






















































The Apache Hadoop is a collection of open source software that enables distributed storage and processing of large datasets across a cluster of different types of computer systems. The Apache Hadoop framework consists of the following four key modules:
- Apache Hadoop Common
- Apache Hadoop Distributed File System (HDFS)
- Apache Hadoop MapReduce
- Apache Hadoop YARN (Yet Another Resource Manager)
Each of these modules covers different capabilities of the Hadoop framework. The following diagram depicts their positioning in terms of applicability for Hadoop 3.X releases:
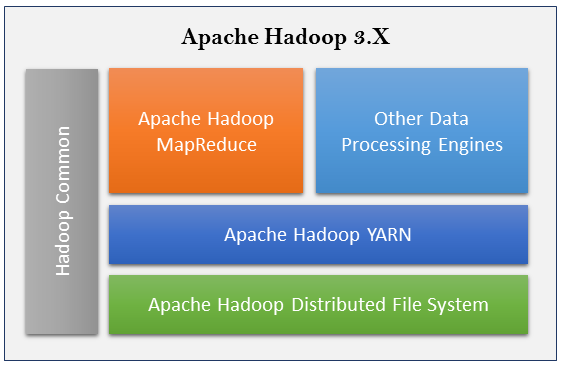
Apache Hadoop Common consists of shared libraries that are consumed across all other modules including key management, generic I/O packages, libraries for metric collection, and utilities for registry, security, and streaming. Apache HDFS provides highly tolerant distributed filesystem across clustered computers.
Apache Hadoop provides a distributed data processing framework for large datasets using a simple programming model called MapReduce. A programming task that is divided into multiple identical subtasks and that is distributed among multiple machines for processing is called a map task. The results of these map tasks are combined together into one or many reduce tasks. Overall, this approach of computing tasks is called the MapReduce Approach. The MapReduce programming paradigm forms the heart of the Apache Hadoop framework, and any application that is deployed on this framework must comply to MapReduce programming. Each task is divided into a mapper task, followed by a reducer task. The following diagram demonstrates how MapReduce uses the divide-and-conquer methodology to solve its complex problem using a simplified methodology:
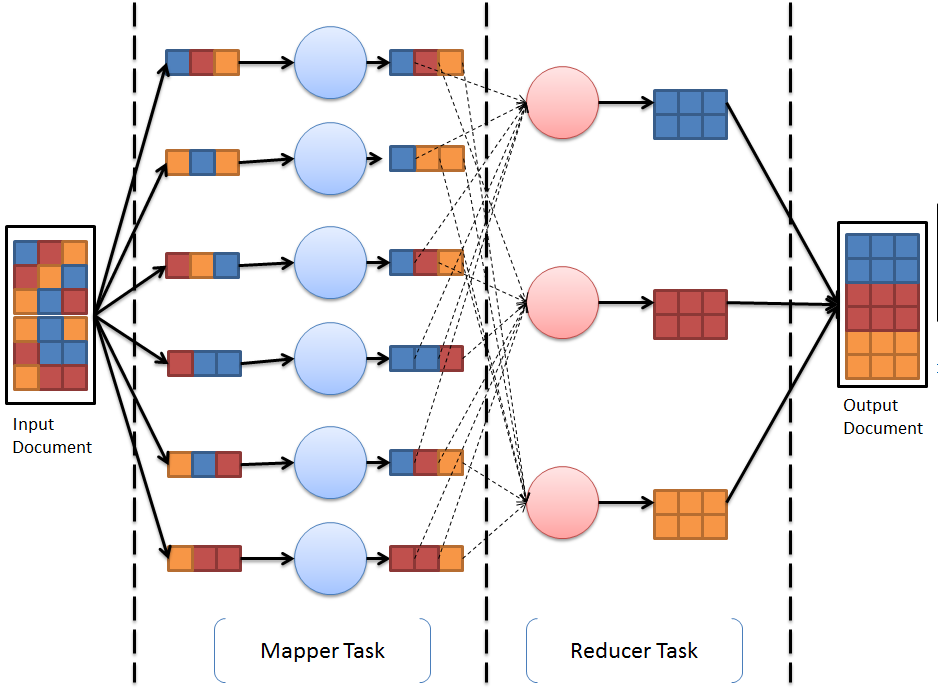
Apache Hadoop MapReduce provides a framework to write applications to process large amounts of data in parallel on Hadoop clusters in a reliable manner. The following diagram describes the placement of multiple layers of the Hadoop framework. Apache Hadoop YARN provides a new runtime for MapReduce (also called MapReduce 2) for running distributed applications across clusters. This module was introduced in Hadoop version 2 onward. We will be discussing these modules further in later chapters. Together, these components provide a base platform to build and compute applications from scratch. To speed up the overall application building experience and to provide efficient mechanisms for large data processing, storage, and analytics, the Apache Hadoop ecosystem comprises additional software. We will cover these in the last section of this chapter.
Now that we have given a quick overview of the Apache Hadoop framework, let's understand why Hadoop-based systems are needed in the real world.
Apache Hadoop was invented to solve large data problems that no existing system or commercial software could solve. With the help of Apache Hadoop, the data that used to get archived on tape backups or was lost is now being utilized in the system. This data offers immense opportunities to provide insights in history and to predict the best course of action. Hadoop is targeted to solve problems involving the four Vs (Volume, Variety, Velocity, and Veracity) of data. The following diagram shows key differentiators of why Apache Hadoop is useful for business:
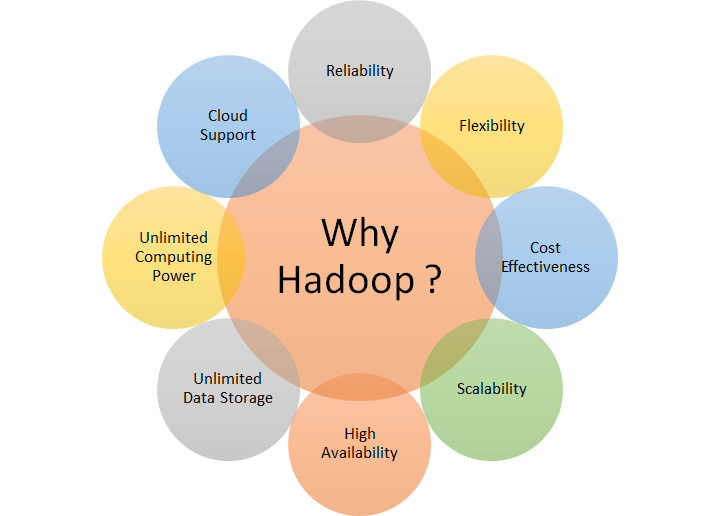
Let's go through each of the differentiators:
- Reliability: The Apache Hadoop distributed filesystem offers replication of data, with a default replication of 3x. This ensures that there is no data loss despite failure of cluster nodes.
- Flexibility: Most of the data that users today must deal with is unstructured. Traditionally, this data goes unnoticed; however, with Apache Hadoop, variety of data including structured and unstructured data can be processed, stored, and analyzed to make better future decisions. Hadoop offers complete flexibility to work across any type of data.
- Cost effectiveness: Apache Hadoop is completely open source; it comes for free. Unlike traditional software, it can run on any hardware or commodity systems and it does not require high-end servers; the overall investment and total cost of ownership of building a Hadoop cluster is much less than the traditional high-end system required to process data of the same scale.
- Scalability: Hadoop is a completely distributed system. With data growth, implementation of Hadoop clusters can add more nodes dynamically or even downsize them based on data processing and storage demands.
- High availability: With data replication and massively parallel computation running on multi-node commodity hardware, applications running on top of Hadoop provide high availability environment for all implementations.
- Unlimited storage space: Storage in Hadoop can scale up to petabytes of data storage with HDFS. HDFS can store any type of data of larger size in a completely distributed manner. This capability enables Hadoop to solve large data problems.
- Unlimited computing power: Hadoop 3.x onward supports more than 10,000 nodes of Hadoop clusters, whereas Hadoop 2.x supports up to 10,000 node clusters. With such a massive parallel processing capability, Apache Hadoop offers unlimited computing power to all applications.
- Cloud support: Today, almost all cloud providers support Hadoop directly as a service, which means a completely automated Hadoop setup is available on demand. It supports dynamic scaling too; overall it becomes an attractive model due to the reduced Total Cost of Ownership (TCO).
Now is the time to do a deep dive into how Apache Hadoop works.









