






















































When an application wants to run, the client launches the ApplicationMaster, which then negotiates with the ResourceManager to get resources in the cluster in the form of containers. A container represents CPUs (cores) and memory allocated on a single node to be used to run tasks and processes. Containers are supervised by the NodeManager and scheduled by the ResourceManager.
Examples of containers:
- One core and 4 GB RAM
- Two cores and 6 GB RAM
- Four cores and 20 GB RAM
Some containers are assigned to be mappers and others to be reducers; all this is coordinated by the ApplicationMaster in conjunction with the ResourceManager. This framework is called YARN:
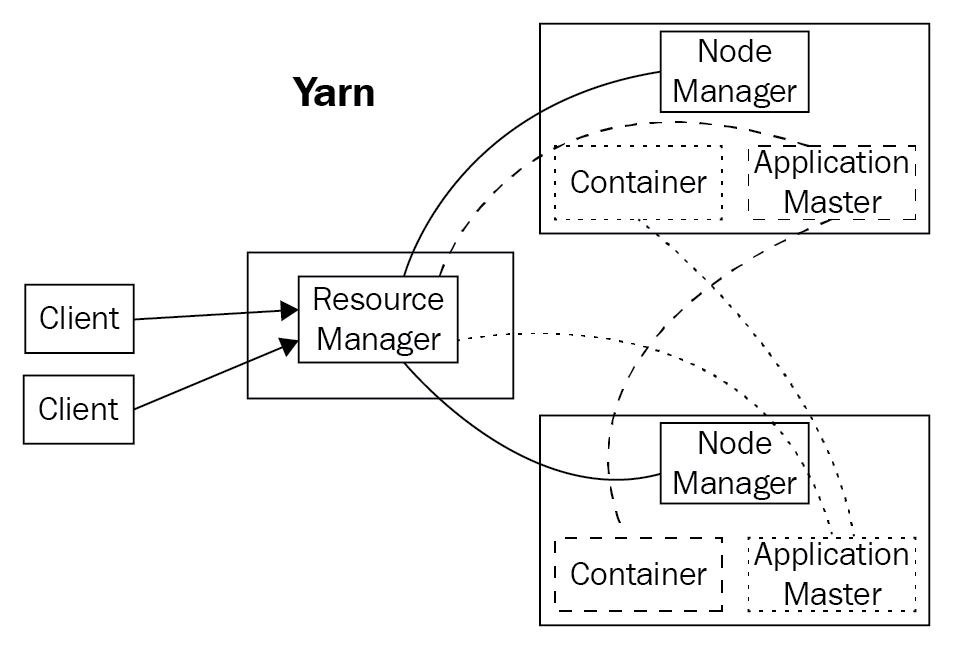
Using YARN, several different applications can request for and execute tasks on containers, sharing the cluster resources pretty well. However, as the size of the clusters grows and the variety of applications and requirements change, the efficiency of the resource utilization is not as good over time.






