






















































What makes PyTorch Lightning so special?
So, if you are a novice data scientist, the question on your mind would be this: Which DL framework should I start with? And if you are curious about PyTorch Lightning, then you may well be asking yourself: Why should I learn this rather than something else? On the other hand, if you are an expert data scientist who has been building DL models for some time, then you will already be familiar with other popular frameworks such as TensorFlow, Keras, and PyTorch. The question then becomes: If you are already working in this area, why switch to a new framework? Is it worth making the effort to learn something different when you already know another tool? These are fair questions, and we will try to answer all of them in this section.
Let's start with a brief history of DL frameworks to establish where PyTorch Lightning fits in this context.
The first one….
The first DL model was executed in 1993 in Massachusetts Institute of Technology (MIT) labs by the godfather of DL, Yann LeCun. This was written in Lisp and, believe it or not, it even contained convolutional layers, just as with modern Convolutional Neural Network (CNN) models. The network shown in this demo is described in his Neural Information Processing Systems (NIPS) 1989 paper entitled Handwritten digit recognition with a backpropagation network.
The following screenshot shows an extract from this demo:

Figure 1.1 – MIT demo of handwritten digit recognition by Yann LeCun in 1993
Yann LeCun himself described in detail what this first model is in his blog post and this is shown in the following video: https://www.youtube.com/watch?v=FwFduRA_L6Q.
As you might have guessed, writing entire CNNs in C wasn't very easy. It took their team years of manual coding effort to achieve this.
The next big breakthrough in DL came in 2012, with the creation of AlexNet, which won the ImageNet competition. The AlexNet paper by Geoffrey Hinton et al. is considered the most influential paper, with the largest ever number of citations in the community. AlexNet set a precedent in terms of accuracy, made neural networks cool again, and was a massive network trained on optimized Graphics Processing Units (GPUs). They also introduced numerous kickass things, like BatchNorm, MaxPool, Dropout, SoftMax, and ReLU, which we will see later in our journey. With network architectures so complicated and massive, there was soon a requirement for a dedicated framework to train them.
So many frameworks?
Theano, Caffe, and Torch can be described as the first wave of DL frameworks that helped data scientists create DL models. While Lua was the preferred option for some as a programming language (Torch was first written in Lua as LuaTorch), many others were C++-based and could help train a model on distributed hardware such as GPUs and manage the optimization process. It was mostly used by ML researchers (typically post-doc) in academia when the field itself was new and unstable. A data scientist was expected to know how to write optimization functions with gradient descent code and make it run on specific hardware while also manipulating memory. Clearly, it was not something that someone in the industry could easily use to train models and take them into production.
Some examples of model-training frameworks are shown here:
Figure 1.2 – Model-training frameworks
TensorFlow, by Google, became a game-changer in this space by reverting to a Python-based, abstract function-driven framework that a non-researcher could use to experiment with while shielding them from the complexities around running DL code on hardware. Its success was followed by Keras, which simplified DL even further so that anyone with a little knowledge could train a DL model in just four lines of code.
But arguably, TensorFlow didn't parallelize well. It was also harder for it to train effectively in distributed GPU environments, hence the community felt a need for a new framework—something that combined the power of a research-based framework with the ease of Python. And PyTorch was born! This framework has taken the ML world by storm since its debut.
PyTorch versus TensorFlow
Looking on Google Trends at the competition between PyTorch and TensorFlow, you could say that PyTorch has taken over from TensorFlow in recent years and has almost surpassed it.
An extract from Google Trends can be seen here:
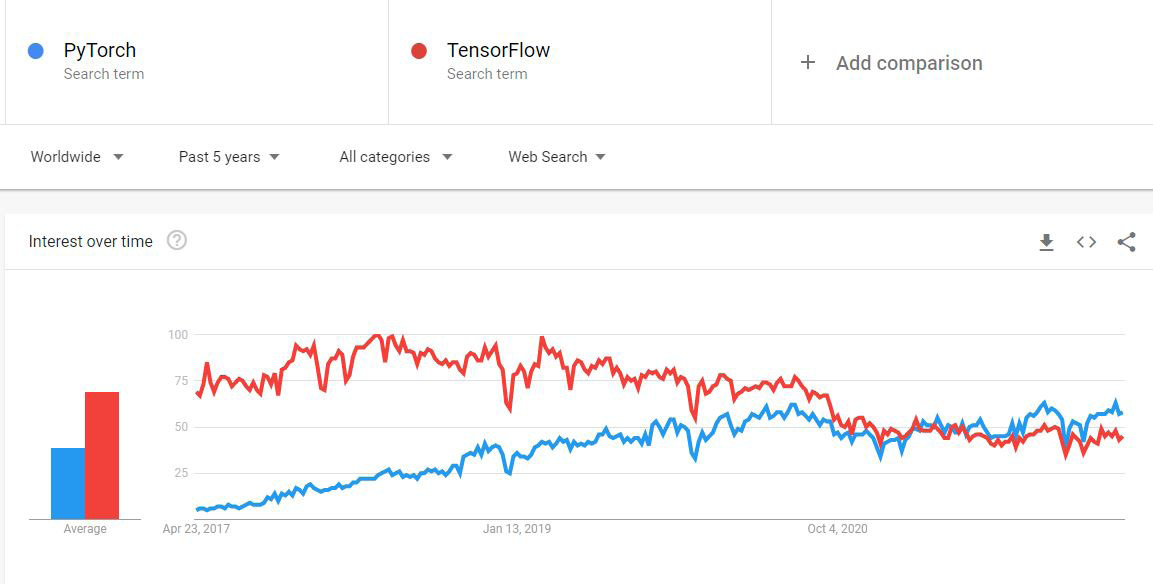
Figure 1.3 – Changes in community interest in PyTorch versus TensorFlow in Google Trends
While some may say that Google Trends is not the most scientific way to judge the pulse of the ML community, you can also look at many influential AI players with massive workloads—such as Facebook, Tesla, and Uber—defaulting to the PyTorch framework to manage their DL workloads and finding significant savings in compute and memory.
In ML research community though, the choice between Tensorflow and PyTorch is quite clear. The winner is hands-down PyTorch!

Figure 1.4 – TensorFlow vs PyTorch trends in top AI conferences for papers published
Both frameworks will have their die-hard fans, but PyTorch is reputed to be more efficient in distributed GPU environments given its inherent architecture. Here are a few other things that make PyTorch better than TensorFlow:
- Provides more stability.
- Easy-to-build extensions and wrappers.
- Much more comprehensive domain libraries.
- Static graph representations in TensorFlow weren't very helpful. It wasn't feasible to train networks easily.
- Dynamic Tensors in PyTorch were a game-changer that made it easy to train and scale.
A golden mean – PyTorch Lightning
Rarely do I come across something that I find as exciting as PyTorch Lightning! This framework is a brainchild of William Falcon whose PhD advisor is (guess who)..Yann LeCun! Here's what makes it stand out:
- It's not just cool to code, but it also allows you to do serious ML research (unlike Keras).
- It has better GPU utilization (compared with TensorFlow).
- It has 16-bit precision support (very useful for platforms that don't support Tensor Processing Units (TPUs), such as IBM Cloud).
- It also has a really good collection of state-of-the-art (SOTA) model repositories in the form of Lightning Flash.
- It is the first framework with native capability and Self-Supervised Learning (SSL).
In a nutshell, PyTorch Lightning makes it fun and cool to make DL models and to perform quick experiments, all while not dumbing down the core data science aspect by abstracting it from data scientists, and always leaving a door open to go deep into PyTorch whenever you want to!
I guess it strikes the perfect balance by allowing more capability to do Data Science while automating most of the "engineering" part. Is this the beginning of the end for TensorFlow? For the answer to that question, we will have to wait and see.


