





















































Analyzing and predicting insurance severity claims
Predicting the cost, and hence the severity, of claims in an insurance company is a real-life problem that needs to be solved in a more accurate and automated way. We will do something similar in this example.
We will start with simple logistic regression and will learn how to improve the performance using some ensemble techniques, such as an random forest regressor. Then we will look at how to boost the performance with a gradient boosted regressor. Finally, we will show how to choose the best model and deploy it for a production-ready environment.
Motivation
When someone is devastated by a serious car accident, his focus is on his life, family, child, friends, and loved ones. However, once a file is submitted for the insurance claim, the overall paper-based process to calculate the severity claim is a tedious task to be completed.
This is why insurance companies are continually seeking fresh ideas to improve their claims service for their clients in an automated way. Therefore, predictive analytics is a viable solution to predicting the cost, and hence severity, of claims on the available and historical data.
Description of the dataset
A dataset from the Allstate Insurance companywill be used, which consists of more than 300,000 examples with masked and anonymous data and consisting of more than 100 categorical and numerical attributes, thus being compliant with confidentiality constraints, more than enough for building and evaluating a variety of ML techniques.
The dataset is downloaded from the Kaggle website at https://www.kaggle.com/c/allstate-claims-severity/data. Each row in the dataset represents an insurance claim. Now, the task is to predict the value for the loss column. Variables prefaced with cat are categorical, while those prefaced with cont are continuous.
It is to be noted that the Allstate Corporation is the second largest insurance company in the United States, founded in 1931. We are trying to make the whole thing automated, to predict the cost, and hence the severity, of accident and damage claims.
Exploratory analysis of the dataset
Let's look at some data properties (use the EDA.scala file for this). At first, we need to read the training set to see the available properties. To begin with, let's place your training set in your project directory or somewhere else and point to it accordingly:
val train = "data/insurance_train.csv"I hope you have Java, Scala and Spark installed and configured on your machine. If not, please do so. Anyway, I'm assuming they are. So let's create an active Spark session, which is the gateway for any Spark application:
val spark = SparkSessionCreate.createSession() import spark.implicits._
Note
Spark session alias on Scala REPL:
If you are inside Scala REPL, the Spark session alias spark is already defined, so just get going.
Here, I have a method called createSession() under the class SparkSessionCreate that goes as follows:
import org.apache.spark.sql.SparkSession object SparkSessionCreate { def createSession(): SparkSession = { val spark = SparkSession .builder .master("local[*]") // adjust accordingly .config("spark.sql.warehouse.dir", "E:/Exp/") //change accordingly .appName("MySparkSession") //change accordingly .getOrCreate() return spark } }
Since this will be used frequently throughout this book, I decided to create a dedicated method. So, let's load, parse, and create a DataFrame using the read.csv method but in Databricks .csv format (as known as com.databricks.spark.csv) since our dataset comes with .csv format.
At this point, I have to interrupt you to inform something very useful. Since we will be using Spark MLlib and ML APIs in upcoming chapters too. Therefore, it would be worth fixing some issues in prior. If you're a Windows user then let me tell you a very weired issue that you will be experiencing while working with Spark.
Well, the thing is that Spark works on Windows, Mac OS, and Linux. While using Eclipse or IntelliJ IDEA to develop your Spark applications (or through Spark local job sumit) on Windows, you might face an I/O exception error and consequently your application might not compile successfully or may be interrupted.
The reason is that Spark expects that there is a runtime environment for Hadoop on Windows. Unfortunately, the binary distribution of Spark (v2.2.0 for example) release does not contain some Windows native components (example, winutils.exe, hadoop.dll, and so on). However, these are required (not optional) to run Hadoop on Windows. Therefore, if you cannot ensure the runtime environment, an I/O exception saying the following:
24/01/2018 11:11:10 ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Now there are two ways to tackale this issue on Windows:
- From IDE such as Eclipse and IntelliJ IDEA: Download the
winutls.exefrom https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin/. Then download and copy it inside thebinfolder in the Spark distribution—example,spark-2.2.0-bin-hadoop2.7/bin/. Then select the project |Run Configurations...|Environment|New| create a variable namedHADOOP_HOMEand put the path in the value field—example,c:/spark-2.2.0-bin-hadoop2.7/bin/|OK|Apply|Run. Then you're done! - With local Sparkjob submit: Add the
winutils.exefile path to the hadoop home directory using System set properties—example, in the Spark codeSystem.setProperty("hadoop.home.dir", "c:\\\spark-2.2.0-bin-hadoop2.7\\\bin\winutils.exe")
Alright, let's come to your original discussion. If you see the preceding code block then we set to read the header of the CSV file, which is directly applied to the column names of the DataFrame created, and the inferSchema property is set to true. If you don't specify the inferSchema configuration explicitly, the float values will be treated as strings. This might cause VectorAssembler to raise an exception such as java.lang.IllegalArgumentException: Data type StringType is not supported:
val trainInput = spark.read
.option("header", "true")
.option("inferSchema", "true")
.format("com.databricks.spark.csv")
.load(train)
.cache Now let's print the schema of the DataFrame we just created. I have abridged the output and shown only a few columns:
Println(trainInput.printSchema()) root |-- id: integer (nullable = true) |-- cat1: string (nullable = true) |-- cat2: string (nullable = true) |-- cat3: string (nullable = true) ... |-- cat115: string (nullable = true) |-- cat116: string (nullable = true) ... |-- cont14: double (nullable = true) |-- loss: double (nullable = true)
You can see that there are 116 categorical columns for categorical features. Also, there are 14 numerical feature columns. Now let's see how many rows there are in the dataset using the count() method:
println(df.count())
>>> 188318
The preceding number is pretty high for training an ML model. Alright, now let's see a snapshot of the dataset using the show() method but with only some selected columns so that it makes more sense. Feel free to use df.show() to see all columns:
df.select("id", "cat1", "cat2", "cat3", "cont1", "cont2", "cont3", "loss").show()
>>> 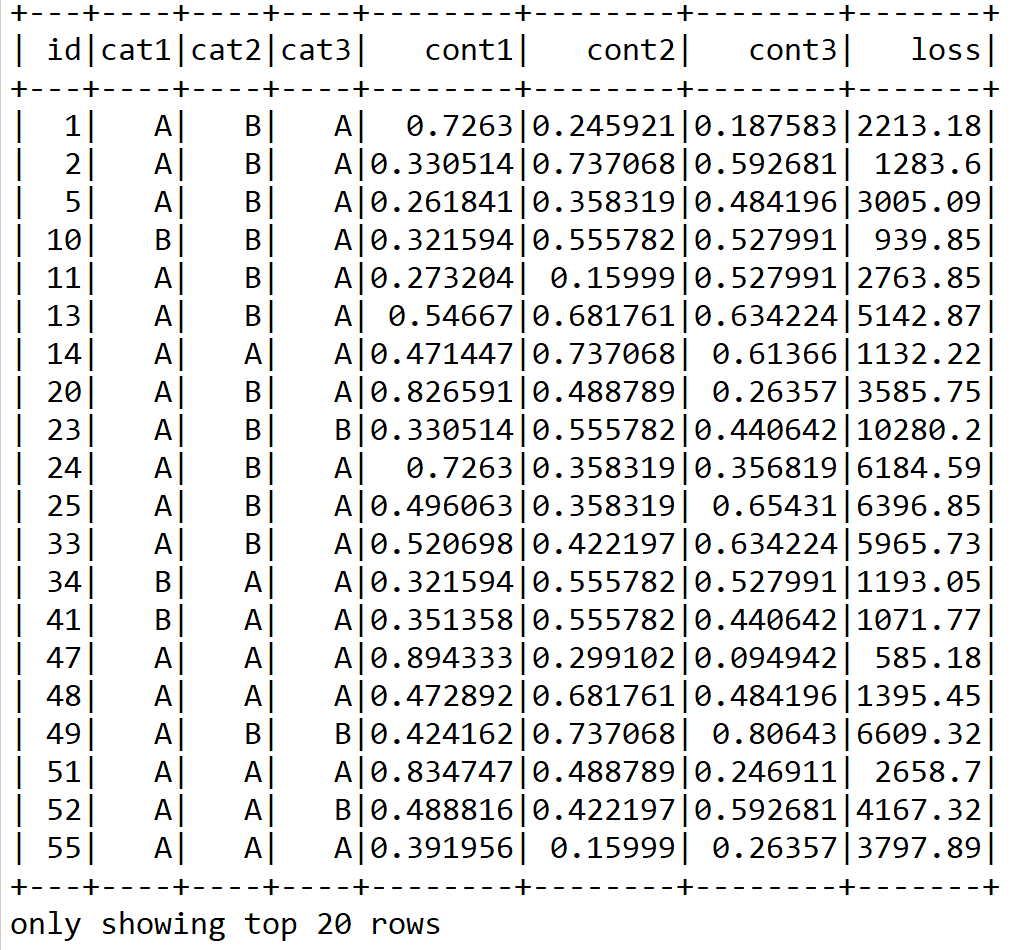
Nevertheless, if you look at all the rows using df.show(), you will see some categorical columns containing too many categories. To be more specific, category columns cat109 to cat116 contain too many categories, as follows:
df.select("cat109", "cat110", "cat112", "cat113", "cat116").show()
>>> 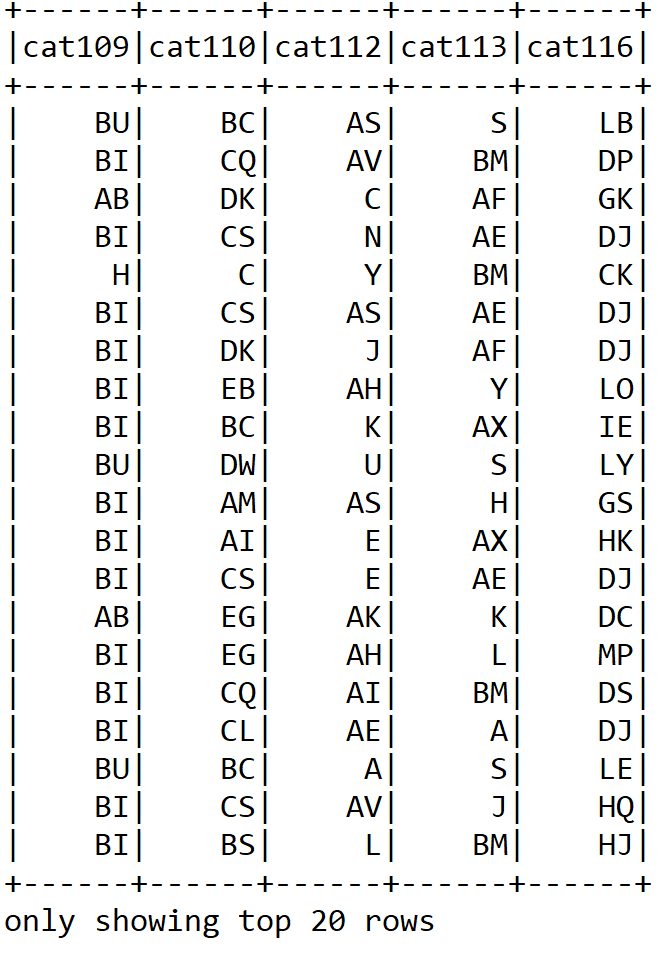
In later stages, it would be worth dropping these columns to remove the skewness in the dataset. It is to be noted that in statistics, skewnessis a measure of the asymmetry of the probability distribution of a real-valued random variable with respect to the mean.
Now that we have seen a snapshot of the dataset, it is worth seeing some other statistics such as average claim or loss, minimum, maximum loss, and many more, using Spark SQL. But before that, let's rename the last column from loss to label since the ML model will complain about it. Even after using the setLabelCol on the regression model, it still looks for a column called label. This results in a disgusting error saying org.apache.spark.sql.AnalysisException: cannot resolve 'label' given input columns:
val newDF = df.withColumnRenamed("loss", "label") Now, since we want to execute an SQL query, we need to create a temporary view so that the operation can be performed in-memory:
newDF.createOrReplaceTempView("insurance") Now let's average the damage claimed by the clients:
spark.sql("SELECT avg(insurance.label) as AVG_LOSS FROM insurance").show()
>>>
+------------------+
| AVG_LOSS |
+------------------+
|3037.3376856699924|
+------------------+Similarly, let's see the lowest claim made so far:
spark.sql("SELECT min(insurance.label) as MIN_LOSS FROM insurance").show()
>>>
+--------+
|MIN_LOSS|
+--------+
| 0.67|
+--------+And let's see the highest claim made so far:
spark.sql("SELECT max(insurance.label) as MAX_LOSS FROM insurance").show()
>>>
+---------+
| MAX_LOSS|
+---------+
|121012.25|
+---------+Since Scala or Java does not come with a handy visualization library, I could not something else but now let's focus on the data preprocessing before we prepare our training set.
Data preprocessing
Now that we have looked at some data properties, the next task is to do some preprocessing, such as cleaning, before getting the training set. For this part, use the Preprocessing.scala file. For this part, the following imports are required:
import org.apache.spark.ml.feature.{ StringIndexer, StringIndexerModel} import org.apache.spark.ml.feature.VectorAssembler
Then we load both the training and the test set as shown in the following code:
var trainSample = 1.0 var testSample = 1.0 val train = "data/insurance_train.csv" val test = "data/insurance_test.csv" val spark = SparkSessionCreate.createSession() import spark.implicits._ println("Reading data from " + train + " file") val trainInput = spark.read .option("header", "true") .option("inferSchema", "true") .format("com.databricks.spark.csv") .load(train) .cache val testInput = spark.read .option("header", "true") .option("inferSchema", "true") .format("com.databricks.spark.csv") .load(test) .cache
The next task is to prepare the training and test set for our ML model to be learned. In the preceding DataFrame out of the training dataset, we renamed the loss to label. Then the content of train.csv was split into training and (cross) validation data, 75% and 25%, respectively.
The content of test.csv is used for evaluating the ML model. Both original DataFrames are also sampled, which is particularly useful for running fast executions on your local machine:
println("Preparing data for training model")
var data = trainInput.withColumnRenamed("loss", "label").sample(false, trainSample) We also should do null checking. Here, I have used a naïve approach. The thing is that if the training DataFrame contains any null values, we completely drop those rows. This makes sense since a few rows out of 188,318 do no harm. However, feel free to adopt another approach such as null value imputation:
var DF = data.na.drop() if (data == DF) println("No null values in the DataFrame") else{ println("Null values exist in the DataFrame") data = DF } val seed = 12345L val splits = data.randomSplit(Array(0.75, 0.25), seed) val (trainingData, validationData) = (splits(0), splits(1))
Then we cache both the sets for faster in-memory access:
trainingData.cache validationData.cache
Additionally, we should perform the sampling of the test set that will be required in the evaluation step:
val testData = testInput.sample(false, testSample).cache Since the training set contains both the numerical and categorical values, we need to identify and treat them separately. First, let's identify only the categorical column:
def isCateg(c: String): Boolean = c.startsWith("cat") def categNewCol(c: String): String = if (isCateg(c)) s"idx_${c}" else c
Then, the following method is used to remove categorical columns with too many categories, which we already discussed in the preceding section:
def removeTooManyCategs(c: String): Boolean = !(c matches "cat(109$|110$|112$|113$|116$)")Now the following method is used to select only feature columns. So essentially, we should remove the ID (since the ID is just the identification number of the clients, it does not carry any non-trivial information) and the label column:
def onlyFeatureCols(c: String): Boolean = !(c matches "id|label") Well, so far we have treated some bad columns that are either trivial or not needed at all. Now the next task is to construct the definitive set of feature columns:
val featureCols = trainingData.columns
.filter(removeTooManyCategs)
.filter(onlyFeatureCols)
.map(categNewCol) Note
StringIndexer encodes a given string column of labels to a column of label indices. If the input column is numeric in nature, we cast it to string using the StringIndexer and index the string values. When downstream pipeline components such as Estimator or Transformer make use of this string-indexed label, you must set the input column of the component to this string-indexed column name. In many cases, you can set the input column with setInputCol.
Now we need to use the StringIndexer() for categorical columns:
val stringIndexerStages = trainingData.columns.filter(isCateg)
.map(c => new StringIndexer()
.setInputCol(c)
.setOutputCol(categNewCol(c))
.fit(trainInput.select(c).union(testInput.select(c)))) Note that this is not an efficient approach. An alternative approach would be using a OneHotEncoder estimator.
Note
OneHotEncoder maps a column of label indices to a column of binary vectors, with a single one-value at most. This encoding permits algorithms that expect continuous features, such as logistic regression, to utilize categorical features.
Now let's use the VectorAssembler() to transform a given list of columns into a single vector column:
val assembler = new VectorAssembler()
.setInputCols(featureCols)
.setOutputCol("features")Note
VectorAssembler is a transformer. It combines a given list of columns into a single vector column. It is useful for combining the raw features and features generated by different feature transformers into one feature vector, in order to train ML models such as logistic regression and decision trees.
That's all we need before we start training the regression models. First, we start training the LR model and evaluate the performance.



















