






















































Building hybrid adaptive RAG in Python
Let’s now start building the proof of concept of a hybrid adaptive RAG-driven generative AI configuration. Open Adaptive_RAG.ipynb on GitHub. We will focus on HF and, as such, will not use an existing framework. We will build our own pipeline and introduce HF.
As established earlier, the program is divided into three separate parts: the retriever, generator, and evaluator functions, which can be separate agents in a real-life project’s pipeline. Try to separate these functions from the start because, in a project, several teams might be working in parallel on separate aspects of the RAG framework.
The titles of each of the following sections correspond exactly to the names of each section in the program on GitHub. The retriever functionality comes first.
1. Retriever
We will first outline the initial steps required to set up the environment for a RAG-driven generative AI model. This process begins with the installation of essential software components and libraries that facilitate the retrieval and processing of data. We specifically cover the downloading of crucial files and the installation of packages needed for effective data retrieval and web scraping.
1.1. Installing the retriever’s environment
Let’s begin by downloading grequests.py from the commons directory of the GitHub repository. This repository contains resources that can be common to several programs in the repository, thus avoiding redundancy.
The download is standard and built around the request:
url = "https://raw.githubusercontent.com/Denis2054/RAG-Driven-Generative-AI/main/commons/grequests.py"
output_file = "grequests.py"
We will only need two packages for the retriever since we are building a RAG-driven generative AI model from scratch. We will install:
requests, the HTTP library to retrieve Wikipedia documents:!pip install requests==2.32.3beautifulsoup4, to scrape information from web pages:!pip install beautifulsoup4==4.12.3
We now need a dataset.
1.2.1. Preparing the dataset
For this proof of concept, we will retrieve Wikipedia documents by scraping them through their URLs. The dataset will contain automated or human-crafted labels for each document, which is the first step toward indexing the documents of a dataset:
import requests
from bs4 import BeautifulSoup
import re
# URLs of the Wikipedia articles mapped to keywords
urls = {
"prompt engineering": "https://en.wikipedia.org/wiki/Prompt_engineering",
"artificial intelligence":"https://en.wikipedia.org/wiki/Artificial_intelligence",
"llm": "https://en.wikipedia.org/wiki/Large_language_model",
"llms": "https://en.wikipedia.org/wiki/Large_language_model"
}
One or more labels precede each URL. This approach might be sufficient for a relatively small dataset.
For specific projects, including a proof of concept, this approach can provide a solid first step to go from naïve RAG (content search with keywords) to searching a dataset with indexes (the labels in this case). We now have to process the data.
1.2.2. Processing the data
We first apply a standard scraping and text-cleaning function to the document that will be retrieved:
def fetch_and_clean(url):
# Fetch the content of the URL
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Find the main content of the article, ignoring side boxes and headers
content = soup.find('div', {'class': 'mw-parser-output'})
# Remove less relevant sections such as "See also", "References", etc.
for section_title in ['References', 'Bibliography', 'External links', 'See also']:
section = content.find('span', {'id': section_title})
if section:
for sib in section.parent.find_next_siblings():
sib.decompose()
section.parent.decompose()
# Focus on extracting and cleaning text from paragraph tags only
paragraphs = content.find_all('p')
cleaned_text = ' '.join(paragraph.get_text(separator=' ', strip=True) for paragraph in paragraphs)
cleaned_text = re.sub(r'\[\d+\]', '', cleaned_text) # Remove citation markers like [1], [2], etc.
return cleaned_text
The code fetches the document’s content based on its URL, which is, in turn, based on its label. This straightforward approach may satisfy a project’s needs depending on its goals. An ML engineer or developer must always be careful not to overload a system with costly and unprofitable functions. Moreover, labeling website URLs can guide a retriever pipeline to the correct locations to process data, regardless of the techniques (load balancing, API call optimization, etc.) applied. In the end, each project or sub-project will require one or several techniques, depending on its specific needs.
Once the fetching and cleaning function is ready, we can implement the retrieval process for the user’s input.
1.3. Retrieval process for user input
The first step here involves identifying a keyword within the user’s input. The function process_query takes two parameters: user_input and num_words. The number of words to retrieve is restricted by factors like the input limitations of the model, cost considerations, and overall system performance:
import textwrap
def process_query(user_input, num_words):
user_input = user_input.lower()
# Check for any of the specified keywords in the input
matched_keyword = next((keyword for keyword in urls if keyword in user_input), None)
Upon finding a match between a keyword in the user input and the keywords associated with URLs, the following functions for fetching and cleaning the data are triggered:
if matched_keyword:
print(f"Fetching data from: {urls[matched_keyword]}")
cleaned_text = fetch_and_clean(urls[matched_keyword])
# Limit the display to the specified number of words from the cleaned text
words = cleaned_text.split() # Split the text into words
first_n_words = ' '.join(words[:num_words]) # Join the first n words into a single string
The num_words parameter helps in chunking the text. While this basic approach may work for use cases with a manageable volume of data, it’s recommended to embed the data into vectors for more complex scenarios.
The cleaned and truncated text is then formatted for display:
# Wrap the first n words to 80 characters wide for display
wrapped_text = textwrap.fill(first_n_words, width=80)
print("\nFirst {} words of the cleaned text:".format(num_words))
print(wrapped_text) # Print the first n words as a well-formatted paragraph
# Use the exact same first_n_words for the GPT-4 prompt to ensure consistency
prompt = f"Summarize the following information about {matched_keyword}:\n{first_n_words}"
wrapped_prompt = textwrap.fill(prompt, width=80) # Wrap prompt text
print("\nPrompt for Generator:", wrapped_prompt)
# Return the specified number of words
return first_n_words
else:
print("No relevant keywords found. Please enter a query related to 'LLM', 'LLMs', or 'Prompt Engineering'.")
return None
Note that the function ultimately returns the first n words, providing a concise and relevant snippet of information based on the user’s query. This design allows the system to manage data retrieval efficiently while also maintaining user engagement.
2. Generator
The generator ecosystem contains several components, several of which overlap with the retriever functions and user interfaces in the RAG-driven generative AI frameworks:
- 2.1. Adaptive RAG selection based on human rankings: This will be based on the ratings of a user panel over time. In a real-life pipeline, this functionality could be a separate program.
- 2.2. Input: In a real-life project, a user interface (UI) will manage the input. This interface and the associated process should be carefully designed in collaboration with the users, ideally in a workshop setting where their needs and preferences can be fully understood.
- 2.3. Mean ranking simulation scenario: Calculating the mean value of the user evaluation scores and functionality.
- 2.4. Checking the input before running the generator: Displaying the input.
- 2.5. Installing the generative AI environment: The installation of the generative AI model’s environment, in this case, OpenAI, can be part of another environment in the pipeline in which other team members may be working, implementing, and deploying in production independently of the retriever functionality.
- 2.6. Content generation: In this section of the program, an OpenAI model will process the input and provide a response that will be evaluated by the evaluator.
Let’s begin by describing the adaptive RAG system.
2.1. Integrating HF-RAG for augmented document inputs
The dynamic nature of information retrieval and the necessity for contextually relevant data augmentation in generative AI models require a flexible system capable of adapting to varying levels of input quality. We introduce an adaptive RAG selection system, which employs HF scores to determine the optimal retrieval strategy for document implementation within the RAG ecosystem. Adaptive functionality takes us beyond naïve RAG and constitutes a hybrid RAG system.
Human evaluators assign mean scores ranging from 1 to 5 to assess the relevance and quality of documents. These scores trigger distinct operational modes, as shown in the following figure:
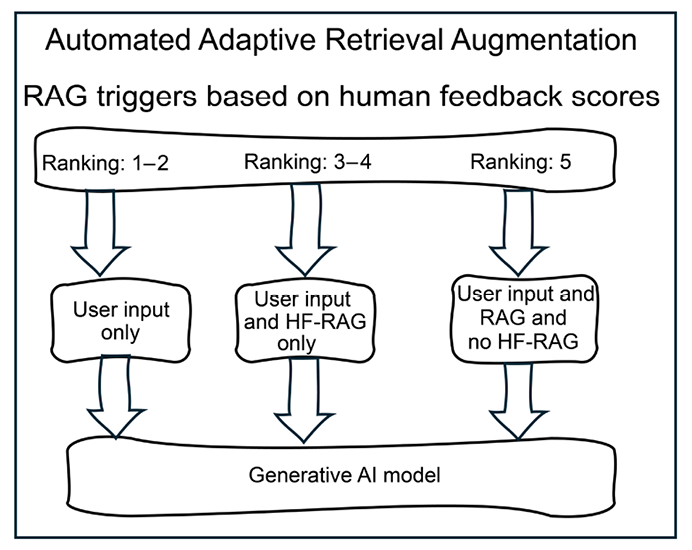
Figure 5.2: Automated RAG triggers
- Scores of 1 to 2 indicate a lack of compensatory capability by the RAG system, suggesting the need for maintenance or possibly model fine-tuning. RAG will be temporarily deactivated until the system is improved. The user input will be processed but there will be no retrieval.
- Scores of 3 to 4 initiate an augmentation with human-expert feedback only, utilizing flashcards or snippets to refine the output. Document-based RAG will be deactivated, but the human-expert feedback data will augment the input.
- Scores of 5 initiate keyword-search RAG enhanced by previously gathered HF when necessary, utilizing flashcards or targeted information snippets to refine the output. The user is not required to provide new feedback in this case.
This program implements one of many scenarios. The scoring system, score levels, and triggers will vary from one project to another, depending on the specification goals to attain. It is recommended to organize workshops with a panel of users to decide how to implement this adaptive RAG system.
This adaptive approach aims to optimize the balance between automated retrieval and human insight, ensuring the generative model’s outputs are of the highest possible relevance and accuracy. Let’s now enter the input.
2.2. Input
A user of Company C is prompted to enter a question:
# Request user input for keyword parsing
user_input = input("Enter your query: ").lower()
In this example and program, we will focus on one question and topic: What is an LLM?. The question appears and is memorized by the model:
Enter your query: What is an LLM?
This program is a proof of concept with a strategy and example for the panel of users in Company C who wish to understand an LLM. Other topics can be added, and the program can be expanded to meet further needs. It is recommended to organize workshops with a panel of users to decide the next steps.
We have prepared the environment and will now activate a RAG scenario.
2.3. Mean ranking simulation scenario
For the sake of this program, let’s assume that the human user feedback panel has been evaluating the hybrid adaptive RAG system for some time with the functions provided in sections 3.2. Human user rating and 3.3. Human-expert evaluation. The user feedback panel ranks the responses a number of times, which automatically updates by calculating the mean of the ratings and storing it in a ranking variable named ranking. The ranking score will help the management team decide whether to downgrade the rank of a document, upgrade it, or suppress documents through manual or automated functions. You can even simulate one of the scenarios described in the section 2.1. Integrating HF-RAG for augmented document inputs.
We will begin with a 1 to 5 ranking, which will deactivate RAG so that we can see the native response of the generative model:
#Select a score between 1 and 5 to run the simulation
ranking=1
Then, we will modify this value to activate RAG without additional human-expert feedback with ranking=5. Finally, we will modify this value to activate human feedback RAG without retrieving documents with ranking=3.
In a real-life environment, these rankings will be triggered automatically with the functionality described in sections 3.2 and 3.3 after user feedback panel workshops are organized to define the system’s expected behavior. If you wish to run the three scenarios described in section 2.1, make sure to initialize the text_input variable that the generative model processes to respond:
# initializing the text for the generative AI model simulations
text_input=[]
Each time you switch scenarios, make sure to come back and reinitialize text_input.
Due to its probabilistic nature, the generative AI model’s output may vary from one run to another.
Let’s go through the three rating categories described in section 2.1.
Ranking 1–2: No RAG
The ranking of the generative AI’s output is very low. All RAG functionality is deactivated until the management team can analyze and improve the system. In this case, text_input is equal to user_input:
if ranking>=1 and ranking<3:
text_input=user_input
The generative AI model, in this case, GPT-4o, will generate the following output in section 2.6. Content generation:
GPT-4 Response:
---------------
It seems like you're asking about "LLM" which stands for "Language Model for Dialogue Applications" or more commonly referred to as a "Large Language Model."
An LLM is a type of artificial intelligence model designed to understand, generate, and interact with human language. These models are trained on vast amounts of text data and use this training to generate text, answer questions, summarize information, translate languages, and perform other language-related tasks. They are a subset of machine learning models known as transformers, which have been revolutionary in the field of natural language processing (NLP).
Examples of LLMs include OpenAI's GPT (Generative Pre-trained Transformer) series and Google's BERT (Bidirectional Encoder Representations from
Transformers).
---------------
This output cannot satisfy the user panel of Company C in this particular use case. They cannot relate this explanation to their customer service issues. Furthermore, many users will not bother going further since they have described their needs to the management team and expect pertinent responses. Let’s see what human-expert feedback RAG can provide.
Ranking 3–4: Human-expert feedback RAG
In this scenario, human-expert feedback (see section 3.4. Human-expert evaluation) was triggered by poor user feedback ratings with automated RAG documents (ranking=5) and without RAG (ranking 1-2). The human-expert panel has filled in a flashcard, which has now been stored as an expert-level RAG document.
The program first checks the ranking and activates HF retrieval:
hf=False
if ranking>3 and ranking<5:
hf=True
The program will then fetch the proper document from an expert panel (selected experts within a corporation) dataset based on keywords, embeddings, or other search methods that fit the goals of a project. In this case, we assume we have found the right flashcard and download it:
if hf==True:
from grequests import download
directory = "Chapter05"
filename = "human_feedback.txt"
download(directory, filename, private_token)
We verify if the file exists and load its content, clean it, store it in content, and assign it to text_input for the GPT-4 model:
if hf==True:
# Check if 'human_feedback.txt' exists
efile = os.path.exists('human_feedback.txt')
if efile:
# Read and clean the file content
with open('human_feedback.txt', 'r') as file:
content = file.read().replace('\n', ' ').replace('#', '') # Removing new line and markdown characters
#print(content) # Uncomment for debugging or maintenance display
text_input=content
print(text_input)
else:
print("File not found")
hf=False
The content of the file explains both what an LLM is and how it can help Company C improve customer support:
A Large Language Model (LLM) is an advanced AI system trained on vast amounts of text data to generate human-like text responses. It understands and generates language based on the patterns and information it has learned during training. LLMs are highly effective in various language-based tasks, including answering questions, making recommendations, and facilitating conversations. They can be continually updated with new information and trained to understand specific domains or industries.For the C-phone series customer support, incorporating an LLM could significantly enhance service quality and efficiency. The conversational agent powered by an LLM can provide instant responses to customer inquiries, reducing wait times and freeing up human agents for more complex issues. It can be programmed to handle common technical questions about the C-phone series, troubleshoot problems, guide users through setup processes, and offer tips for optimizing device performance. Additionally, it can be used to gather customer feedback, providing valuable insights into user experiences and product performance. This feedback can then be used to improve products and services. Furthermore, the LLM can be designed to escalate issues to human agents when necessary, ensuring that customers receive the best possible support at all levels. The agent can also provide personalized recommendations for customers based on their usage patterns and preferences, enhancing user satisfaction and loyalty.
If you now run sections 2.4 and 2.5 once and section 2.6 to generate the content based on this text_input, the response will be satisfactory:
GPT-4 Response:
---------------
A Large Language Model (LLM) is a sophisticated AI system trained on extensive
text data to generate human-like text responses. It understands and generates
language based on patterns and information learned during training. LLMs are
highly effective in various language-based tasks such as answering questions,
making recommendations, and facilitating conversations. They can be continuously updated with new information and trained to understand specific domains or industries. For the C-phone series customer support, incorporating an LLM could significantly enhance service quality and efficiency. The conversational agent powered by an LLM can provide instant responses to customer inquiries, reducing wait times and freeing up human agents for more complex issues.
It can be programmed to handle common technical questions about the C-phone series,
troubleshoot problems, guide users through setup processes, and offer tips for
optimizing device performance. Additionally, it can be used to gather customer
feedback, providing valuable insights into user experiences and product
performance. This feedback can then be used to improve products and services.
Furthermore, the LLM can be designed to escalate issues to human agents when
necessary, ensuring that customers receive the best possible support at all
levels. The agent can also provide personalized recommendations for customers
based on their usage patterns and preferences, enhancing user satisfaction and
loyalty.
---------------
The preceding response is now much better since it defines LLMs and also shows how to improve customer service for Company C’s C-phone series.
We will take this further in Chapter 9, Empowering AI Models: Fine-Tuning RAG Data and Human Feedback, in which we will fine-tune a generative model daily (or as frequently as possible) to improve its responses, thus alleviating the volume of RAG data. But for now, let’s see what the system can achieve without HF but with RAG documents.
Ranking 5: RAG with no human-expert feedback documents
Some users do not require RAG documents that include human-expert RAG flashcards, snippets, or documents. This might be the case, particularly, if software engineers are the users.
In this case, the maximum number of words is limited to 100 to optimize API costs, but can be modified as you wish using the following code:
if ranking>=5:
max_words=100 #Limit: the size of the data we can add to the input
rdata=process_query(user_input,max_words)
print(rdata) # for maintenance if necessary
if rdata:
rdata_clean = rdata.replace('\n', ' ').replace('#', '')
rdata_sentences = rdata_clean.split('. ')
print(rdata)
text_input=rdata
print(text_input)
When we run the generative AI model, a reasonable output is produced that software engineers can relate to their business:
GPT-4 Response:
---------------
A large language model (LLM) is a type of language model known for its
capability to perform general-purpose language generation and other natural language processing tasks such as classification. LLMs develop these abilities by learning statistical relationships from text documents through a computationally intensive training process that includes both self-supervised
and semi-supervised learning. These models can generate text, a form of
generative AI, by taking an input text and repeatedly predicting the next token or word. LLMs are based on artificial neural networks. As of March 2024, the most advanced and capable LLMs are constructed using a decoder-only transformer architecture.
---------------
We can see that the output refers to March 2024 data, although GPT-4-turbo’s training cutoff date was in December 2023, as explained in OpenAI’s documentation: https://platform.openai.com/docs/models/gpt-4-turbo-and-gpt-4.
In production, at the end-user level, the error in the output can come from the data retrieved or the generative AI model. This shows the importance of HF. In this case, this error will hopefully be corrected in the retrieval documents or by the generative AI model. But we left the error in to illustrate that HF is not an option but a necessity.
These temporal RAG augmentations clearly justify the need for RAG-driven generative AI. However, it remains up to the users to decide if these types of outputs are sufficient or require more corporate customization in closed environments, such as within or for a company.
For the remainder of this program, let’s assume ranking>=5 for the next steps to show how the evaluator is implemented in the Evaluator section. Let’s install the generative AI environment to generate content based on the user input and the document retrieved.
2.4.–2.5. Installing the generative AI environment
2.4. Checking the input before running the generator displays the user input and retrieved document before augmenting the input with this information. Then we continue to 2.5. Installing the generative AI environment.
Only run this section once. If you modified the scenario in section 2.3, you can skip this section to run the generative AI model again. This installation is not at the top of this notebook because a project team may choose to run this part of the program in another environment or even another server in production.
It is recommended to separate the retriever and generator functions as much as possible since they might be activated by different programs and possibly at different times. One development team might only work on the retriever functions while another team works on the generator functions.
We first install OpenAI:
!pip install openai==1.40.3
Then, we retrieve the API key. Store your OpenAI key in a safe location. In this case, it is stored on Google Drive:
#API Key
#Store your key in a file and read it(you can type it directly in the notebook but it will be visible for somebody next to you)
from google.colab import drive
drive.mount('/content/drive')
f = open("drive/MyDrive/files/api_key.txt", "r")
API_KEY=f.readline().strip()
f.close()
#The OpenAI Key
import os
import openai
os.environ['OPENAI_API_KEY'] =API_KEY
openai.api_key = os.getenv("OPENAI_API_KEY")
We are now all set for content generation.
2.6. Content generation
To generate content, we first import and set up what we need. We’ve introduced time to measure the speed of the response and have chosen gpt-4o as our conversational model:
import openai
from openai import OpenAI
import time
client = OpenAI()
gptmodel="gpt-4o"
start_time = time.time() # Start timing before the request
We then define a standard Gpt-4o prompt, giving it enough information to respond and leaving the rest up to the model and RAG data:
def call_gpt4_with_full_text(itext):
# Join all lines to form a single string
text_input = '\n'.join(itext)
prompt = f"Please summarize or elaborate on the following content:\n{text_input}"
try:
response = client.chat.completions.create(
model=gptmodel,
messages=[
{"role": "system", "content": "You are an expert Natural Language Processing exercise expert."},
{"role": "assistant", "content": "1.You can explain read the input and answer in detail"},
{"role": "user", "content": prompt}
],
temperature=0.1 # Add the temperature parameter here and other parameters you need
)
return response.choices[0].message.content.strip()
except Exception as e:
return str(e)
The code then formats the output:
import textwrap
def print_formatted_response(response):
# Define the width for wrapping the text
wrapper = textwrap.TextWrapper(width=80) # Set to 80 columns wide, but adjust as needed
wrapped_text = wrapper.fill(text=response)
# Print the formatted response with a header and footer
print("GPT-4 Response:")
print("---------------")
print(wrapped_text)
print("---------------\n")
# Assuming 'gpt4_response' contains the response from the previous GPT-4 call
print_formatted_response(gpt4_response)
The response is satisfactory in this case, as we saw in section 2.3. In the ranking=5 scenario, which is the one we are now evaluating, we get the following output:
GPT-4 Response:
---------------
GPT-4 Response:
---------------
### Summary: A large language model (LLM) is a computational model known for its ability to perform general-purpose language generation and other natural language processing tasks, such as classification. LLMs acquire these abilities by learning statistical relationships from vast amounts of text during a computationally intensive self-supervised and semi-supervised training process.They can be used for text generation, a form of generative AI, by taking input text and repeatedly predicting the next token or word. LLMs are artificial neural networks that use the transformer architecture…
The response looks fine, but is it really accurate? Let’s run the evaluator to find out.
3. Evaluator
Depending on each project’s specifications and needs, we can implement as many mathematical and human evaluation functions as necessary. In this section, we will implement two automatic metrics: response time and cosine similarity score. We will then implement two interactive evaluation functions: human user rating and human-expert evaluation.
3.1. Response time
The response time was calculated and displayed in the API call with:
import time
…
start_time = time.time() # Start timing before the request
…
response_time = time.time() - start_time # Measure response time
print(f"Response Time: {response_time:.2f} seconds") # Print response time
In this case, we can display the response time without further development:
print(f"Response Time: {response_time:.2f} seconds") # Print response time
The output will vary depending on internet connectivity and the capacity of OpenAI’s servers. In this case, the output is:
Response Time: 7.88 seconds
It seems long, but online conversational agents take some time to answer as well. Deciding if this performance is sufficient remains a management decision. Let’s run the cosine similarity score next.
3.2. Cosine similarity score
Cosine similarity measures the cosine of the angle between two non-zero vectors. In the context of text analysis, these vectors are typically TF-IDF (Term Frequency-Inverse Document Frequency) representations of the text, which weigh terms based on their importance relative to the document and a corpus.
GPT-4o’s input, which is text_input, and the model’s response, which is gpt4_response, are treated by TF-IDF as two separate “documents.” The vectorizer transforms the documents into vectors. Then, vectorization considers how terms are shared and emphasized between the input and the response with the vectorizer.fit_transform([text1, text2]).
The goal is to quantify the thematic and lexical overlap through the following function:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def calculate_cosine_similarity(text1, text2):
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform([text1, text2])
similarity = cosine_similarity(tfidf[0:1], tfidf[1:2])
return similarity[0][0]
# Example usage with your existing functions
similarity_score = calculate_cosine_similarity(text_input, gpt4_response)
print(f"Cosine Similarity Score: {similarity_score:.3f}")
Cosine similarity relies on TfidfVectorizer to transform the two documents into TF-IDF vectors. The cosine_similarity function then calculates the similarity between these vectors. A result of 1 indicates identical texts, while 0 shows no similarity. The output of the function is:
Cosine Similarity Score: 0.697
The score shows a strong similarity between the input and the output of the model. But how will a human user rate this response? Let’s find out.
3.3. Human user rating
The human user rating interface provides human user feedback. As reiterated throughout this chapter, I recommend designing this interface and process after fully understanding user needs through a workshop with them. In this section, we will assume that the human user panel is a group of software developers testing the system.
The code begins with the interface’s parameters:
# Score parameters
counter=20 # number of feedback queries
score_history=30 # human feedback
threshold=4 # minimum rankings to trigger human expert feedback
In this simulation, the parameters show that the system has computed human feedback:
counter=20shows the number of ratings already entered by the usersscore_history=60shows the total score of the 20 ratingsthreshold=4states the minimum mean rating,score_history/counter, to obtain without triggering a human-expert feedback request
We will now run the interface to add an instance to these parameters. The provided Python code defines the evaluate_response function, designed to assess the relevance and coherence of responses generated by a language model such as GPT-4. Users rate the generated text on a scale from 1 (poor) to 5 (excellent), with the function ensuring valid input through recursive checks. The code calculates statistical metrics like mean scores to gauge the model’s performance over multiple evaluations.
The evaluation function is a straightforward feedback request to obtain values between 1 and 5:
import numpy as np
def evaluate_response(response):
print("\nGenerated Response:")
print(response)
print("\nPlease evaluate the response based on the following criteria:")
print("1 - Poor, 2 - Fair, 3 - Good, 4 - Very Good, 5 - Excellent")
score = input("Enter the relevance and coherence score (1-5): ")
try:
score = int(score)
if 1 <= score <= 5:
return score
else:
print("Invalid score. Please enter a number between 1 and 5.")
return evaluate_response(response) # Recursive call if the input is invalid
except ValueError:
print("Invalid input. Please enter a numerical value.")
return evaluate_response(response) # Recursive call if the input is invalid
We then call the function:
score = evaluate_response(gpt4_response)
print("Evaluator Score:", score)
The function first displays the response, as shown in the following excerpt:
Generated Response:
### Summary:
A large language model (LLM) is a computational model…
Then, the user enters an evaluation score between 1 and 5, which is 1 in this case:
Please evaluate the response based on the following criteria:
1 - Poor, 2 - Fair, 3 - Good, 4 - Very Good, 5 - Excellent
Enter the relevance and coherence score (1-5): 3
The code then computes the statistics:
counter+=1
score_history+=score
mean_score=round(np.mean(score_history/counter), 2)
if counter>0:
print("Rankings :", counter)
print("Score history : ", mean_score)
The output shows a relatively very low rating:
Evaluator Score: 3
Rankings : 21
Score history : 3.0
The evaluator score is 3, the overall ranking is 3, and the score history is 3 also! Yet, the cosine similarity was positive. The human-expert evaluation request will be triggered because we set the threshold to 4:
threshold=4
What’s going on? Let’s ask an expert and find out!
3.4. Human-expert evaluation
Metrics such as cosine similarity indeed measure similarity but not in-depth accuracy. Time performance will not determine the accuracy of a response either. But if the rating is too low, why is that? Because the user is not satisfied with the response!
The code first downloads thumbs-up and thumbs-down images for the human-expert user:
from grequests import download
# Define your variables
directory = "commons"
filename = "thumbs_up.png"
download(directory, filename, private_token)
# Define your variables
directory = "commons"
filename = "thumbs_down.png"
download(directory, filename, private_token)
The parameters to trigger an expert’s feedback are counter_threshold and score_threshold. The number of user ratings must exceed the expert’s threshold counter, which is counter_threshold=10. The threshold of the mean score of the ratings is 4 in this scenario: score_threshold=4. We can now simulate the triggering of an expert feedback request:
if counter>counter_threshold and score_history<=score_threshold:
print("Human expert evaluation is required for the feedback loop.")
In this case, the output will confirm the expert feedback loop because of the poor mean ratings and the number of times the users rated the response:
Human expert evaluation is required for the feedback loop.
As mentioned, in a real-life project, a workshop with expert users should be organized to define the interface. In this case, a standard HTML interface in a Python cell will display the thumbs-up and thumbs-down icons. If the expert presses on the thumbs-down icon, a feedback snippet can be entered and saved in a feedback file named expert_feedback.txt, as shown in the following excerpt of the code:
import base64
from google.colab import output
from IPython.display import display, HTML
def image_to_data_uri(file_path):
"""
Convert an image to a data URI.
"""
with open(file_path, 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode()
return f'data:image/png;base64,{encoded_string}'
thumbs_up_data_uri = image_to_data_uri('/content/thumbs_up.png')
thumbs_down_data_uri = image_to_data_uri('/content/thumbs_down.png')
def display_icons():
# Define the HTML content with the two clickable images
…/…
def save_feedback(feedback):
with open('/content/expert_feedback.txt', 'w') as f:
f.write(feedback)
print("Feedback saved successfully.")
# Register the callback
output.register_callback('notebook.save_feedback', save_feedback)
print("Human Expert Adaptive RAG activated")
# Display the icons with click handlers
display_icons()
The code will display the icons shown in the following figure. If the expert user presses the thumbs-down icon, they will be prompted to enter feedback.
Figure 5.3: Feedback icons
You can add a function for thumbs-down meaning that the response was incorrect and that the management team has to communicate with the user panel or add a prompt to the user feedback interface. This is a management decision, of course. In our scenario, the human expert pressed the thumbs-down icon and was prompted to enter a response:
Figure 5.4: “Enter feedback” prompt
The human expert provided the response, which was saved in '/content/expert_feedback.txt'. Through this, we have finally discovered the inaccuracy, which is in the content of the file displayed in the following cell:
There is an inaccurate statement in the text:
"As of March 2024, the largest and most capable LLMs are built with a decoder-only transformer-based architecture."
This statement is not accurate because the largest and most capable Large Language Models, such as Meta's Llama models, have a transformer-based architecture, but they are not "decoder-only." These models use the architecture of the transformer, which includes both encoder and decoder components.
The preceding expert’s feedback can then be used to improve the RAG dataset. With this, we have explored the depths of HF-RAG interactions. Let’s summarize our journey and move on to the next steps.


