






















































Train and Test Data
Once you've pre-processed your data into a format that's ready to be used by your model, you need to split up your data into train and test sets. This is because your machine learning algorithm will use the data in the training set to learn what it needs to know. It will then make a prediction about the data in the test set, using what it has learned. You can then compare this prediction against the actual target variables in the test set in order to see how accurate your model is. The exercise in the next section will give more clarity on this.
We will do the train/test split in proportions. The larger portion of the data split will be the train set and the smaller portion will be the test set. This will help to ensure that you are using enough data to accurately train your model.
In general, we carry out the train-test split with an 80:20 ratio, as per the Pareto principle. The Pareto principle states that "for many events, roughly 80% of the effects come from 20% of the causes." But if you have a large dataset, it really doesn't matter whether it's an 80:20 split or 90:10 or 60:40. (It can be better to use a smaller split set for the training set if our process is computationally intensive, but it might cause the problem of overfitting – this will be covered later in the book.)
Exercise 12: Splitting Data into Train and Test Sets
In this exercise, we will load the USA_Housing.csv dataset (which you saw earlier) into a pandas dataframe and perform a train/test split. Follow these steps to complete this exercise:
Note
The USA_Housing.csv dataset is available here: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/USA_Housing.csv.
- Open a Jupyter notebook and add a new cell to import pandas and load the dataset into pandas:
import pandas as pd
dataset = 'https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/USA_Housing.csv'
df = pd.read_csv(dataset, header=0)
- Create a variable called X to store the independent features. Use the drop() function to include all the features, leaving out the dependent or the target variable, which in this case is named Price. Then, print out the top five instances of the variable. Add the following code to do this:
X = df.drop('Price', axis=1)
X.head()
The preceding code generates the following output:
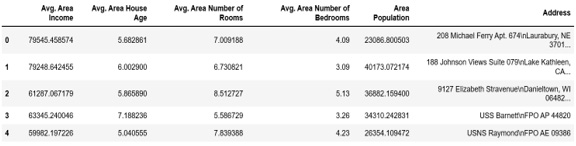
Figure 1.49: Dataframe consisting of independent variables
- Print the shape of your new created feature matrix using the X.shape command:
X.shape
The preceding code generates the following output:
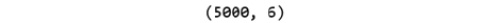
Figure 1.50: Shape of the X variable
In the preceding figure, the first value indicates the number of observations in the dataset (5000), and the second value represents the number of features (6).
- Similarly, we will create a variable called y that will store the target values. We will use indexing to grab the target column. Indexing allows us to access a section of a larger element. In this case, we want to grab the column named Price from the df dataframe and print out the top 10 values. Add the following code to implement this:
y = df['Price']
y.head(10)
The preceding code generates the following output:
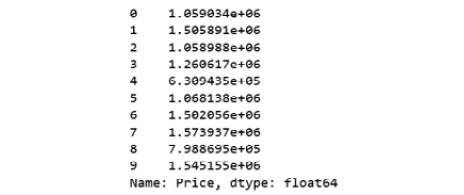
Figure 1.51: Top 10 values of the y variable
- Print the shape of your new variable using the y.shape command:
y.shape
The preceding code generates the following output:
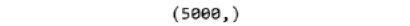
Figure 1.52: Shape of the y variable
The shape should be one-dimensional, with a length equal to the number of observations (5000).
- Make train/test sets with an 80:20 split. To do so, use the train_test_split() function from the sklearn.model_selection package. Add the following code to do this:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
In the preceding code, test_size is a floating-point value that defines the size of the test data. If the value is 0.2, then it is an 80:20 split. test_train_split splits the arrays or matrices into train and test subsets in a random way. Each time we run the code without random_state, we will get a different result.
- Print the shape of X_train, X_test, y_train, and y_test. Add the following code to do this:
print("X_train : ",X_train.shape)
print("X_test : ",X_test.shape)
print("y_train : ",y_train.shape)
print("y_test : ",y_test.shape)
The preceding code generates the following output:

Figure 1.53: Shape of train and test datasets
You have successfully split the data into train and test sets.
In the next section, you will complete an activity wherein you'll perform pre-processing on a dataset.
Activity 1: Pre-Processing Using the Bank Marketing Subscription Dataset
In this activity, we'll perform various pre-processing tasks on the Bank Marketing Subscription dataset. This dataset relates to the direct marketing campaigns of a Portuguese banking institution. Phone calls are made to market a new product, and the dataset records whether each customer subscribed to the product.
Follow these steps to complete this activity:
Note
The Bank Marketing Subscription dataset is available here: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Banking_Marketing.csv.
- Load the dataset from the link given into a pandas dataframe.
- Explore the features of the data by finding the number of rows and columns, listing all the columns, finding the basic statistics of all columns (you can use the describe().transpose() function), and listing the basic information of the columns (you can use the info() function).
- Check whether there are any missing (or NULL) values, and if there are, find how many missing values there are in each column.
- Remove any missing values.
- Print the frequency distribution of the education column.
- The education column of the dataset has many categories. Reduce the categories for better modeling.
- Select and perform a suitable encoding method for the data.
- Split the data into train and test sets. The target data is in the y column and the independent data is in the remaining columns. Split the data with 80% for the train set and 20% for the test set.
Note
The solution for this activity can be found on page 324.
Now that we've covered the various data pre-processing steps, let's look at the different types of machine learning that are available to data scientists in some more detail.





