and money for serverless solutions.
Loosely coupled microservices with topics
When designing a microservices architecture, it is important to ensure that calls made between each of the applications are reliable. This means that the information sent between microservices has retry policies and is not lost in cases of failure. It is also important to design the application solution so that if a microservice needs to be replaced, this does not affect the other microservices. This concept is known as loose coupling.
To implement a loosely coupled strategy, and also to ensure that messages sent between microservices are not lost due to communication failures or micro-cuts, there are messaging services.
In GCP, we have a messaging service based on the publisher/subscriber pattern called Pub/Sub, where the publisher makes a publication of the message to be sent to a topic, and the subscriber subscribes to a topic in order to obtain this message. There are also two types of subscriptions: pull-type subscriptions, in which the subscriber must constantly consult the topic if there is a new message, and push-type subscriptions, where the subscriber receives a notification with the message through an HTTP call:

Figure 1.8 – Loosely coupled microservices
In a loosely coupled ecosystem of microservices, each microservice should publish its calls using messages on a topic, and the microservices that are interested in receiving these calls as messages must subscribe. In Pub/Sub, upon receiving a message, the subscriber must inform the topic with an ACK, or acknowledge, code to inform the topic that the message was received correctly. If the subscriber cannot receive or process the message correctly, the topic will resend the message to the subscriber for up to 7 days in order to ensure delivery.
Each microservice that acts as a subscriber must have the ability to filter duplicate messages and execute tasks idempotently, which means having the ability to identify whether a message has already been delivered previously, so as not to process it in a duplicate way.
The use of messaging services in microservices ecosystems allows us to have robust solution designs, loosely coupled and tolerant of communication errors.







