






















































Chapter 6: Foundations of GRUs
Activity 7: Develop a sentiment classification model using Simple RNN
Solution:
- Load the dataset.
from keras.datasets import imdb
max_features = 10000
maxlen = 500
(train_data, y_train), (test_data, y_test) = imdb.load_data(num_words=max_features)
print('Number of train sequences: ', len(train_data))
print('Number of test sequences: ', len(test_data))
- Pad sequences so that each sequence has the same number characters.
from keras.preprocessing import sequence
train_data = sequence.pad_sequences(train_data, maxlen=maxlen)
test_data = sequence.pad_sequences(test_data, maxlen=maxlen)
- Define and compile model using SimpleRNN with 32 hidden units.
from keras.models import Sequential
from keras.layers import Embedding
from keras.layers import Dense
from keras.layers import GRU
from keras.layers import SimpleRNN
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_data, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
- Plot the validation and training accuracy and losses.
import matplotlib.pyplot as plt
def plot_results(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training Accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation Accuracy')
plt.title('Training and validation Accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation Loss')
plt.legend()
plt.show()
- Plot the model
plot_results(history)
The output is as follows:
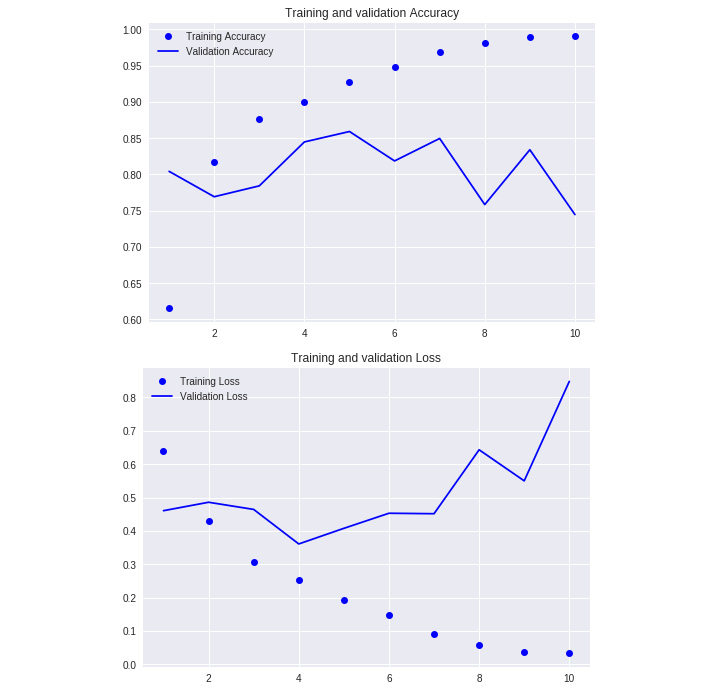
Figure 6.29: Training and validation accuracy loss
Activity 8: Train your own character generation model with a dataset of your choice
Solution:
- Load the text file and import the necessary Python packages and classes.
import sys
import random
import string
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM, GRU
from keras.optimizers import RMSprop
from keras.models import load_model
# load text
def load_text(filename):
with open(filename, 'r') as f:
text = f.read()
return text
in_filename = 'drive/shakespeare_poems.txt' # Add your own text file here
text = load_text(in_filename)
print(text[:200])
The output is as follows:

Figure 6.30: Sonnets from Shakespeare
- Create dictionaries mapping characters to indices and vice-versa.
chars = sorted(list(set(text)))
print('Number of distinct characters:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
The output is as follows:

Figure 6.31: Distinct character count
- Create sequences from the text.
max_len_chars = 40
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - max_len_chars, step):
sentences.append(text[i: i + max_len_chars])
next_chars.append(text[i + max_len_chars])
print('nb sequences:', len(sentences))
The output is as follows:

Figure 6.32: nb sequence count
- Make input and output arrays to feed the model.
x = np.zeros((len(sentences), max_len_chars, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
- Build and train the model using GRU and save the model.
print('Build model...')
model = Sequential()
model.add(GRU(128, input_shape=(max_len_chars, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
model.fit(x, y,batch_size=128,epochs=10)
model.save("poem_gen_model.h5")
- Define sampling and generation functions.
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
- Generate text.
from keras.models import load_model
model_loaded = load_model('poem_gen_model.h5')
def generate_poem(model, num_chars_to_generate=400):
start_index = random.randint(0, len(text) - max_len_chars - 1)
generated = ''
sentence = text[start_index: start_index + max_len_chars]
generated += sentence
print("Seed sentence: {}".format(generated))
for i in range(num_chars_to_generate):
x_pred = np.zeros((1, max_len_chars, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, 1)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
return generated
generate_poem(model_loaded, 100)
The output is as follows:




