






















































Chapter 7: Processing Human Language
Activity 19: Predicting Sentiments of Movie Reviews
Solution:
- Read the IMDB movie review dataset using pandas in Python:
import pandas as pd
data = pd.read_csv('../../chapter 7/data/movie_reviews.csv', encoding='latin-1')
- Convert the tweets to lowercase to reduce the number of unique words:
data.text = data.text.str.lower()
Note
Keep in mind that "Hello" and "hellow" are not the same to a computer.
- Clean the reviews using RegEx with the clean_str function:
import re
def clean_str(string):
string = re.sub(r"https?\://\S+", '', string)
string = re.sub(r'\<a href', ' ', string)
string = re.sub(r'&', '', string)
string = re.sub(r'<br />', ' ', string)
string = re.sub(r'[_"\-;%()|+&=*%.,!?:#$@\[\]/]', ' ', string)
string = re.sub('\d','', string)
string = re.sub(r"can\'t", "cannot", string)
string = re.sub(r"it\'s", "it is", string)
return string
data.SentimentText = data.SentimentText.apply(lambda x: clean_str(str(x)))
- Next, remove stop words and other frequently occurring unnecessary words from the reviews:
Note
To see how we found these, words refer to Exercise 51.
- This step converts strings into tokens (which will be helpful in the next step):
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize,sent_tokenize
stop_words = stopwords.words('english') + ['movie', 'film', 'time']
stop_words = set(stop_words)
remove_stop_words = lambda r: [[word for word in word_tokenize(sente) if word not in stop_words] for sente in sent_tokenize(r)]
data['SentimentText'] = data['SentimentText'].apply(remove_stop_words)
- Create the word embedding of the reviews with the tokens created in the previous step. Here, we will use genism Word2Vec to create these embedding vectors:
from gensim.models import Word2Vec
model = Word2Vec(
data['SentimentText'].apply(lambda x: x[0]),
iter=10,
size=16,
window=5,
min_count=5,
workers=10)
model.wv.save_word2vec_format('movie_embedding.txt', binary=False)
- Combine the tokens to get a string and then drop any review that does not have anything in it after stop word removal:
def combine_text(text):
try:
return ' '.join(text[0])
except:
return np.nan
data.SentimentText = data.SentimentText.apply(lambda x: combine_text(x))
data = data.dropna(how='any')
- Tokenize the reviews using the Keras Tokenizer and convert them into numbers:
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(list(data['SentimentText']))
sequences = tokenizer.texts_to_sequences(data['SentimentText'])
word_index = tokenizer.word_index
- Finally, pad the tweets to have a maximum of 100 words. This will remove any words after the 100-word limit and add 0s if the number of words is less than 100:
from keras.preprocessing.sequence import pad_sequences
reviews = pad_sequences(sequences, maxlen=100)
- Load the created embedding to get the embedding matrix using the load_embedding function discussed in the Text Processing section:
import numpy as np
def load_embedding(filename, word_index , num_words, embedding_dim):
embeddings_index = {}
file = open(filename, encoding="utf-8")
for line in file:
values = line.split()
word = values[0]
coef = np.asarray(values[1:])
embeddings_index[word] = coef
file.close()
embedding_matrix = np.zeros((num_words, embedding_dim))
for word, pos in word_index.items():
if pos >= num_words:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[pos] = embedding_vector
return embedding_matrix
embedding_matrix = load_embedding('movie_embedding.txt', word_index, len(word_index), 16)
- Convert the label into one-hot vector using pandas' get_dummies function and split the dataset into testing and training sets with an 80:20 split:
from sklearn.model_selection import train_test_split
labels = pd.get_dummies(data.Sentiment)
X_train, X_test, y_train, y_test = train_test_split(reviews,labels, test_size=0.2, random_state=9)
- Create the neural network model starting with the input and embedding layers. This layer converts the input words into their embedding vectors:
from keras.layers import Input, Dense, Dropout, BatchNormalization, Embedding, Flatten
from keras.models import Model
inp = Input((100,))
embedding_layer = Embedding(len(word_index),
16,
weights=[embedding_matrix],
input_length=100,
trainable=False)(inp)
- Create the rest of the fully connected neural network using Keras:
model = Flatten()(embedding_layer)
model = BatchNormalization()(model)
model = Dropout(0.10)(model)
model = Dense(units=1024, activation='relu')(model)
model = Dense(units=256, activation='relu')(model)
model = Dropout(0.5)(model)
predictions = Dense(units=2, activation='softmax')(model)
model = Model(inputs = inp, outputs = predictions)
- Compile and train the model for 10 epochs. You can modify the model and the hyperparameters to try and get a better accuracy:
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics = ['acc'])
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=10, batch_size=256)
- Calculate the accuracy of the model on the test set to see how well our model performs on previously unseen data by using the following:
from sklearn.metrics import accuracy_score
preds = model.predict(X_test)
accuracy_score(np.argmax(preds, 1), np.argmax(y_test.values, 1))
The accuracy of the model is:

Figure 7.39: Model accuracy
- Plot the confusion matrix of the model to get a proper sense of the model's prediction:
y_actual = pd.Series(np.argmax(y_test.values, axis=1), name='Actual')
y_pred = pd.Series(np.argmax(preds, axis=1), name='Predicted')
pd.crosstab(y_actual, y_pred, margins=True)
Check the following

Figure 7.40: Confusion matrix of the model (0 = negative sentiment, 1 = positive sentiment)
- Check the performance of the model by seeing the sentiment predictions on random reviews using the following code:
review_num = 111
print("Review: \n"+tokenizer.sequences_to_texts([X_test[review_num]])[0])
sentiment = "Positive" if np.argmax(preds[review_num]) else "Negative"
print("\nPredicted sentiment = "+ sentiment)
sentiment = "Positive" if np.argmax(y_test.values[review_num]) else "Negative"
print("\nActual sentiment = "+ sentiment)
Check that you receive the following output:
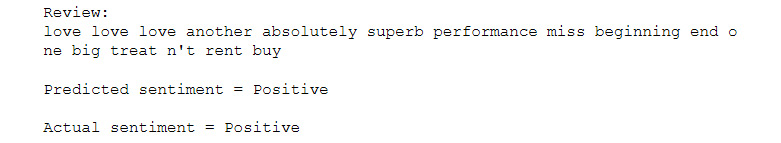
Figure 7.41: A review from the IMDB dataset
Activity 20: Predicting Sentiments from Tweets
Solution:
- Read the tweet dataset using pandas and rename the columns with those given in the following code:
import pandas as pd
data = pd.read_csv('tweet-data.csv', encoding='latin-1', header=None)
data.columns = ['sentiment', 'id', 'date', 'q', 'user', 'text']
- Drop the following columns as we won't be using them. You can analyze and use them if you want when trying to improve the accuracy:
data = data.drop(['id', 'date', 'q', 'user'], axis=1)
- We perform this activity only on a subset (400,000 tweets) of the data to save time. If you want, you can work on the whole dataset:
data = data.sample(400000).reset_index(drop=True)
- Convert the tweets to lowercase to reduce the number of unique words. Keep in mind that "Hello" and "hellow" are not the same to a computer:
data.text = data.text.str.lower()
- Clean the tweets using the clean_str function:
import re
def clean_str(string):
string = re.sub(r"https?\://\S+", '', string)
string = re.sub(r"@\w*\s", '', string)
string = re.sub(r'\<a href', ' ', string)
string = re.sub(r'&', '', string)
string = re.sub(r'<br />', ' ', string)
string = re.sub(r'[_"\-;%()|+&=*%.,!?:#$@\[\]/]', ' ', string)
string = re.sub('\d','', string)
return string
data.text = data.text.apply(lambda x: clean_str(str(x)))
- Remove all the stop words from the tweets, as was done in the Text Preprocessing section:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize,sent_tokenize
stop_words = stopwords.words('english')
stop_words = set(stop_words)
remove_stop_words = lambda r: [[word for word in word_tokenize(sente) if word not in stop_words] for sente in sent_tokenize(r)]
data['text'] = data['text'].apply(remove_stop_words)
def combine_text(text):
try:
return ' '.join(text[0])
except:
return np.nan
data.text = data.text.apply(lambda x: combine_text(x))
data = data.dropna(how='any')
- Tokenize the tweets and convert them to numbers using the Keras Tokenizer:
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(list(data['text']))
sequences = tokenizer.texts_to_sequences(data['text'])
word_index = tokenizer.word_index
- Finally, pad the tweets to have a maximum of 50 words. This will remove any words after the 50-word limit and add 0s if the number of words is less than 50:
from keras.preprocessing.sequence import pad_sequences
tweets = pad_sequences(sequences, maxlen=50)
- Create the embedding matrix from the GloVe embedding file that we downloaded using the load_embedding function:
import numpy as np
def load_embedding(filename, word_index , num_words, embedding_dim):
embeddings_index = {}
file = open(filename, encoding="utf-8")
for line in file:
values = line.split()
word = values[0]
coef = np.asarray(values[1:])
embeddings_index[word] = coef
file.close()
embedding_matrix = np.zeros((num_words, embedding_dim))
for word, pos in word_index.items():
if pos >= num_words:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[pos] = embedding_vector
return embedding_matrix
embedding_matrix = load_embedding('../../embedding/glove.twitter.27B.50d.txt', word_index, len(word_index), 50)
- Split the dataset into training and testing sets with an 80:20 spilt. You can experiment with different splits:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(tweets, pd.get_dummies(data.sentiment), test_size=0.2, random_state=9)
- Create the LSTM model that will predict the sentiment. You can modify this to create your own neural network:
from keras.models import Sequential
from keras.layers import Dense, Dropout, BatchNormalization, Embedding, Flatten, LSTM
embedding_layer = Embedding(len(word_index),
50,
weights=[embedding_matrix],
input_length=50,
trainable=False)
model = Sequential()
model.add(embedding_layer)
model.add(Dropout(0.5))
model.add(LSTM(100, dropout=0.2))
model.add(Dense(2, activation='softmax'))
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics = ['acc'])
- Train the model. Here, we train it only for 10 epochs. You can increase the number of epochs to try and get a better accuracy:
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=10, batch_size=256)
- Check how well the model is performing by predicting the sentiment of a few tweets in the test set:
preds = model.predict(X_test)
review_num = 1
print("Tweet: \n"+tokenizer.sequences_to_texts([X_test[review_num]])[0])
sentiment = "Positive" if np.argmax(preds[review_num]) else "Negative"
print("\nPredicted sentiment = "+ sentiment)
sentiment = "Positive" if np.argmax(y_test.values[review_num]) else "Negative"
print("\nActual sentiment = "+ sentiment)
The output is as follows:






