






















































Markov decision processes
In this part of the chapter, we'll get familiar with the theoretical foundation of RL, which makes it possible to start moving toward the methods used to solve the RL problem. This section is important to understand the rest of the book and will ensure that you familiarize yourself with RL. First, we introduce you to the mathematical representation and notation of formalisms (reward, agent, actions, observations, and environment) we just discussed. Second, using this basis, we introduce you to the second-order notions of the RL language including state, episode, history, value, and gain, which will be used repeatedly to describe different methods later in the book. Finally, our description of Markov decision processes is built like a Russian matryoshka doll: we start from the simplest case of a Markov Process (MP) (also known as a Markov chain), then extend it with rewards, which will turn it into a Markov reward processes. Then we'll put this idea into one other extra envelope by adding actions, which will lead us to Markov Decision Processes (MDPs).
Markov processes and Markov decision processes are widely used in computer science and other engineering fields. So reading this chapter will be useful for you not only in RL contexts but also for a much wider range of topics.
If you're already familiar with MDPs, then you can quickly skim this chapter, paying attention only to the terminology definitions, as we'll use them later on.
Markov process
Let's start with the simplest child of the Markov family: the Markov process, also known as a Markov chain. Imagine that you have some system in front of you that you can only observe. What you observe is called states, and the system can switch between states according to some laws of dynamics. Again, you cannot influence the system, but only watch the states changing.
All possible states for a system form a set called state space. In Markov processes, we require this set of states to be finite (but it can be extremely large to compensate this limitation). Your observations form a sequence of states or a chain (that's why Markov processes are also called Markov chains). For example, looking at the simplest model of the weather in some city, we can observe the current day as sunny or rainy, which is our state space. A sequence of observations over time forms a chain of states, such as [sunny, sunny, rainy, sunny, …], and is called history.
To call such a system a MP, it needs to fulfil the Markov property, which means that the future system dynamics from any state have to depend on this state only. The main point of the Markov property is to make every observable state self-contained to describe the future of the system. In other words, the Markov property requires the states of the system to be distinguishable from each other and unique. In this case, only one state is required to model the future dynamics of the system, not the whole history or, say, the last N states.
In the case of our toy weather example, the Markov property limits our model to represent only the cases when a sunny day can be followed by a rainy one, with the same probability, regardless of the amount of sunny days we've seen in the past. It's not a very realistic model, as from common sense we know that the chance of rain tomorrow depends not only on the current condition, but on a large number of other factors, such as the season, our latitude, and the presence of mountains and sea nearby. It was recently proven that even solar activity has a major influence on weather. So, our example is really naïve, but it's important to understand the limitations and make conscious decisions about them.
Of course, if we want to make our model more complex, we can always do this by extending our state space, which will allow us to capture more dependencies in the model at the cost of a larger state space. For example, if you want to capture separately the probability of rainy days during summer and winter, then you can include the season in your state. In this case, your state space will be [sunny+summer, sunny+winter, rainy+summer, rainy+winter] and so on.
As your system model complies with the Markov property, you can capture transition probabilities with a transition matrix, which is a square matrix of the size N×N, where N is the number of states in our model. Every cell in a row i and a column j in the matrix contains the probability of the system to transition from the state i to state j.
For example, in our sunny/rainy example the transition matrix could be as follows:
|
sunny |
rainy | |
|
sunny |
0.8 |
0.2 |
|
rainy |
0.1 |
0.9 |
In this case, if we have a sunny day, then there is an 80% chance that the next day will be sunny and a 20% chance that the next day will be rainy. If we observe a rainy day, then there is a 10% probability that the weather will become better and a 90% probability of the next day being rainy.
So, that's it. The formal definition of Markov process is as follows:
- A set of states (S) that a system can be in
- A transition matrix (T), with transition probabilities, which defines the system dynamics
The useful visual representation of MP is a graph with nodes corresponding to system states and edges, labeled with probabilities representing a possible transition from state to state. If the probability of transition is 0, we don't draw an edge (there is no way to go from one state to another). This kind of representation is also widely used in finite state machine representation, which is studied in the automata theory. For our sunny/rainy weather model the graph is as shown here:
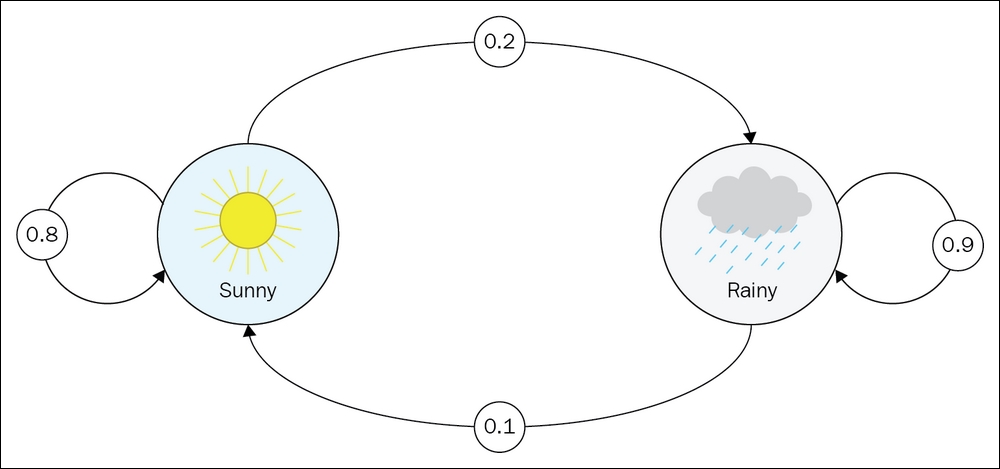
Figure 4: Sunny/Rainy weather model
Again, now we're talking about observation only. There is no way for us to influence the weather, so we just observe and record our observations.
To give you a more complicated example, we'll consider another model of Office Worker (Dilbert, the main character in Scott Adams' famous cartoons, is a good example). His state space in our example has the following states:
- Home: He's not at the office
- Computer: He's working on his computer at the office
- Coffee: He's drinking coffee at the office
- Chatting: He's discussing something with colleagues at the office
The state transition graph looks like this:
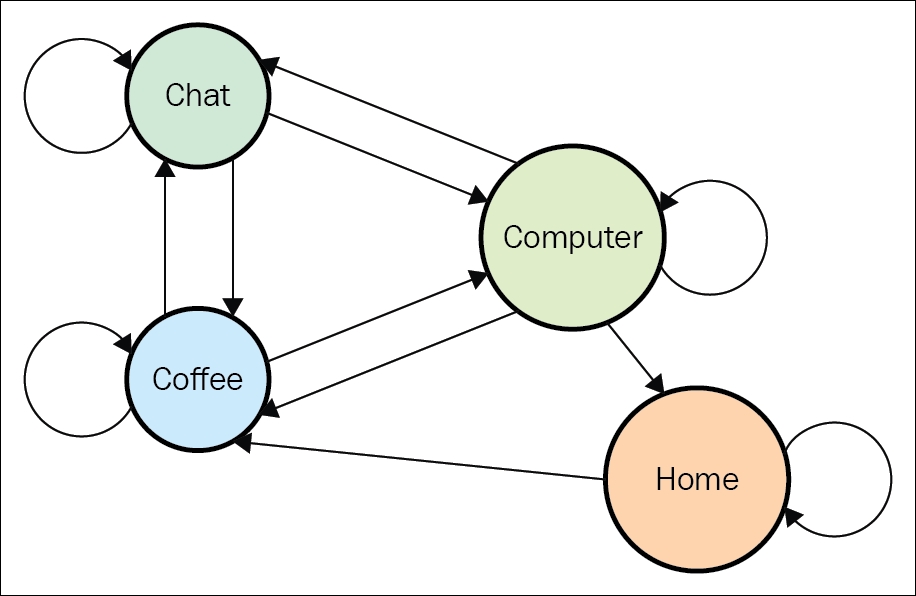
Figure 5: State transition graph
We expect that his work day usually starts from the Home state and that he always starts his work day with Coffee, without exception (no Home → Computer edge and no Home → Chatting edge). The preceding diagram also shows that work days always end (that is, the going to the Home state) from the Computer state. The transition matrix for the preceding diagram is as follows:
|
Home |
Coffee |
Chat |
Computer | |
|
Home |
60% |
40% |
0% |
0% |
|
Coffee |
0% |
10% |
70% |
20% |
|
Chat |
0% |
20% |
50% |
30% |
|
Computer |
20% |
20% |
10% |
50% |
The transition probabilities could be placed directly on the state transition graph, as shown here:
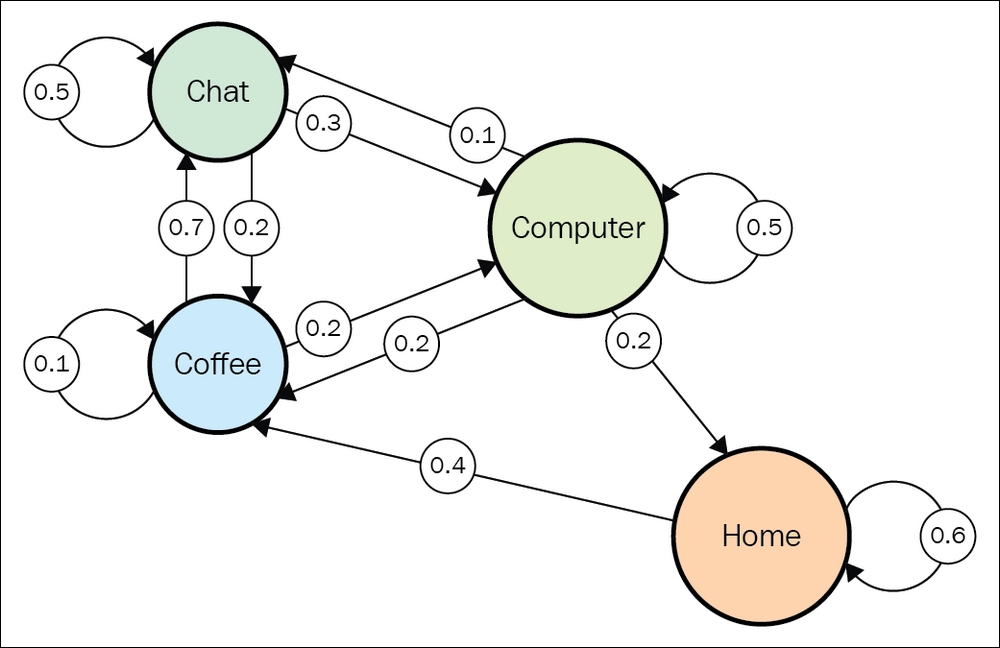
Figure 6: State transition graph with transition probabilities
In practice, we rarely have the luxury of knowing the exact transition matrix. A much more real-world situation is when we have only observations of our systems' states, which are also called episodes:
- home → coffee → coffee → chat → chat → coffee → computer → computer → home
- computer → computer → chat → chat → coffee → computer → computer → computer
- home → home → coffee → chat → computer → coffee → coffee
It's not complicated to estimate the transition matrix by our observation; we just count all the transitions from every state and normalize them to a sum of 1. The more observation data we have, the closer our estimation will be to the true underlying model.
It's also worth noting that the Markov property implies stationarity (that is, the underlying transition distribution for any state does not change over time). Nonstationarity means that there is some hidden factor that influences our system dynamics, and this factor is not included in observations. However, this contradicts the Markov property, which requires the underlying probability distribution to be the same for the same state regardless of the transition history. It's important to understand the difference between the actual transitions observed in an episode and the underlying distribution given in the transition matrix. Concrete episodes that we observe are randomly sampled from the distribution of the model, so they can differ from episode to episode. However, the probability of concrete transition to be sampled remains the same. If this is not the case, Markov chain formalism becomes nonapplicable.
Now we can go further and extend the Markov process model to make it closer to our RL problems. Let's add rewards to the picture!
Markov reward process
To introduce rewards, we need to extend our Markov process model a bit. First, we need to add value to our transition from state to state. We already have probability, but probability is being used to capture the dynamics of the system, so now we have an extra scalar number without an extra burden.
Reward can be represented in various forms. The most general way is to have another square matrix similar to the transition matrix with rewards for transitioning from state i to state j residing in row i and column j. Rewards can be positive or negative, large or small—it's just a number. In some cases, this representation is redundant and can be simplified. For example, if the reward is given for reaching the state regardless of the previous state, we can keep only state → reward pairs, which is a more compact representation. However, this is applicable only if the reward value depends only on the target state, which is not always the case.
The second thing we're adding to the model is discount factor γ (gamma), a single number from 0 to 1 (inclusive). The meaning will be explained later, after we define the extra characteristics of our Markov reward process.
As you remember, we observe a chain of state transitions in a Markov process. This is still the case for a Markov reward process, but for every transition, we have our extra quantity—reward. So now, all our observations have a reward value attached to every transition of the system.
For every episode, we define return at the time t as this quantity: 
Let's try to understand what this means. For every time point, we calculate return as a sum of subsequent rewards, but more distant rewards are multiplied by the discount factor raised to the power of the number of steps we are away from the starting point at time t. The discount factor stands for the foresightedness of an agent. If gamma equals to 1, then return Gt just equals a sum of all subsequent rewards and corresponds to the agent with perfect visibility of any subsequent rewards. If gamma equals 0, our return Gt will be just immediate reward without any subsequent state and correspond to absolute short-sightedness.
These extreme values are not useful, and usually gamma is set to something in between, such as 0.9 or 0.99. In this case, we will look into future rewards, but not too far.
This gamma parameter is important in RL, and we'll meet it a lot in the subsequent chapters. For now, think about it as a measure of how far into the future we look to estimate the future return: the closer to 1, the more steps ahead of us we take into account.
This return quantity is not very useful in practice, as it was defined for every specific chain we observed from our Markov reward process, so it can vary widely even for the same state. However, if we go to the extremes and calculate the mathematical expectation of return for any state (by averaging large amount of chains), we'll get a much more useful quantity, called a value of state:
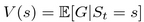
This interpretation is simple: for every state s, the value v (s) is the average (or expected) return we get by following the Markov reward process.
To show how this theoretical stuff is related to practice, let's extend our Dilbert process with rewards and turn it into a Dilbert Reward Process (DRP). Our reward values will be as follows:
- home → home: 1 (as it's good to be home)
- home → coffee: 1
- computer → computer: 5 (working hard is a good thing)
- computer → chat: -3 (it's not good to be distracted)
- chat → computer: 2
- computer → coffee: 1
- coffee → computer: 3
- coffee → coffee: 1
- coffee → chat: 2
- chat → coffee: 1
- chat → chat: -1 (long conversation becomes boring)
A diagram with rewards is shown here:
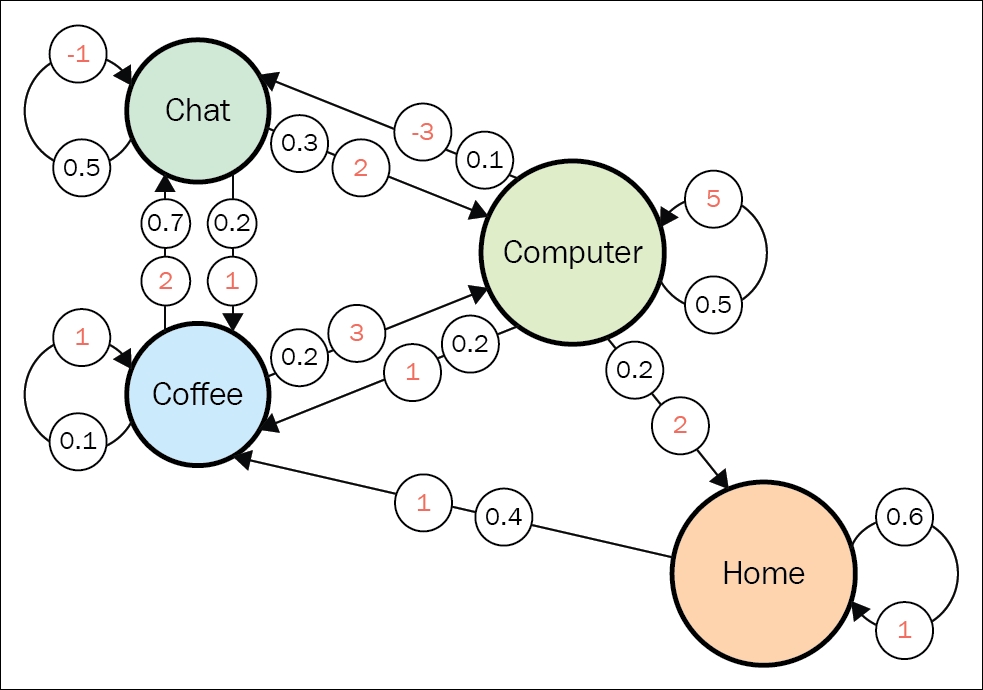
Figure 7: State transition graph with transition probabilities (dark) and rewards (light)
Let's return to our gamma parameter and think about the values of states with different values of gamma. We will start with a simple case: gamma = 0. How do you calculate the values of states here?
To answer this question, let's fix our state to Chat. What could the subsequent transition be? The answer is: It depends on chance. According to our transition matrix for the Dilbert process, there is a 50% probability that the next state will be Chat again, 20% that it will be Coffee, and in 30% of cases, we return to the Computer state. When gamma = 0, our return is equal only to a value of the next immediate state. So, if we want to calculate the value of the Chat state, then we need to sum all transition values, and multiply it by their probabilities:
V(chat) = -1 * 0.5 + 2 * 0.3 + 1 * 0.2 = 0.3
V(coffee) = 2 * 0.7 + 1 * 0.1 + 3 * 0.2 = 2.1
V(home) = 1 * 0.6 + 1 * 0.4 = 1.0
V(computer) = 5 * 0.5 + (-3) * 0.1 + 1 * 0.2 + 2 * 0.2 = 2.8
So, Computer is the most valuable state to be in (if we care only about immediate reward), which is not surprising as Computer → Computer is frequent, has a large reward, and the ratio of interruptions is not too high.
Now a trickier question: what's the value when gamma = 1? Think about this carefully.
The answer is: the value is infinite for all states. Our diagram doesn't contain sink states (states without outgoing transitions), and when our discount equals 1, we care about a potentially infinite amount of transitions in the future. As we've seen in the case of gamma = 0, all our values are positive in the short term, so the sum of the infinite amount of positive values will give us an infinite value, regardless of the starting state.
This infinite result shows us one of the reasons to introduce gamma into a Markov reward process, instead of just summing all future rewards. In most cases, the process can have an infinite (or large) amount of transitions. As it is not very practical to deal with infinite values, we would like to limit the horizon we calculate values for. Gamma with a value less than 1 provides such a limitation, and we'll discuss this later in chapters about the value iteration methods family. On the other hand, if you're dealing with finite-horizon environments (for example, the TicTacToe game which is limited by at most 9 steps), then it will be fine to use gamma = 1. As another example, there is an important class of environments with only one step called Multi-Armed Bandit MDP. This means that on every step you need to make a selection of one alternative action, which provides you with some reward and the episode ends.
As I already said about the Markov reward process definition, gamma is usually set to a value between 0 and 1 (commonly used values for gamma are 0.9 and 0.99); however, with such values it becomes almost impossible to calculate accurately the values by hand, even for MRPs as small as our Dilbert example, because it will require summing of hundreds of values. Computers are good at tedious tasks such as summing thousands of numbers, and there are several simple methods which can quickly calculate values for MRPs, given transition and reward matrices. We'll see and even implement one such method in Chapter 5, Tabular Learning and the Bellman Equation, when we'll start looking at Q-learning methods.
For now, let's put another layer of complexity around our Markov reward processes and introduce the final missing piece: actions.
Markov decision process
You may already have ideas about how to extend our MRP to include actions into the picture. First, we must add a set of actions (A), which has to be finite. This is our agent's action space.
Then, we need to condition our transition matrix with action, which basically means our matrix needs an extra action dimension, which turns it into a cube. If you remember, in the case of MPs and MRPs, the transition matrix had a square form, with source state in rows and target state in columns. So, every row i contained a list of probabilities to jump to every state:
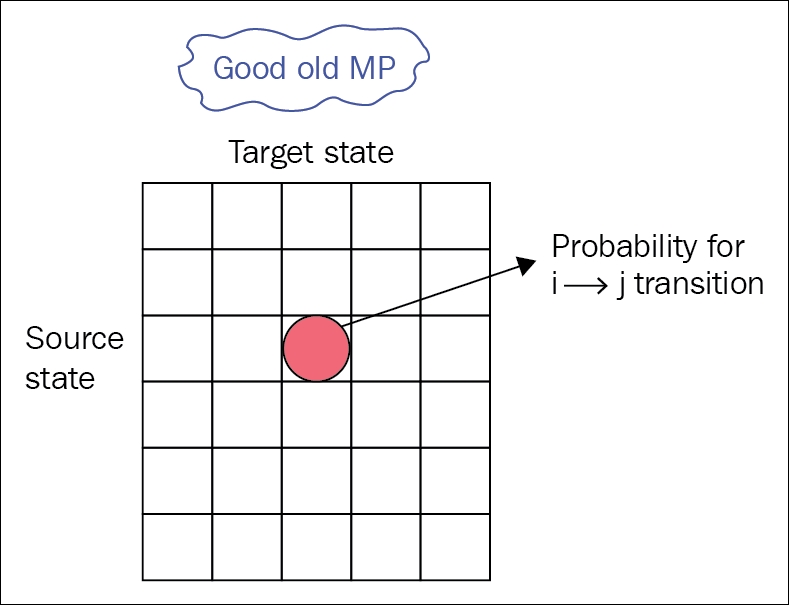
Figure 8: Transition matrix
Now the agent no longer passively observes state transitions, but can actively choose an action to take at every time. So, for every state, we don't have a list of numbers, but a matrix, where the depth dimension contains actions that the agent can take, and the other dimension is that the target state system will jump to after this action is performed by the agent. The following diagram shows our new transition table that became a cube with source state as the height dimension (indexed by i), target state as width (j), and action the agent can choose from is depth (k) of the transition table:
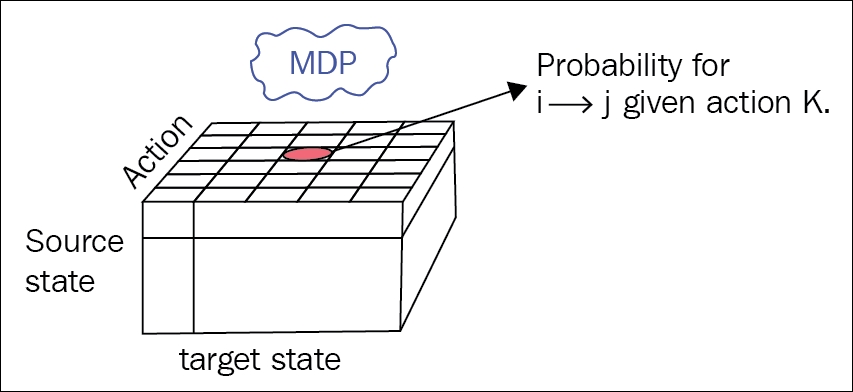
Figure 9: Transition probabilities for MDP
So, in general, by choosing an action, the agent can affect the probabilities of target states, which is a useful ability.
To give you an idea of why we need so many complications, let's imagine a small robot which lives in a 3 × 3 grid and can execute the actions turn left, turn right, and go forward. The state of the world is the robot's position plus orientation (up, down, left, and right), which gives us 3 × 3 × 4 = 36 states (the robot can be at any location in any orientation).
Also, imagine that the robot has imperfect motors (which is frequently the case in the real world), and when it executes turn left or turn right, there is a 90% chance that the desired turn happens, but sometimes, with 10% probability, the wheel slips and the robot's position stays the same. The same happens with go forward: in 90% of cases it works, but for the rest (10%) the robot stays at the same position.
In the following illustration, a small part of a transition diagram is shown, displaying the possible transitions from the state (1, 1, up), when the robot is in the center of the grid and facing up. If it tries to move forward, there is a 90% chance that it will end up in the state (0, 1, up), but there is a 10% probability that the wheels will slip and the target position will remain (1, 1, up).
To properly capture all these details about the environment and possible reactions on the agent's actions, the general MDP has a 3D transition matrix with dimensions (source state, action, and target state).
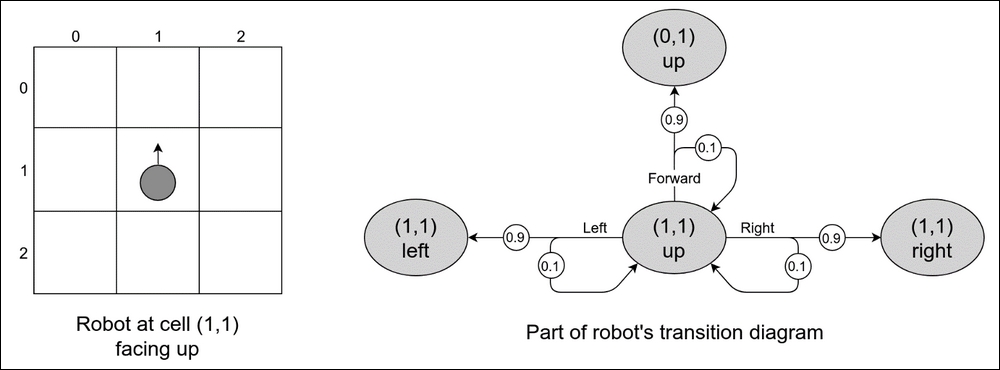
Figure 10: Grid world environment
Finally, to turn our MRP into an MDP, we need to add actions to our reward matrix in the same way we did with the transition matrix: our reward matrix will depend not only on state but also on action. In other words, it means that the reward the agent obtains now depends not only on the state it ends up in but also on the action that leads to this state. It's similar as when putting effort into something, you're usually gaining skills and knowledge, even if the result of your efforts wasn't too successful. So, the reward could be better if you're doing something, rather than not doing something, even if the final result is the same.
Now, with a formally defined MDP, we're finally ready to introduce the most important central thing for MDPs and RL: policy.
The intuitive definition of policy is that it is some set of rules that controls the agent's behavior. Even for fairly simple environments, we can have a variety of policies. For example, in the preceding example with the robot in the grid world, the agent can have different policies, which will lead to different sets of visited states. For example, this robot can perform the following actions:
- Blindly move forward regardless of anything
- Try to go around obstacles by checking whether that previous forward action failed
- Funnily spin around to entertain its creator
- Choose an action randomly modelling a drunk robot in the grid world scenario, and so on …
You may remember that the main objective of the agent in RL is to gather as much return (which was defined as discounted cumulative reward) as possible. So, again, intuitively, different policies can give us different return, which makes it important to find a good policy. This is why the notion of policy is important, and it's the central thing we're looking for.
Formally, policy is defined as the probability distribution over actions for every possible state:
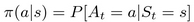
This is defined as probability, not as a concrete action, to introduce randomness into an agent's behavior. We'll talk later why this is important and useful. Finally, deterministic policy is a special case of probabilistics with needed action having 1 as its probability.
Another useful notion is that if our policy is fixed and not changing, then our MDP becomes an MRP, as we can reduce transition and reward matrices with a policy's probabilities and get rid of action dimensions.
So, my congratulations on getting to this stage! This chapter was challenging, but it was important for subsequent practical material. After two more introductory chapters about OpenAI gym and deep learning, we can finally start tackling the question: how do I teach agents to solve practical tasks?



